本文主要是介绍Cumulative Reasoning With Large Language Models翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
虽然语言模型功能强大且用途广泛,但它们通常无法解决高度复杂的问题。这是因为解决复杂问题需要深思熟虑,而在训练过程中只得到了最低限度的指导。在本文中,我们提出了一种称为Cumulative Reasoning (CR) 的新方法,它以累积和迭代的方式使用语言模型来模拟人类思维过程。通过将任务分解为更小的组件,CR 简化了问题解决过程,使其更易于管理和有效。对于逻辑推理任务,CR 始终优于现有方法,提升高达 9.3%,并在精选的 FOLIO wiki 数据集上实现了 98.04% 的惊人准确率。在 24 字游戏下,CR 的准确率达到了 98%,这意味着比之前最先进的方法大幅提高了 24%。最后,在 MATH 数据集上,我们建立了新的SOTA结果,总体准确率达到 58.0%,超出了之前的最佳方法 4.2%,并且在最难的 level-5 问题上实现了 43% 的相对改进(22.4 % → 32.1%)。
1.介绍
尽管大型语言模型(LLM)在各种应用中取得了显着的进步,但在面对高度复杂的任务时,它们仍然难以提供稳定和准确的答案。例如,据观察,语言模型很难直接生成高中数学问题的正确答案。
考虑到LLM所采用的训练方法,这种不足是可以预见的。具体来说,他们被训练为根据给定的上下文顺序预测下一个token,而不会暂停进行思考。正如 Kahneman (2011) 所阐明的,我们的认知处理过程由两个不同的系统组成:System 1是快速的、本能的和情感的;系统2是缓慢的、深思熟虑的、合乎逻辑的。目前,LLM与系统 1 更加紧密地结合在一起,从而可能解释了它们在应对复杂任务时的局限性。
为了应对这些限制,已经提出了几种模拟人类认知过程的方法。其中包括提示模型提供逐步解决方案的思想链 (CoT),以及将求解过程建模为思维搜索树的思维树 (ToT)。此外,还创建了专用数据集来为模型训练提供逐步指导。然而,这些方法没有一个存储中间结果的场所,假设所有的想法形成一条链或一棵树,这并不能完全捕捉人类的思维过程。
在本文中,我们提出了一种称为Cumulative Reasoning (CR) 的新方法,它将思维过程表现为更一般的特征。CR 采用三个不同的LLM:proposer、verifier和reporter。proposer不断提出潜在的提议,并由一名或多名verifier验证,reporter决定何时停止并报告解决方案。
CR 显着增强了语言模型处理复杂任务的能力,这是通过将每个任务分解为原子且可管理的步骤来实现的。 尽管枚举数量呈指数级增长的可能的复杂任务在计算上不可行,但 CR 确保每个单独的步骤都可以被有效地学习和解决。 这种策略分解有效地将原本难以管理的指数问题转化为一系列可解决的任务,从而为原始问题提供了稳健的解决方案。
我们的分析包括三个组成部分。在第一个实验中,我们解决了 FOLIO wiki(与一阶逻辑相关)和 AutoTNLI(与高阶逻辑相关)等逻辑推理任务。在这些数据集上,CR 始终超越当前的方法,显示出高达 9.3% 的增强。此外,对 FOLIO 数据集的严格细化得到了“FOLIO wiki curated”数据集,CR 的准确率高达 98.04%。在围绕 24 字游戏进行的第二个实验中,CR 的准确率达到了 98%。值得注意的是,与之前SOTA的方法 ToT 相比,显着提高了 24%。在最后一个实验中,我们在著名的 MATH 数据集上建立了新的SOTA结果,总体准确率达到 58.0%,比使用 PHP 的 Complex-CoT 方法高出 4.2%。值得注意的是,我们的方法在最难的 level-5 问题上实现了 43% 的相对改进(22.4% → 32.1%)。
2.Preliminaries
2.1 Propositional logic
命题逻辑是最基本的逻辑系统,包含元素 p , q , r p,q,r p,q,r 和各种运算。这些包括“与” ( p ∧ q ) (p∧q) (p∧q)、“或” ( p ∨ q ) (p∨q) (p∨q)、“蕴含” ( p ⇒ q ) (p⇒q) (p⇒q) 和“非” ( ¬ p ) (\neg p) (¬p)。常量 true 和 false 分别表示为 1 和 0。该系统遵循以下规则:
x ∧ x = x , x ∨ x = x , 1 ∧ x = 1 , 0 ∨ x = 0 , x ∧ ( y ∨ x ) = x = ( x ∧ y ) ∨ x . x∧x=x,\quad x∨x=x,\quad 1∧x=1,\quad 0∨x=0,\quad x∧(y∨x)=x=(x∧y)∨x. x∧x=x,x∨x=x,1∧x=1,0∨x=0,x∧(y∨x)=x=(x∧y)∨x.
和分配律:
x ∧ ( y ∨ z ) = ( x ∧ y ) ∨ ( x ∧ z ) , x ∨ ( y ∧ z ) = ( x ∨ y ) ∧ ( x ∨ z ) . x∧(y∨z)=(x∧y)∨(x∧z),\quad x∨(y∧z)=(x∨y)∧(x∨z). x∧(y∨z)=(x∧y)∨(x∧z),x∨(y∧z)=(x∨y)∧(x∨z).
在布尔代数中,每个元素 x x x 都有一个补码 ¬ x \neg x ¬x 并且以下内容成立:
x ∧ ¬ x = 0 , x ∨ ¬ x = 1 , ¬ ¬ x = x . x∧\neg x=0,x∨\neg x=1,\neg\neg x=x. x∧¬x=0,x∨¬x=1,¬¬x=x.
2.2 Higher-order logic
在命题逻辑的基础上,一阶逻辑 (FOL) 引入了全称量词符号 ( ∀ ∀ ∀) 和存在量词符号 ( ∃ ∃ ∃) 来描述更复杂的命题。例如,语句“ ∀ x D o g ( x ) ⇒ A n i m a l ( x ) ∀_xDog(x) ⇒ Animal(x) ∀xDog(x)⇒Animal(x)”翻译为“对于每个x,如果x是一只狗,那么它也是一只动物”。
高阶逻辑 (HOL) 代表了一种复杂的形式主义,允许对函数和谓词进行量化,这种能力与 FOL 形成鲜明对比,FOL 限制对单个对象的量化。与 FOL 相比,HOL 的显着特征可以阐述如下:
Quantification over Functions:高阶逻辑 (HOL) 允许使用 lambda 表达式,例如 λ y . r e p o r t _ a t t r i b u t e ( y , r e p o r t ) λy.report\_attribute(y, report) λy.report_attribute(y,report),由此函数本身成为量化的主题。“阅读本报告的代表”这一表述就说明了这一点。在这里,量化跨越了代表报告以及阅读报告的谓词,这种现象被捕获为高阶函数。与 HOL 不同,FOL 无法将量化扩展到函数或谓词。
Generalized Quantifiers:广义量词(例如“most”)的引入成为 HOL 和 FOL 之间的另一条分界线。这些量词能够接受谓词作为参数,从而能够表示集合之间的关系,这是超越 FOL 的表达能力。
Modal Operators:使用“might”等模态运算符意味着向 HOL 的过渡。这些适用于命题的运算符产生了多方面的表达式,无法轻松简化到 FOL 的范围。
Attitude Verbs and Veridical Predicates:态度动词(例如““believe”)和真实谓词(例如“manage”)的整合增加了一层额外的复杂性,需要使用 HOL。这些语言结构可以将命题作为论证,以微妙的方式与这些命题的真值相互作用,这需要超出 FOL 能力的推理。
2.3 Illustrative example
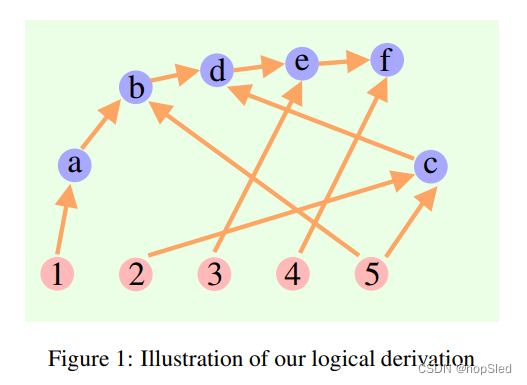
考虑以下修改自 FOLIO 数据集的示例,其中根据经验仅给出文本语句(不包括逻辑命题):
- All monkeys are mammals: ∀ x ( M o n k e y ( x ) ⇒ M a m m a l s ( x ) ) ∀x(Monkey(x) ⇒ Mammals(x)) ∀x(Monkey(x)⇒Mammals(x)).
- An animal is either a monkey or a bird: ∀ x ( A n i m a l ( x ) ⇒ ( M o n k e y ( x ) ∨ B i r d ( x ) ) ) ∀x(Animal(x) ⇒ (Monkey(x) ∨ Bird(x))) ∀x(Animal(x)⇒(Monkey(x)∨Bird(x)))
- All birds fly: ∀ x ( B i r d ( x ) ⇒ F l y ( x ) ) ∀x(Bird(x) ⇒ Fly(x)) ∀x(Bird(x)⇒Fly(x)).
- If something can fly, then it has wings: ∀ x ( F l y ( x ) ⇒ W i n g s ( x ) ) ∀x(Fly(x) ⇒ Wings(x)) ∀x(Fly(x)⇒Wings(x)).
- Rock is not a mammal, but Rock is an animal: ¬ M a m m a l ( R o c k ) ∧ A n i m a l ( R o c k ) ¬Mammal(Rock) ∧ Animal(Rock) ¬Mammal(Rock)∧Animal(Rock).
那么问题是: does Rock have wings? 我们具有下列的推导:
a. The contrapositive of (1) is: ∀ x ( ¬ M a m m a l s ( x ) ⇒ ¬ M o n k e y ( x ) ) ∀x(¬Mammals(x) ⇒ ¬Monkey(x)) ∀x(¬Mammals(x)⇒¬Monkey(x)).
b. ( a ) a n d ( 5 ) ⇒ ¬ M o n k e y ( R o c k ) ∧ A n i m a l ( R o c k ) (a)~and~(5) ⇒ ¬Monkey(Rock) ∧ Animal(Rock) (a) and (5)⇒¬Monkey(Rock)∧Animal(Rock).
c. ( 2 ) a n d ( 5 ) ⇒ ( M o n k e y ( R o c k ) ∨ B i r d ( R o c k ) ) (2)~and~(5) ⇒ (Monkey(Rock) ∨ Bird(Rock)) (2) and (5)⇒(Monkey(Rock)∨Bird(Rock)).
d. ( b ) a n d ( c ) ⇒ B i r d ( R o c k ) (b)~and~(c) ⇒ Bird(Rock) (b) and (c)⇒Bird(Rock).
e. ( 3 ) a n d ( d ) ⇒ F l y ( R o c k ) (3)~and~(d) ⇒ Fly(Rock) (3) and (d)⇒Fly(Rock).
f. ( 4 ) a n d ( e ) ⇒ W i n g s ( R o c k ) (4)~and~(e) ⇒ Wings(Rock) (4) and (e)⇒Wings(Rock).
虽然推导可以被视为从(a)到(f)的一般“思想链”,但其内部结构既不是链也不是树。相反,它是一个有向无环图(DAG),每条有向边都是一个推导步骤。有关高阶逻辑的示例,请参阅附录 A。
3.Our Method
3.1 Cumulative Reasoning (CR)
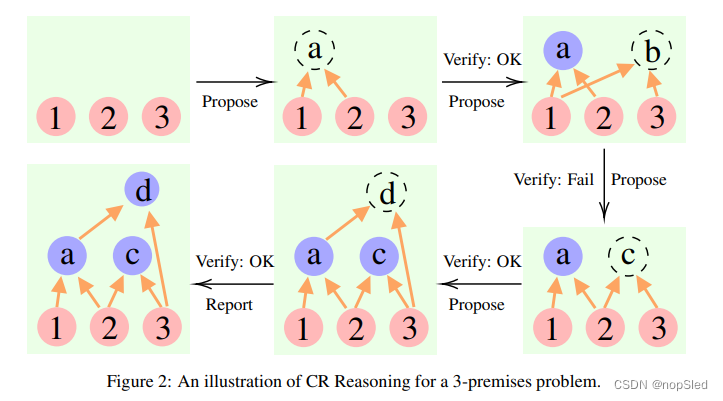
我们的CR算法使用了三种不同类型的LLM:
- Proposer。该模型根据当前情况建议下一步。
- Verifier(s)。该模型或模型集仔细检查Proposer提出的步骤的准确性。如果该步骤被认为是正确的,它将被添加到上下文中。
- Reporter。该模型通过访问当前条件是否可以直接得出最终解决方案来确定推理过程何时结束。
请参见图 2 的说明。在每次迭代中,Proposer通过基于现有谓词提出一个或几个新声明来启动该过程。随后,Verifier(s)评估该提案,确定该声明是否可以保留为新谓词。最后,Reporter决定是否是停止思考并给出答案的最佳时间。
理想情况下,Proposer应该使用在相应的推导任务上预训练的语言模型来实现。Verifier应该能够将推导转换为适当的形式系统,并使用符号推理模块(例如命题逻辑求解器或形式数学证明器)对其进行验证。然而,人们也可以使用 GPT-4 或 LLaMA 等通用基础模型,并对这些角色有不同的提示。
3.2 Compare with CoT and ToT
这篇关于Cumulative Reasoning With Large Language Models翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!