本文主要是介绍ICLR 2022)ODConv:即插即用的动态卷积 (附代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:Omni-Dimensional Dynamic Convolution | OpenReview
代码地址:https://github.com/OSVAI/ODConv/blob/main/modules/odconv.py
1.是什么?
ODConv是一种动态卷积算法,它的原理是在卷积过程中,根据输入数据的特征动态地调整卷积核的形状和大小,以适应不同的输入数据。具体来说,ODConv通过引入一个可学习的形变模块,根据输入数据的特征动态地调整卷积核的形状和大小,从而提高了卷积神经网络的性能。与CondConv和DyConv不同,ODConv不仅考虑了空间维度、输入通道维度和输出通道维度,还考虑了卷积核的形状和大小,因此可以更好地适应不同的输入数据。
2.为什么?
常规卷积只有一个静态卷积核且与输入样本无关。对于动态卷积来说,它对多个卷积核进行线性加权,而加权值则与输入有关,这就使得动态卷积具有输入依赖性。它可以描述如下:
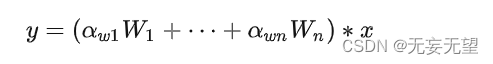
尽管动态卷积的定义很简单,但CondConv与DyConv的实现是不相同的,主要体现在计算的结构
训练策略以及实施动态卷积的层,这些实现上的差异导致了不同的模型精度、模型大小以及推理效率。
- 两者均为
采用了类SE架构,但CondConv采用的是Sigmoid,而DyConv采用的是Softmax;
- DyConv采用的退化策略进行训练以抑制Softmax的one-hot输出;
- 对于他们嵌入的CNN架构,CondConv替换了最后几个模块的卷积与全连接层,而DyConv则对除第一个卷积外的其他卷积均进行了替换。
根据动态卷积的公式来看,动态卷积有两个基本元素:
- 卷积核
;
- 用于计算注意力{
}的注意力函数
给定n个卷积核,其对应的核空间有以下四个维度:
- 空间核尺寸k×k;
- 输入通道数
- 输出通道数
- 卷积核数量n
然而,对于CondConv与DyConv来说,均采用单个注意力标量
,这就意味着它的的输出滤波器
∈
对于输入具有相同的注意力值。换句话说,卷积核
的空间维度、输入通道维度以及输出通道维度均被CondConv与DyConv所忽视了。这就导致了关于核空间的粗糙探索。这可能就是为什么CondConv与DyConv对于大网络的性能增益较低的原因。
此外,相比常规卷积,动态卷积的卷积核参数往往是其n倍。比如CondConv中的n=8,DyConv中的n=4。当动态卷积使用过多时无疑会极大程度提升模型大小。我们发现:当 移除掉CondConv/DyConv中的注意力机制(即=1)后,其性能提升接近于零。比如,对于ResNet18,其性能增益从1.78%/2.51%下降到了0.08%/0.14。
上述发现意味着:动态卷积中的注意力机制起关键性作用,更有效的设计也许可以在模型精度与大小之间得到更好的平衡。
一定程度上讲,ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。
3 怎么样?
3.1 网络结构
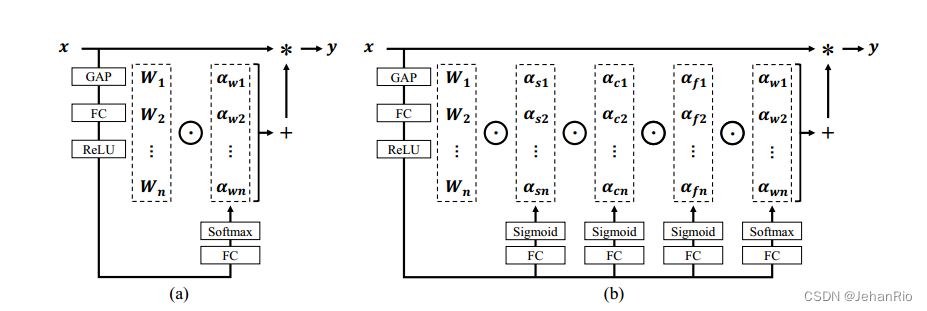
基于前述讨论,ODConv通过并行策略引入一种多维注意力机制以对卷积核空间的四个维度学习更灵活的注意力。上图给出CondConv、DyConv以及ODConv的差异图。
延续动态卷积的定义,ODConv可以描述成如下形式:
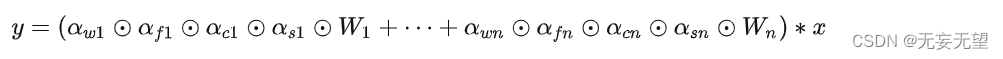
其中,表示卷积核
的注意力标量,
,
,
表示新引入的三个注意力,分别沿空域维度、输入通道维度以及输出通道维度。这四个注意力采用多头注意力模块
计算得到。
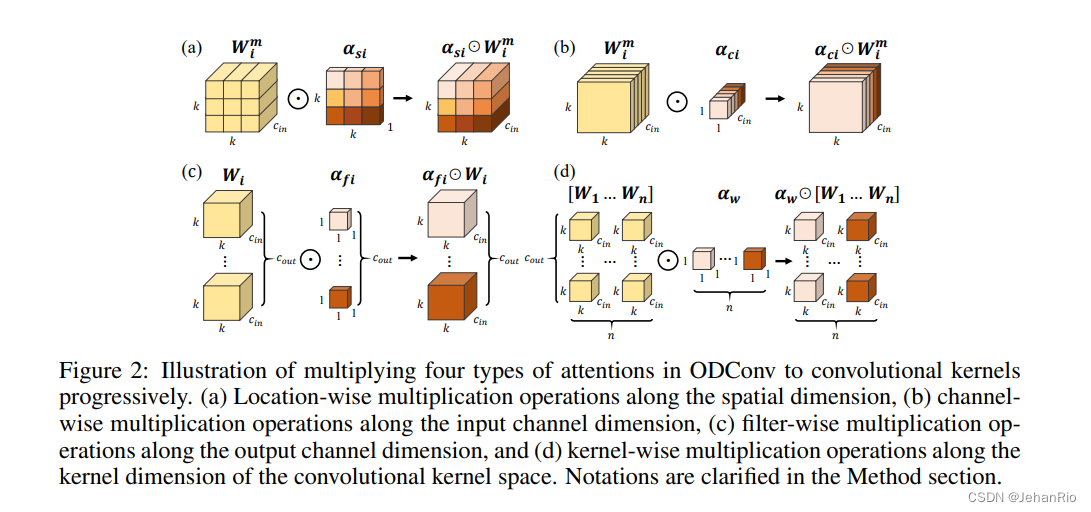
在ODConv中,对于卷积核,
对k*k空域位置上的卷积参数赋予不用的注意力值,见上图a;
对不同输入通道的卷积滤波器赋予不同的注意力值,见上图b;
对不同输出通道的卷积滤波器赋予不同的注意力值,见上图c;而
则对n个整体卷积核赋予不同的值,见上图d。
原则上来讲,这四种类型的注意力是互补的,通过渐进式对卷积沿位置、通道、滤波器以及核等维度乘以不同的注意力将使得卷积操作对于输入存在各个维度的差异性,提供更好的性能以捕获丰富上下文信息。因此,ODCOnv可以大幅提升卷积的特征提取能力;更重要的是,采用更少卷积核的ODConv可以取得与CondConv、DyConv相当甚至更优的性能。
对比前面两种动态卷积的公式可以发现:ODConv是一种更广义的动态卷积。此外,当设置n=1,=
=
=1时,ODConv则退化为仅具有滤波器层面的注意力,基于输入对卷积滤波器进行调制后再进行卷积,类似于SE。故SE是ODConv的一个特例。

那么如何实现ODConv的四种类型的注意力值呢?延续CondConv与DyConv,我们同样采用SE风格的注意力模块,但使其具有多个头以计算多种类型注意力,整体结构见上图。具体来说,对于输入先通过GAP收缩为长度为的特征向量,然后采用FC与四个头生成不同类型的注意力值。对于四个头,其维度分别为k*k,
×1,
×1,n×1。
在训练方面,我们采用了DyConv中的退化策略以加速训练。在具体架构嵌入方面,我们参考DyConv对除第一个卷积外的其他所有卷积进行替换。
3.2 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autogradclass Attention(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):super(Attention, self).__init__()attention_channel = max(int(in_planes * reduction), min_channel)self.kernel_size = kernel_sizeself.kernel_num = kernel_numself.temperature = 1.0self.avgpool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel)self.relu = nn.ReLU(inplace=True)self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attentionif in_planes == groups and in_planes == out_planes: # depth-wise convolutionself.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attentionif kernel_size == 1: # point-wise convolutionself.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attentionif kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def update_temperature(self, temperature):self.temperature = temperature@staticmethoddef skip(_):return 1.0def get_channel_attention(self, x):channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):x = self.avgpool(x)x = self.fc(x)x = self.bn(x)x = self.relu(x)return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)class ODConv2d(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1,reduction=0.0625, kernel_num=4):super(ODConv2d, self).__init__()self.in_planes = in_planesself.out_planes = out_planesself.kernel_size = kernel_sizeself.stride = strideself.padding = paddingself.dilation = dilationself.groups = groupsself.kernel_num = kernel_numself.attention = Attention(in_planes, out_planes, kernel_size, groups=groups,reduction=reduction, kernel_num=kernel_num)self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//groups, kernel_size, kernel_size),requires_grad=True)self._initialize_weights()if self.kernel_size == 1 and self.kernel_num == 1:self._forward_impl = self._forward_impl_pw1xelse:self._forward_impl = self._forward_impl_commondef _initialize_weights(self):for i in range(self.kernel_num):nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')def update_temperature(self, temperature):self.attention.update_temperature(temperature)def _forward_impl_common(self, x):# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,# while we observe that when using the latter method the models will run faster with less gpu memory cost.channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)batch_size, in_planes, height, width = x.size()x = x * channel_attentionx = x.reshape(1, -1, height, width)aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)aggregate_weight = torch.sum(aggregate_weight, dim=1).view([-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size)output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))output = output * filter_attentionreturn outputdef _forward_impl_pw1x(self, x):channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)x = x * channel_attentionoutput = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups)output = output * filter_attentionreturn outputdef forward(self, x):return self._forward_impl(x)参考:
ODConv详解
ICLR 2022 | 涨点神器!Intel提出ODConv:即插即用的动态卷积
致敬CondConv!Intel提出即插即用的“万金油”动态卷积ODConv
这篇关于ICLR 2022)ODConv:即插即用的动态卷积 (附代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






