本文主要是介绍R语言用AR,MA,ARIMA 模型进行时间序列预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于ARIMA 的研究报告,包括一些图形和统计输出。
相关视频:在Python和R语言中建立EWMA,ARIMA模型预测时间序列
本文讨论用ARIMA模型进行预测。考虑一些简单的平稳的AR(1)模拟时间序列
> for(t in 2:n) X[t]=phi*X[t-1]+E[t]
> plot(X,type="l")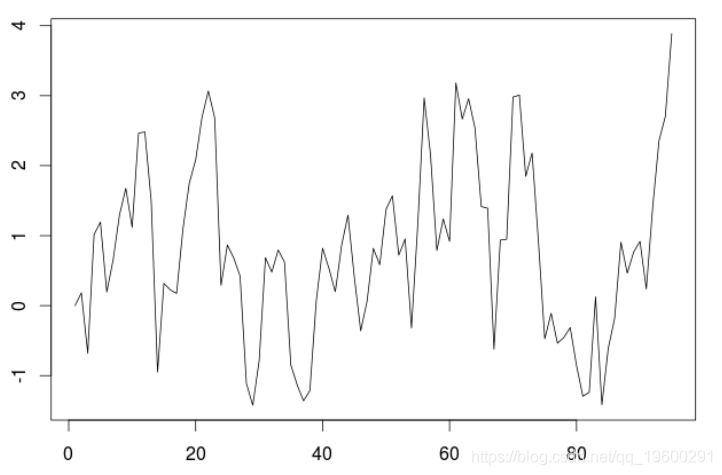
如果我们拟合一个AR(1)模型。
arima(X,order=c(1,0,0),
+ include.mean = FALSE)
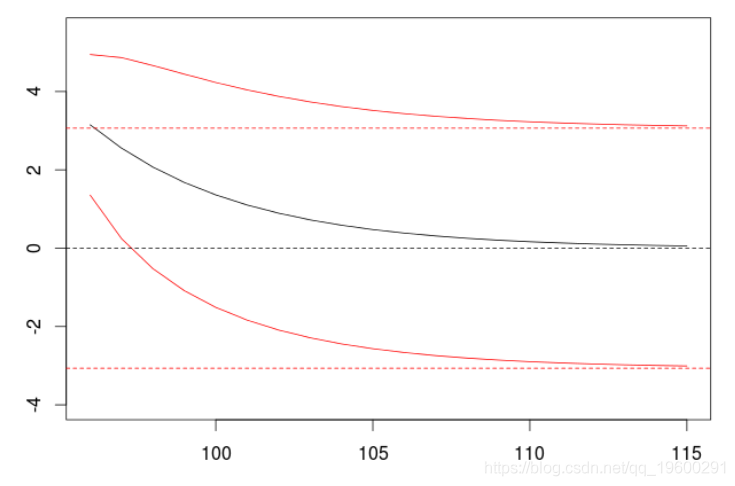
我们观察到预测值向0的指数衰减,以及增加的置信区间(其中方差增加,从白噪声的方差到平稳时间序列的方差)。普通线是有条件的预测(因为AR(1)是一个一阶马尔可夫过程),虚线是无条件的。让我们存储一些数值,把它们作为基准。
如果我们拟合一个MA(1)模型
> P=predict(model,n.ahead=20)
> plot(P$pred)
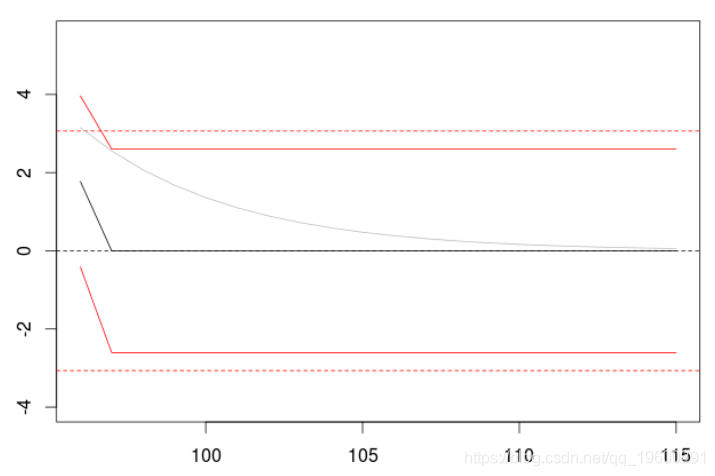
在两个滞后期之后,预测是无效的,而且(条件)方差保持不变。但如果我们考虑一个具有较长阶数的移动平均过程。
> P=predict(model,n.ahead=20)
> plot(P$pred)
>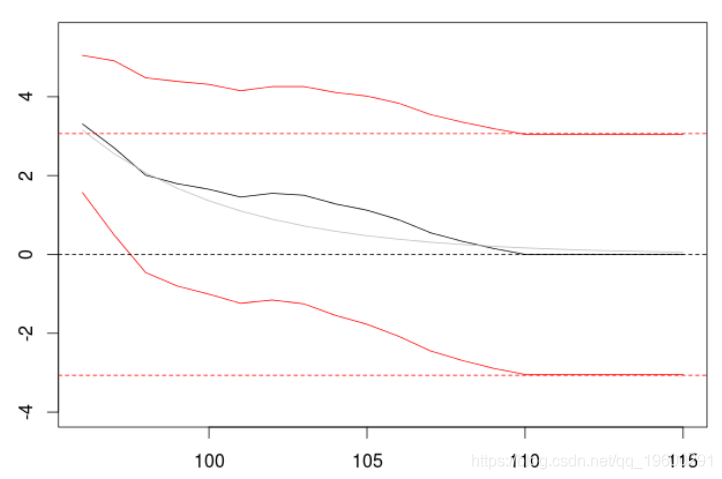
我们得到一个可以与AR(1)过程相比较的输出。因为我们的AR(1)过程也可以被看作是一个具有无限阶数的MA(∞)。
但是,如果我们认为时间序列不是平稳的,那么我们就拟合一个arima模型
> model=arima(X,order=c(0,1,0),
+ include.mean = FALSE)
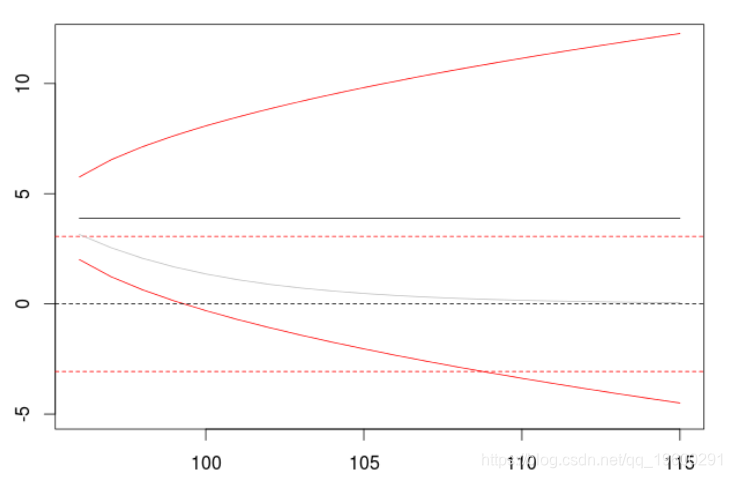
我们观察到:预测是平稳的,置信区间不断增加,实际上,方差向无穷大增加(以线性速度)。因此,在区分一个时间序列时应该非常小心,它将对预测产生巨大影响。

这篇关于R语言用AR,MA,ARIMA 模型进行时间序列预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





