本文主要是介绍OpenCV—python 角点特征检测之三(FLANN匹配),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、单应性矩阵
- 二、FLANN匹配
- 2.1 FLANN介绍
- 2.2 FLANN的单应性匹配
- 2.3 FLANN特征保存与匹配
- 保存图片的特征数据
- 加载图片的特征数据,对需要匹配的数据集进行匹配
- 图片模板与批量寻找
一、单应性矩阵
OpenCV在通过特征描述子完成描述子匹配之后,会得到一些关键点对,我们会把这些关键点对分别添加到两个vector对象中,作为输入参数,调用单应性矩阵发现函数来发现一个变换矩阵H,函数 findHomography 就完成了这样的功能,有了变换矩阵H之后,我们就可以根据输入图像四点坐标,从场景图像上得到特征匹配图像的四点坐标。
调用单应性矩阵发现函数 findHomography
Mat cv::findHomography ( InputArray srcPoints, //特征点集合,一般是来自目标图像InputArray dstPoints, //特征点集合,一般是来自场景图像int method = 0, //配准方法,支持有四种方法/* 0 – 使用所有的点,比如最小二乘RANSAC – 基于随机样本一致性LMEDS – 最小中值RHO –基于渐近样本一致性 */double ransacReprojThreshold = 3,OutputArray mask = noArray(),const int maxIters = 2000, //最大迭代次数,当使用RANSAC方法const double confidence = 0.995 //置信参数,默认为0.995
)
最小二乘方法在描述子匹配输出的点对质量很好,理想情况下是图像没有噪声污染与像素迁移与光线恒定,但是实际情况下图像特别容易受到光线、噪声导致像素迁移,从而产生额外的多余描述子匹配,这些点对可以分为outlier跟inlier两类。
RANSAC(Random Sample Consensus)可以很好的过滤掉outlier点对,使用合法的点对得到最终的变换矩阵H,基本思想是,它会从给定的数据中随机选取一部分进行模型参数计算,然后使用全部点对进行计算结果评价,不断迭代,直到选取的数据计算出来的错误是最小,比如低于0.5%即可。
注意有时候RANSAC方法不会收敛,导致图像对齐或者配准失败,原因在于RANSAC是一种全随机的数据选取方式,完全没有考虑到数据质量不同。
- 算法流程步骤如下:
- 1 选择求解模型要求的最少要求的随机点对
2 根据选择随机点对求解/拟合模型得到参数
3 根据模型参数,对所有点对做评估,分为outlier跟inlier
4 如果所有inlier的数目超过预定义的阈值,则使用所有inlier重新评估模型参数,停止迭代
5 如果不符合条件则继续1~4循环。
PROSAC(Progressive Sampling Consensus)(RANSAC算法的改进算法)即渐近样本一致性,该方法采用半随机方法,对所有点对进行质量评价计算Q值,然后根据Q值降序排列,每次只在高质量点对中经验模型假设与验证,这样就大大降低了计算量,在RANSAC无法收敛的情况下,PROSAC依然可以取得良好的结果。OpenCV中的RHO方法就是基于PROSAC估算。
LMEDS最小中值方法拟合,该方法可以看成是最小二乘法的改进,原因在于计算机视觉的输入数据是图像,一般都是各自噪声,这种情况下最小二乘往往无法正确拟合数据,所以采用最小中值方法可以更好实现拟合,排除outlier数据。但是它是对高斯噪声敏感算法。
- 它的最主要步骤描述如下:
- 1 随机选取很多个子集从整个数据集中
2 根据各个子集数据计算参数模型
3 使用计算出来的参数对整个数据集计算中值平方残差
4 最终最小残差所对应的参数即为拟合参数。
二、FLANN匹配
在上篇文章中介绍了暴力匹配BFMatcher,相对暴力匹配BFMatcher来讲,FLANN匹配算法比较准确、快速和使用方便。FLANN具有一种内部机制,可以根据数据本身选择最合适的算法来处理数据集。值得注意的是,FLANN匹配器只能使用SURF和SIFT算法来检测角点。
2.1 FLANN介绍
FLANN (Fast_Library_for_Approximate_Nearest_Neighbors)快速最近邻搜索包。
它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集时它的效果要好于 BFMatcher。
-
indexparams = dict(algorithm =FLANN_INDEX_KDTREE, trees = 5) -
searchparams = dict(checks = 100)
指定递归遍历的次数checks 。值越高结果越准确, 但是消耗的时间也越多。
首先我们定义一个需要查询的图像,在其中找到一些特征点(关键点),然后再在另一幅图像中也找到了一些特征点,最后对这两幅图像之间的特征点进行匹配。
整个匹配过程如下:
-
使用 calib3d 模块中的 cv2.findHomography() 函数。如果将这两幅图像中的特征点集传给这个函数,他就会找到这个对象的透视图变换。然后就可以使用函数cv2.perspectiveTransform() 找到这个对象了。至少要 4 个正确的点才能找到这种变换。
-
在匹配过程可能会有一些错误,而这些错误会影响最终结果。为了解决这个问题,算法使用 RANSAC 和 LEAST_MEDIAN(可以通过参数来设定)。
好的匹配提供的正确的估计被称为 inliers,剩下的被称为outliers。cv2.findHomography() 返回一个掩模,这个掩模确定了 inlier 和outlier 点。
用比值判别法(ratio test)删除离群点:
检测出的匹配点可能有一些是错误正例(false positives)。
以为这里使用过的kNN匹配的k值为2(在训练集中找两个点),第一个匹配的是最近邻,第二个匹配的是次近邻。直觉上,一个正确的匹配会更接近第一个邻居。
换句话说,一个不正确的匹配,两个邻居的距离是相似的。因此,我们可以通过查看二者距离的不同来评判距匹配程度的好坏。比值检测认为第一个匹配和第二个匹配的比值小于一个给定的值(一般是0.5),这里是0.7。
FLANN实现方式如下:
import cv2
from matplotlib import pyplot as pltdef FLANN():queryImage = cv2.imread('./gggg/001.png',0)trainingImage = cv2.imread('./gggg/004.png',0)# 使用SIFT 或 SURF 检测角点sift = cv2.xfeatures2d.SIFT_create()kp1, des1 = sift.detectAndCompute(queryImage,None)kp2, des2 = sift.detectAndCompute(trainingImage,None)# 设置FLANN匹配器参数,定义FLANN匹配器,使用 KNN 算法实现匹配indexParams = dict(algorithm=0, trees=5)searchParams = dict(checks=50)flann = cv2.FlannBasedMatcher(indexParams,searchParams)matches = flann.knnMatch(des1,des2,k=2)# 根据matches生成相同长度的matchesMask列表,列表元素为[0,0]matchesMask = [[0,0] for i in range(len(matches))]# 去除错误匹配for i,(m,n) in enumerate(matches):if m.distance < 0.7*n.distance:matchesMask[i] = [1,0]# 将图像显示# matchColor是两图的匹配连接线,连接线与matchesMask相关# singlePointColor是勾画关键点drawParams = dict(matchColor = (0,255,0),singlePointColor = (255,0,0),matchesMask = matchesMask[:50],flags = 0)resultImage = cv2.drawMatchesKnn(queryImage,kp1,trainingImage,kp2,matches[:50],None,**drawParams)return resultImageif __name__ == '__main__':resultImage = FLANN()plt.imshow(resultImage)plt.show()# 分别测试了两张图,后一张图限定绘制连接线。

2.2 FLANN的单应性匹配
单应性是一个条件,该条件表面当两幅图像中的一副出像投影畸变时,他们还能匹配。
实现代码如下:
import cv2
import numpy as np
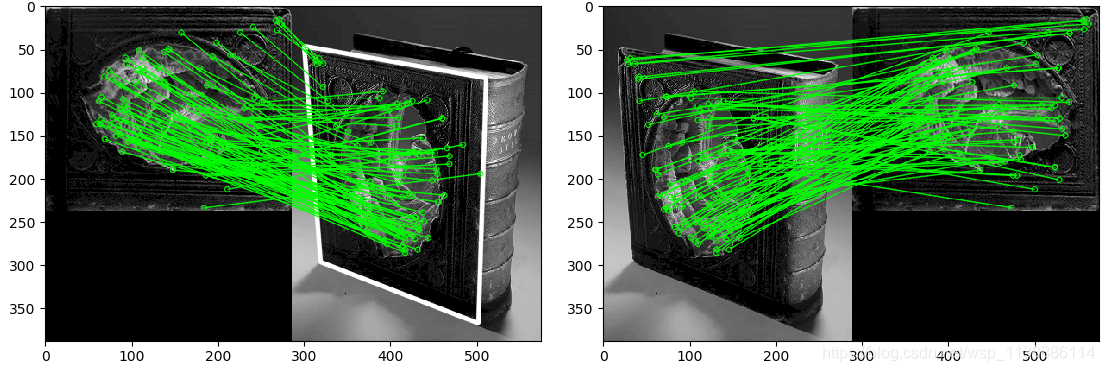
from matplotlib import pyplot as pltdef FLANN_MIN_MATCH_COUNT():MIN_MATCH_COUNT = 10img1 = cv2.imread('./gggg/003.png',0)img2 = cv2.imread('./gggg/007.png',0)sift = cv2.xfeatures2d.SIFT_create()kp1, des1 = sift.detectAndCompute(img1,None)kp2, des2 = sift.detectAndCompute(img2,None)index_params = dict(algorithm = 1, trees = 5)search_params = dict(checks = 50)flann = cv2.FlannBasedMatcher(index_params, search_params)matches = flann.knnMatch(des1,des2,k=2)good = []for m,n in matches:if m.distance < 0.7*n.distance:good.append(m)# 单应性if len(good)>MIN_MATCH_COUNT:# 改变数组的表现形式,不改变数据内容,数据内容是每个关键点的坐标位置src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)# findHomography 函数是计算变换矩阵# 参数cv2.RANSAC是使用RANSAC算法寻找一个最佳单应性矩阵H,即返回值M# 返回值:M 为变换矩阵,mask是掩模M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)matchesMask = mask.ravel().tolist() # ravel()展平,并转成列表h,w = img1.shape# pts是图像img1的四个顶点pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)dst = cv2.perspectiveTransform(pts,M) # 计算变换后的四个顶点坐标位置# 根据四个顶点坐标位置在img2图像画出变换后的边框img2 = cv2.polylines(img2,[np.int32(dst)],True,(255,0,0),3, cv2.LINE_AA)else:print("Not enough matches are found - %d/%d") % (len(good),MIN_MATCH_COUNT)matchesMask = Nonedraw_params = dict(matchColor = (0,255,0),singlePointColor = None,matchesMask = matchesMask[:100],flags = 2)img3 = cv2.drawMatches(img1,kp1,img2,kp2,good[:100],None,**draw_params)return img3
if __name__ == '__main__':img3 = FLANN_MIN_MATCH_COUNT()plt.imshow(img3, 'gray')plt.show()
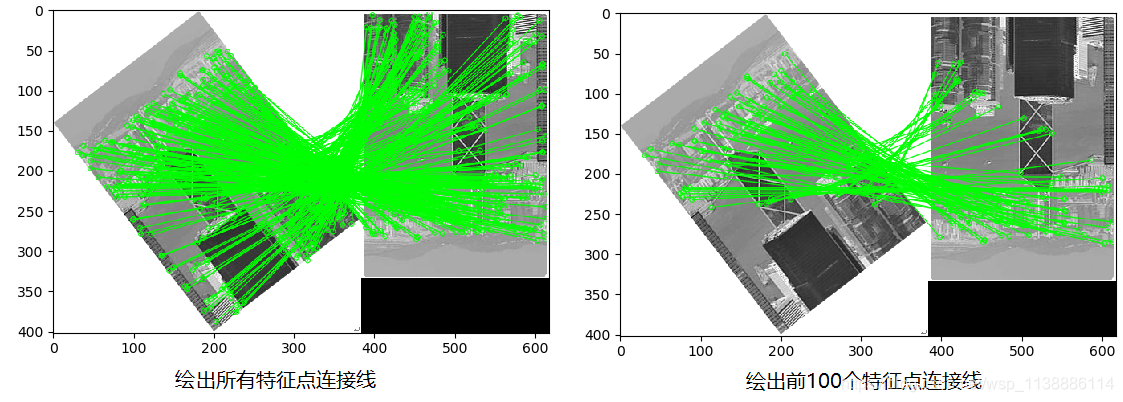
又测试了一组照片如下:
2.3 FLANN特征保存与匹配
在实际中,我们根据一张图片在众多的图片中查找匹配率最高的图片。如果按照上面的例子,也可以实现,但每次匹配时都需要重新检测图片的特征数据,这样会导致程序运行效率。
因此,我们可以将图片的特征数据进行保存,每次匹配时,只需读取特征数据进行匹配即可。
实现代码如下:
保存图片的特征数据
import cv2
import numpy as np
import osdef get_img(input_path):image_paths = []for (dirs, dirnames, filenames) in os.walk(input_path):for img_file in filenames:ext = ['.jpg','.png','.jpeg','.tif']if img_file.endswith(tuple(ext)):image_paths.append(dirs+'/'+img_file)return image_pathsdef save_descriptor(sift,image_path):if image_path.endswith("npy"):returnimg = cv2.imread(image_path, 0)keypoints, descriptors = sift.detectAndCompute(img, None)# 设置文件名并将特征数据保存到npy文件descriptor_file = image_path.replace(image_path.split('.')[-1], ".npy")np.save(descriptor_file, descriptors)if __name__=='__main__':input_path = 'D:\\python_script\\hhhh'image_paths = get_img(input_path)sift = cv2.xfeatures2d.SIFT_create()for image_path in image_paths:save_descriptor(sift, image_path)print('done!')
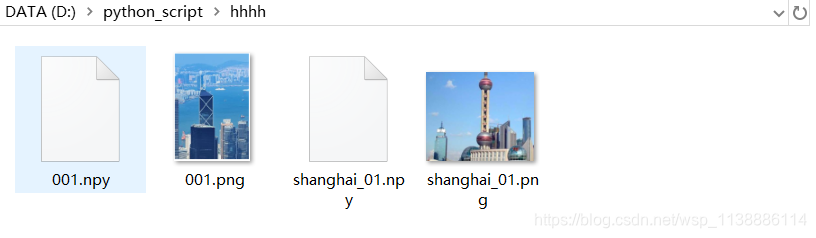
加载图片的特征数据,对需要匹配的数据集进行匹配
import numpy as np
import cv2,osdef Get_npy(input_path):descriptors = []for (dirs, dirnames, filenames) in os.walk(input_path):for img_file in filenames:if img_file.endswith('npy'):descriptors.append(dirs+'/'+img_file)return descriptorsdef SIFT_FLANN():sift = cv2.xfeatures2d.SIFT_create()index_params = dict(algorithm=0, trees=5)search_params = dict(checks=50)flann = cv2.FlannBasedMatcher(index_params, search_params)return sift,flanndef Detect_Matches(sift,flann,query,descriptors):query_kp, query_ds = sift.detectAndCompute(query, None)potential_culprits = {}for desc in descriptors:# 将图像query与特征数据文件的数据进行匹配matches = flann.knnMatch(query_ds, np.load(desc), k=2)# 清除错误匹配good = []for m, n in matches:if m.distance < 0.7 * n.distance:good.append(m)# 输出每张图片与目标图片的匹配特征数目print("img is %s ! matching rate is (%d)" % (desc, len(good)))potential_culprits[desc] = len(good)# 获取最多匹配数目的图片max_matches = Nonepotential_suspect = Nonefor culprit, matches in potential_culprits.items():if max_matches == None or matches > max_matches:max_matches = matchespotential_suspect = culpritprint("potential suspect is %s" % potential_suspect.replace("npy", "").upper())if __name__ == '__main__':query = cv2.imread('D:\\python_script\\gggg\\001.png', 0)input_path = 'D:\\python_script\\hhhh'descriptors = Get_npy(input_path) # 获取特征数据文件sift, flann = SIFT_FLANN() # 使用SIFT算法检查图像的关键点和描述符,创建FLANN匹配器Detect_Matches(sift, flann, query, descriptors) # 检测并匹配
图片模板与批量寻找
当然你也可以对需要寻找的图片制作几个通用模板,方便批量寻找图片(该算法有个很大的缺点,请自行体会)。
import cv2
import os,shutil,csvdef get_img(ImgNpy_path):image_paths = []for (dir, dirnames, filenames) in os.walk(ImgNpy_path):for img_file in filenames:ext = ['.jpg','.png','.jpeg','.tif']if img_file.endswith(tuple(ext)):image_paths.append(dir+'/'+img_file)return image_pathsdef SIFT_FLANN():sift = cv2.xfeatures2d.SIFT_create()index_params = dict(algorithm=0, trees=5)search_params = dict(checks=50)flann = cv2.FlannBasedMatcher(index_params, search_params)return sift,flanndef Detect_Matches(sift,flann,query,des1):query_kp, des2 = sift.detectAndCompute(query, None)matches = flann.knnMatch(des1, des2, k=2)good_matches = []for m,n in matches:if m.distance < 0.7*n.distance:good_matches.append(m)points = len(good_matches)percent = round((len(good_matches)/len(matches)),3)*100if 60>percent>30:percent += percent*(1 - percent*0.01)return points ,percentdef main(Moban_path,Sou_Imgpath,Target_path):Moban_paths = get_img(Moban_path) # 获取模板文件Sou_paths = get_img(Sou_Imgpath) # 获取待搜寻的图片sift, flann = SIFT_FLANN() # 创建FLANN匹配器(使用SIFT算法检查图像的关键点和描述符)Contrast_csv = []for moban_img in Moban_paths: # 制作特征img = cv2.imread(moban_img, 0)_, des1 = sift.detectAndCompute(img, None)for image_path in Sou_paths:try:query = cv2.imread(image_path, 0)points,percent = Detect_Matches(sift, flann, query, des1) # 检测并匹配Contrast_csv.append((moban_img, image_path, points, str(percent)+'%'))if percent>=50:shutil.copy(image_path,Target_path)print("Img:{}\t Similarity_degree:{}%".format(image_path,percent))else:print('This image is not need!')except:print('img read error!')return Contrast_csvdef save_csv(csv_path,Contrast_csv):with open(csv_path, 'w', newline='') as csv_file:csv_writer = csv.writer(csv_file)csv_writer.writerow(('模板图','被检测的图片','匹配特征点', '相似度百分比'))csv_writer.writerows(Contrast_csv)if __name__ == '__main__':Moban_path = 'D:\\python_script\\hhhh' # 被查寻的图片模板Sou_Imgpath = 'D:\\python_script\\eeee' # 需要筛选的图片目录Target_path = 'D:\\python_script\\jjjj' # 筛选之后存放图片的目录csv_path = 'D:\\python_script\\iiii\\Contrast_04.csv' # 匹配信息保存Contrast_csv = main(Moban_path,Sou_Imgpath,Target_path) # 检测特征save_csv(csv_path, Contrast_csv)print('done!')
参考与鸣谢
https://blog.csdn.net/jinxueliu31/article/details/37768995
https://blog.csdn.net/GAN_player/article/details/78285771
这篇关于OpenCV—python 角点特征检测之三(FLANN匹配)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






