本文主要是介绍Targeted Dropout,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文下载地址:https://openreview.net/pdf?id=HkghWScuoQ
码源:https://nips.cc/Conferences/2018/Schedule?showEvent=10941
Targeted Dropout的提出,是想解决原本dropout可能丢失关键信息神经元的问题
从dropout谈起:
我们在前向传播的时候,让某些神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
dropout的使用可以有效缓解过拟合的发生,在一定程度上达到正则化的目的
但是dropout对于神经元的失活具有很强的***随机性***
Targeted Dropout想结合Unit Dropout与Weight Dropout两种思想
对于具有输入张量X、权重矩阵W、输出张量Y和Mask M的全连接层
Unit Dropout:
在每一次更新中都会随机删除单元或神经元,因此它能降低单元之间的相互依赖关系,并防止过拟合。
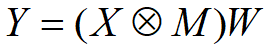
Weight Dropout:
在每一次更新中都会随机删除权重矩阵中的权值。直观而言,删除权重表示去除层级间的连接,并强迫神经网络在不同的训练更新步中适应不同的连接关系。
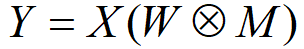
Targeted Dropout具体实现方法:
考虑一个由θ参数化的神经网络,且希望按照Unit Dropout和Weight Dropout定义的方法对W进行剪枝。
因此,希望找到最优参数θ*,它能令损失函数ε(W(θ*))尽可能小的同时,令|W(θ* )|≤k,即希望保留神经网络中最高数量级的k个权重。一个确定性的实现可以选择最小的|θ|−k个元素,并删除它们。但是如果这些较小的值在训练中变得更重要,那么它们的数值应该是增加的。因此,通过利用targeting proportion γ和删除概率α,将随机性引入到了这个过程中。
其中targeting proportion表示会选择最小的γ|θ|个权重作为Dropout的候选权值,并且随后以删除概率α独立地去除候选集合中的权值。这意味着在Targeted Dropout中每次权重更新所保留的单元数为(1−γ*α)|θ|。
Targeted Dropout降低了重要子网络对不重要子网络的依赖性,因此降低了对已训练神经网络进行剪枝的性能损失。
总结:
Targeted Dropout的提出想法是让原本dropout的随机失活作用下,原本权重更高的神经元不会被更高概率的被丢失掉,但是考虑到较小的值可能也会对训练有一定的影响,所以不是单纯的丢弃掉值相对较小的那一部分,而是将阈值提高,使更小值神经元范围增加,然后在小数神经元中随机失活,这样既考虑到了大数神经元的影响更高,也兼顾了小数神经元可能的作用,没有完全丢弃掉。而根据论文作者跑的实验来看,效果的确更好,可能以后这个方法会将dropout替换点,但是两个参数可能需要训练,非常量。
这篇关于Targeted Dropout的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








