本文主要是介绍MyDLNote-Enhancment : 基于解耦特征表示的混合失真图像修复算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Learning Disentangled Feature Representation for Hybrid-distorted Image Restoration

【paper】:https://arxiv.org/pdf/2007.11430v1.pdf
目录
Learning Disentangled Feature Representation for Hybrid-distorted Image Restoration
Abstract
Introduction
Related Work
Image Restoration on Hybrid Distortion
Approach
Primary Knowledge
Feature Disentanglement Module
Feature aggregation Module
Auxiliary Module
Overview of Whole Framework
Loss Function
Experiments
Dataset
Comparison with State-of-the-Arts
Interpretative Experiment
Ablation Studies
Abstract
Hybrid-distorted image restoration (HD-IR) is dedicated to restore real distorted image that is degraded by multiple distortions. Existing HD-IR approaches usually ignore the inherent interference among hybrid distortions which compromises the restoration performance.
研究方向:Hybrid-distorted image restoration 这个任务是干啥的;
motivation:现有的 HD-IR 方法通常忽略了混合失真的内在干扰,从而影响了恢复性能。
To decompose such interference, we introduce the concept of Disentangled Feature Learning to achieve the feature-level divide-and-conquer of hybrid distortions.
Specifically, we propose the feature disentanglement module (FDM) to distribute feature representations of different distortions into different channels by revising gain-control-based normalization. We also propose a feature aggregation module (FAM) with channel-wise attention to adaptively filter out the distortion representations and aggregate useful content information from different channels for the construction of raw image.
策略:为了分解这种干扰,引入了解耦特征学习的概念来实现混合失真的特征级分而治之。
方法:1. feature disentanglement module (FDM):特征解耦模块,通过修正增益控制归一化,将不同畸变的特征表示分布到不同的信道中;
2. feature aggregation module (FAM):特征聚合模块(结合通道注意力模型),自适应地滤除失真表示,并从不同的通道中聚合有用的内容信息来构造原始图像。
The effectiveness of the proposed scheme is verified by visualizing the correlation matrix of features and channel responses of different distortions.
Extensive experimental results also prove superior performance of our approach compared with the latest HD-IR schemes.
实验结论:通过对不同畸变特征和通道响应的相关矩阵的可视化验证了该方法的有效性。
大量的实验结果也证明了本文的方法优于最新的 HD-IR 方案。
Introduction
还是那句话,Introduction 是一个倒三角!从大到小;从一般到具体的过程。应当注意几点:1. 大的部分可以用几句话就概况,不用大段说明(大背景一般就几句话,一般第一段就将大的背景缩小到文章的主要研究领域;然后再用第二段缩小到文章的具体研究内容和问题);2. 从大到小衔接连贯。
Nowadays, Image restoration techniques have been applied in various fields, including streaming media, photo processing, video surveillance, and cloud storage, etc. In the process of image acquisition and transmission, raw images are usually contaminated with various distortions due to capturing devices, high ratio compression, transmission, post-processing, etc.
Previous image restoration methods focusing on single distortion have been extensively studied [5,12,36,25,14,6,27,17,18,35] and achieved satisfactory performance on the field of super resolution [22,7,21] , deblurring [30,24,38], denoising [4,43,44], deraining [10,9,34], dehazing [45,1,41] and so on.
However, these works are usually designed for solving one specific distortion, which makes them difficult to be applied to real world applications as shown in Fig. 13.
Fig. 1. Examples of hybrid-distorted image restoration. (I) Hybrid-distorted image including noise, blur, and jpeg artifacts. (II) Processed with the cascading single distortion restoration networks including dejpeg, denoise and deblurring. (III)Processed with our FDR-Net.

故事开篇,通过介绍图像处理的简单背景,引出了本文的重要议题,即:
真实图像从采集到传输,会遇到各种各样的污染。
传统的方法只考虑单一污染处理。
这些方法无法适应于真实图像 混合污染 的现实情况。
{ 这段是大方向的问题,后面将讲述一个跟为细节的问题,也是本文不同于其它 HI-IR 方法的独到之处。}
Real world images are typically affected by multiple distortions simultaneously. In addition, different distortions might be interfered with each other, which makes it difficult to restore images. More details about interference between different distortions can be seen in the supplementary material.
Recently, there have been proposed some pioneering works for hybrid distortion. For example, Yu et al. [37] pre-train several light-weight CNNs as tools for different distortions. Then they utilize the Reinforcement Learning (RL) agent to learn to choose the best tool-chain for unknown hybrid distortions. Then Suganuma et al. [28] propose to use the attention mechanism to implement the adaptive selection of different operations for hybrid distortions.
However, these methods are designed regardless of the interference between hybrid distortions.
本段进一步缩小研究问题,将研究内容聚焦在一个更具体的问题上,即:
不同的失真可能会相互干扰;
现有的方法采用强化学习和注意力机制;
然而,这些方法的设计不考虑混合畸变之间的干扰。
Yu et al. [37] Crafting a toolchain for image restoration by deep reinforcement learning 2018 CVPR
Suganuma et al. [28] Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions 2019 CVPR ; CSDN 博客:MyDLNote
Previous literature [2] suggests that deep feature representations could be employed to efficiently characterize various image distortions. In other words, the feature representation extracted from hybrid distortions images might be disentangled to characterize different distortions respectively. Based on the above, we propose to implement the feature-level divide-and-conquer of the hybrid distortions by learning disentangled feature representations.
On a separate note, Schwartz et al. [26] point out that a series of filters and gain-control-based normalization could achieve the decomposition of different filter responses. And the convolution layer of CNN is also composed of a series of basic filters/kernels. Inspired by this, we expand this theory and design a feature disentanglement module (FDM) to implement the channel-wise feature decorrelation.
By such feature decorrelation, the feature representations of different distortions could be distributed across different channels respectively as shown in Fig. 2.
Fig. 2. Illustration of feature disentangle module (FDM) works. The FDM disentangles the input feature representation which characterizes the hybrid-distorted image into disentangled features. The responses of different distortions are distributed across different channels as shown in brighter region. The visualizations of distortions are also displayed.
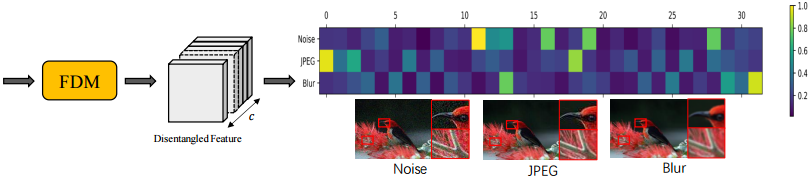
此时 Introduction 倒三角已经到底了,开始介绍一下针对上述具体问题,本文的采用的策略或方法。
为了解决上段提出的具体问题,本文的策略是使用解耦表示。但在这之前,还有考虑一下合理性。
为了说明合理性,作者从两个方面加以论证。
1. 解释不通失真的特征可以被分解出来:之前的文献 [2] 表明,深度特征表示可以有效地表征各种图像畸变。也就是说,可以对混合失真图像提取的特征表示进行分解,分别表征不同的失真。
2. 解释分解手段:Schwartz等 [26] 指出,一系列滤波器和基于增益控制的归一化可以实现对不同滤波器响应的分解。而 CNN 的卷积层也是由一系列基本滤波器 / kernel 组成的。受此启发,设计了一个特征解耦模块 (FDM) 来实现信道方向上的特征解耦。
通过这种特征去关系,可以将不同失真的特征表示分别分布在不同的通道上,如图2所示。
err,后面两段分别说明了一下实验结论和本文贡献。这里略过。
[2] Disentangling image distortions in deep feature space 2020
Schwartz et al. [26] Natural signal statistics and sensory gain control 2001 Nature neuroscience
Related Work
Image Restoration on Hybrid Distortion
Recently, with the wide applications of image restoration, the special image restoration on single distortion cannot meet the need of real world application. Then, some works on hybrid distortion restoration have been proposed. Among them, RL-Restore [37] trains a policy to select the appropriate tools for single distortion from the pre-trained toolbox to restore the hybrid-distorted image. Then Suganuma et al. [28] propose a simple framework which can select the proper operation with attention mechanism. However, these works don’t consider the interference between different distortions. In this paper, we propose the FDR-Net for hybrid distortions image restoration by reducing the interference with feature disentanglement, which achieves more superior performance by disentangling the feature representation for hybird-distorted image restoration.
在 Related Work 里,不是简单的罗列一堆顶会顶刊文献,而是要说明一些文献与本文之间的关系,可以说是理论基础(本文是在某些文献提供的理论基础上发展而来的),可以是继承关系(本文是对某个方法的进一步高水平改进,解决了某个方法存在的问题),也可以是对比关系(之前的方法不能实现什么功能,本文提出的方法可以实现)。这些方法,是本文提出 motivation 的重要线索、依据或者是 理论基础。
总之,要和 motivation 搭上才行。否则,与本文核心内容无关的文献,即使是大牛巨作,也不该引用。
Approach
Primary Knowledge
To derive the models of sensory processing, gain-control-based normalization has been proposed to implement the nonlinear decomposition of natural signals [26]. Given a set of signals X, the signal decomposition first uses a set of filters <f1, f2, ..., fn> to extract different representations of signals <L1, L2, ...Ln> as
(2)
and then uses gain-control-based normalizaiton as Eq. 2 to further eliminate the dependency between <L1, L2, ...Ln>.
where independent response Ri can be generated based on the suitable weights
and offsets
with corresponding inputs Li. In this way, the input signals X can be decomposed into R1, R2, ...Rn according to their statistical property.
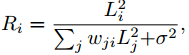
本节介绍了一个重要方法,gain-control-based normalization。目的是将输入信号 X 分解为 R1, R2, ...Rn,消除之间的依赖关系
Feature Disentanglement Module
Previous literature [2] has proved that different distortions have different deep feature representation and could be disentangled at feature representation. Based on this analysis, we design the FDM by expanding the signal decomposition into channel-wise feature disentanglement to reduce the interference between hybrid distortions.
As shown in [26], the combination of diverse linear filters and divisive normalization has the capability to decompose the responses of filters. And the feature representation of CNN is also composed of responses from a series of basic filters/kernels. Based on such observation, we implement the adaptive channel-wise feature decomposition by applying such algorithm in learning based framework.
本文的特征解耦,是建立在两个理论基础(知识)之上的。
第一,前的文献[2]已经证明了不同的畸变有不同的深层特征表示,可以从特征表示中解出。
第二,不同线性滤波器与分裂归一化相结合,具有对滤波器响应进行分解的能力。而 CNN 的 feature representation 也是由一系列基本 filter /kernel 的响应组成。
有了这些基础,本文的特征解耦模型才得以成立。
Specifically, we use the convolution layer (Cin ×Cout×k×k) in neural network to replace traditional filters <f1, f2, ..., fn> in signal decomposition as section 3.1. Here, the number of input channel Cin represents the channel dimension of input feature Fin, the number of output channel Cout represents the channel dimension of output feature Fout, and k is the kernel size of filters. In this way, the extraction results
of convolution layer will be distributed in different channels as:
(3)
where
represents the ith channel in output feature and conv represents the convolution layer.
To introduce the gain-control-based normalization as Eq. 2 into CNN, we modified the Eq. 2 as Eq. 4.
(4)
where
can be learned by gradient descent. Si and Di represent the ith channel components of features before and after gain control.
In formula 4, we make two major improvements to make it applicable to our task. One improvement is that the denominator and numerator is the square root of the original one in Eq. 2 which makes it is easy to implement the gradient propagation. Another improvement is to replace the response of filters Li with channel components of features Si , which is proper for channel-wise feature disentanglement.
In order to guide the study of parameters from convolution layer,
(5)
where
and
denote the largest and smallest eigenvalues of
, respectively. F is feature maps and T expresses the transposition.
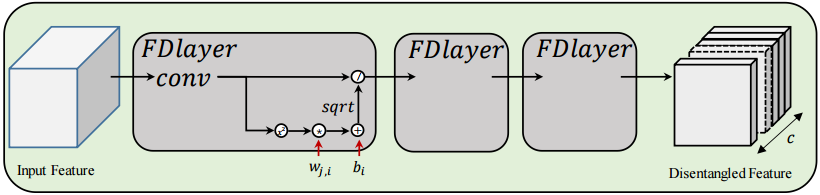
具体地,本文的特征解耦模型是:
1. 对输入特征做卷积操作;输出为 ;
2. 对 做公式(2)的 gain-control-based normalization 操作;输出为
;
(注意:公式(4)和公式(2)有两个不同:一是(4)的分母做了开平方,易于反向传播;另一个改进是用特征 Si 的通道分量代替滤波器 Li 的响应,这适合于通道方向的特征解耦。)
3. 训练时,引入了 谱值差正交正则化 spectral value difference orthogonality regularization (SVDO) 作为损失函数。
Feature aggregation Module
To further filter out the distortion representation and maintain the raw image content details, we utilize channelwise attention mechanism to adaptively select useful feature representation from processed disentangled feature as Eq. 6.
(6)
where PM represents the process module and CA presents channel attention. Di is the ith channel of disentangled feature. Fp i represents the ith channel of output feature.
To construct the image, we get the inversion formula from Eq. 4 as:
(7)
where Fc i represents the output feature corresponding to the distribution of clean image.
With this module, the processed image information could be aggregated to original feature space, which is proper for reconstructing restored image. Feature aggregation module (FAM) is designed as shown in Fig. 4
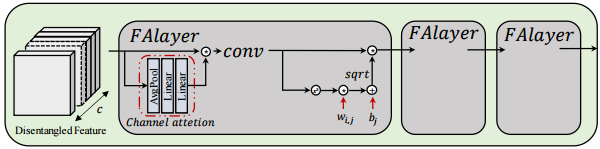
特征聚合模块包括两个步骤:
1. 通道注意力模型用于选择有用通道;
2. gain-control-based normalization 的逆变换;目的是,可以将处理后的图像信息聚合到原始特征空间中,适合重建恢复后的图像。
Auxiliary Module
In the processes of feature disentanglement, the mutual information of different channels of features is reduced, which will result in some loss of image information. In order to make up for the weakness of the feature disentanglement branch, we used the existing ResBlock to enhance the transmission of image information in parallel.
作者认为,在特征解耦的过程中,减少了不同通道特征之间的相互信息,会造成图像信息的一定损失。
为了弥补特征解纠缠分支的不足,用 ResBlock 作为并行路径,来增强图像信息的传输。
Overview of Whole Framework
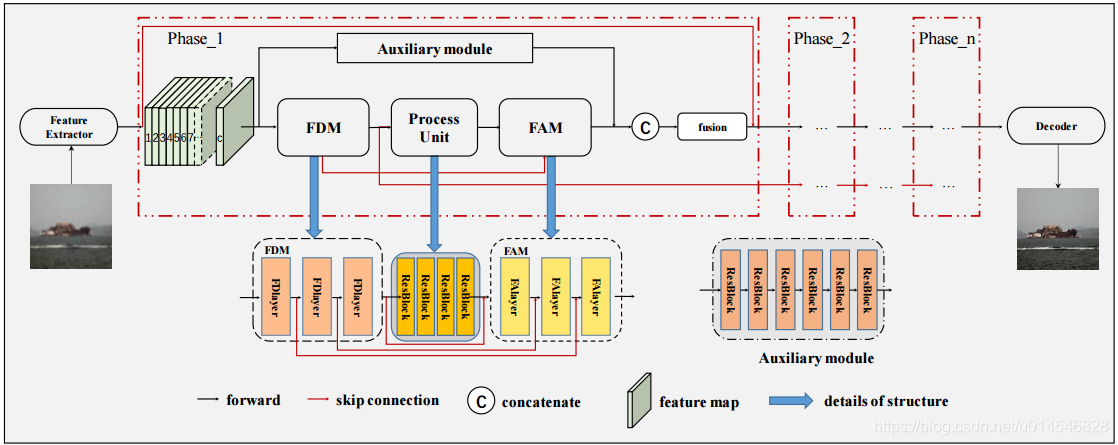
注意几点:
1. FDM 和 FAM 之间有若干 ResNet Block;
2. FDM 和 FAM 之间是有跳接的,像 U-Net 那样的跳接;
3. multi-phases,即多个阶段。
4. 利用双残差将不同相位联系起来,增强了不同相位之间信息的相互利用。(注意到,Phase 1 上面还有一条红色的 skip connection;FDM 后面还有一个 skip connection)。
Loss Function
L1 loss and feature orthogonality loss
![]()
β = 0.00001 !意不意外,或许 特性的正交性损失 本身值很大?
Experiments
Dataset
对于混合失真图像训练和测试的数据集:
DIV2K dataset:
1. 750 张训练;50 张测试;当然不会这么少,每张图片切成 patches of size 63 ×63,这样一共有 249344 训练,3584 测试;
2. 这些图片要人工加入 Gaussian noise, Gaussian blur, and JPEG compression artifacts。各参数:
The standard deviations of Gaussian blur and Gaussian noise are randomly chosen from the range of [0, 10] and [0, 50];
The quality of JPEG compression is chosen from [10, 100]。
但是这些图分辨率不高,所以又引入了一些 DID-HY 数据集的图。
DID-HY dataset : is built by adding Gaussian blur, Gaussian noise and JPEG compression artifacts based on DID-MDN dataset
The training set contains 12, 000 distortion/clean image pairs, which have resolutions of 512 × 512. And the testing set contains 1, 200 distorted/clean image pairs.
还有一个非常重要的问题就是,如果真实图像确实只受到一种干扰,本文的 混合失真图像 复原算法,对这特定的失真图像复原效果,是否会好于 单一失真图像复原算法呢?这个考察非常重要!
所以,文章还在单一失真图像数据集上做测试实验,数据集包括:
Gopro dataset for Deblurring. As the standard dataset for image deblurring, GOPRO datast is produced by [14], which contains 3214 blurry/clean image pairs. The training set and testing set consists of 2103 pairs and 1111 pairs respectively.
DID-MDN Dataset for Deraining. The DID-MDN dataset is produced by [40]. Its training dataset consists of 12000 rain/clean image pairs which are classified to three level (light, medium, and heavy) based on its rain density. There are 4000 image pairs per level in the dataset. The testing dataset consists of 1200 images, which contains rain streaks with different orientations and scales.
Comparison with State-of-the-Arts
先看一下在混合失真图像算法上的效果。
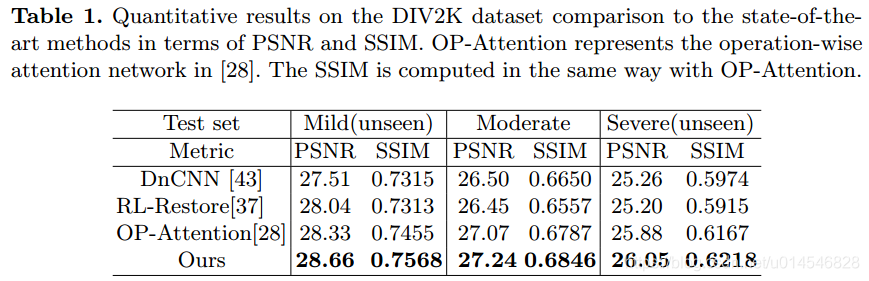
- 1. DIV2K dataset.
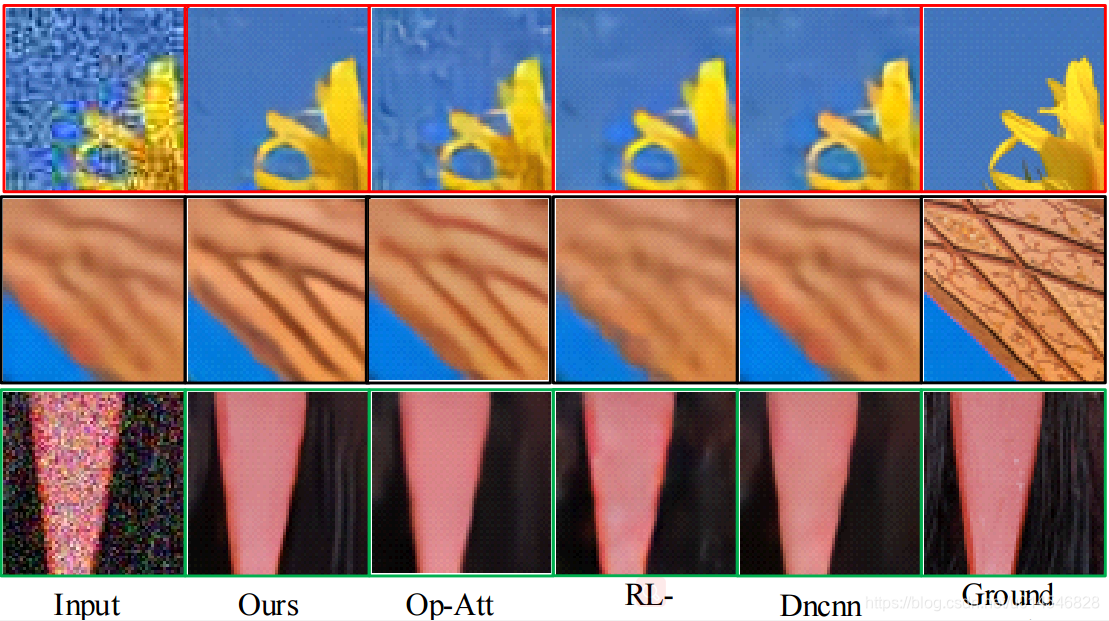
- 2. DID-HY dataset


err,毫无悬念,在两个数据集上,肯定是本文的方法最好。
再看看在单一失真图像上的效果。
- 1. Gopro-test dataset : deblurring


- 2. DID-MDN dataset : deraining


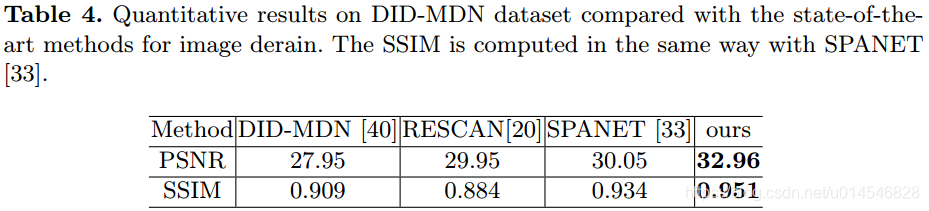
err, 毫无意外,本文的方法还是最好的效果。
也就是说,虽然本文是解决混合失真图像复原;但当这个混合中,只有一个时,该方法效果也是可以的。这是一个非常重要的结论。
Interpretative Experiment
Fig. 8. (a)Visualization of correlation matrix between channels from the feature before FDM. (b) Visualization of correlation matrix between channels from feature after FDM. (c) Channels responses corresponding to different distortion types after FDM. As shown in (a)(b), FDM reduces the channel-wise correlations by disentangling the feature. From (c), the different distortions are distributed in different channels regardless of the levels of distortion by feature disentanglement.
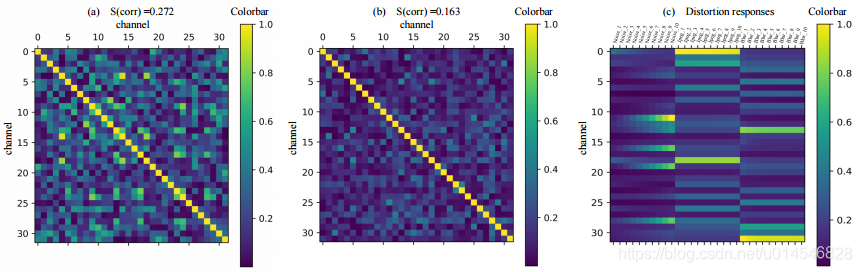
本文还做了一个非常重要的解释实验。
(a) FDM 前特征的通道间相关矩阵可视化
(b) FDM 后特征通道间相关矩阵的可视化
(c) FDM 后不同失真类型对应的通道响应
对比 (a) 和 (b),说明了FDM通过分离特征来减少信道相关
(c) 说明了:不管失真程度如何,不同种类的畸变有不同的通道响应,这意味着畸变通过特征解耦在不同的通道上进行了划分。此外,不同的失真程度只会带来响应强度的变化。
Ablation Studies
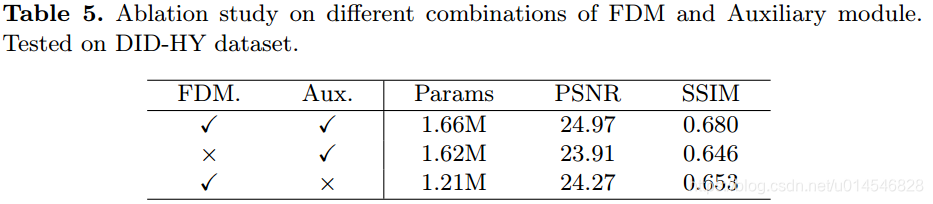
- FDM 和 辅助分支(ResNet Blocks 分支)的作用:
- FDlayers (就是在 FDM 模块中,重复多少次 FD 层,看图 2;FAlayers 同理,看图 3)和 通道数的作用:

可以看到, FDlayer 选择 3 即可;通道数虽然越多越好,但本文还是考虑模型大小,选择了 32。
- Multi-phases 的作用
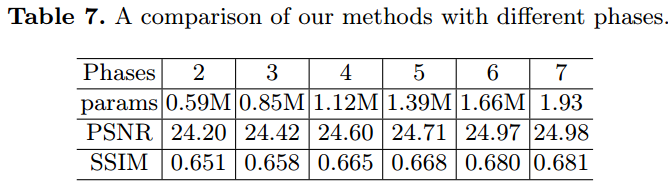
越多越好;还是选了 6。
这篇关于MyDLNote-Enhancment : 基于解耦特征表示的混合失真图像修复算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









