本文主要是介绍python requests爬虫 发现了一个超棒的壁纸网站,爬它!告别壁纸荒,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先上图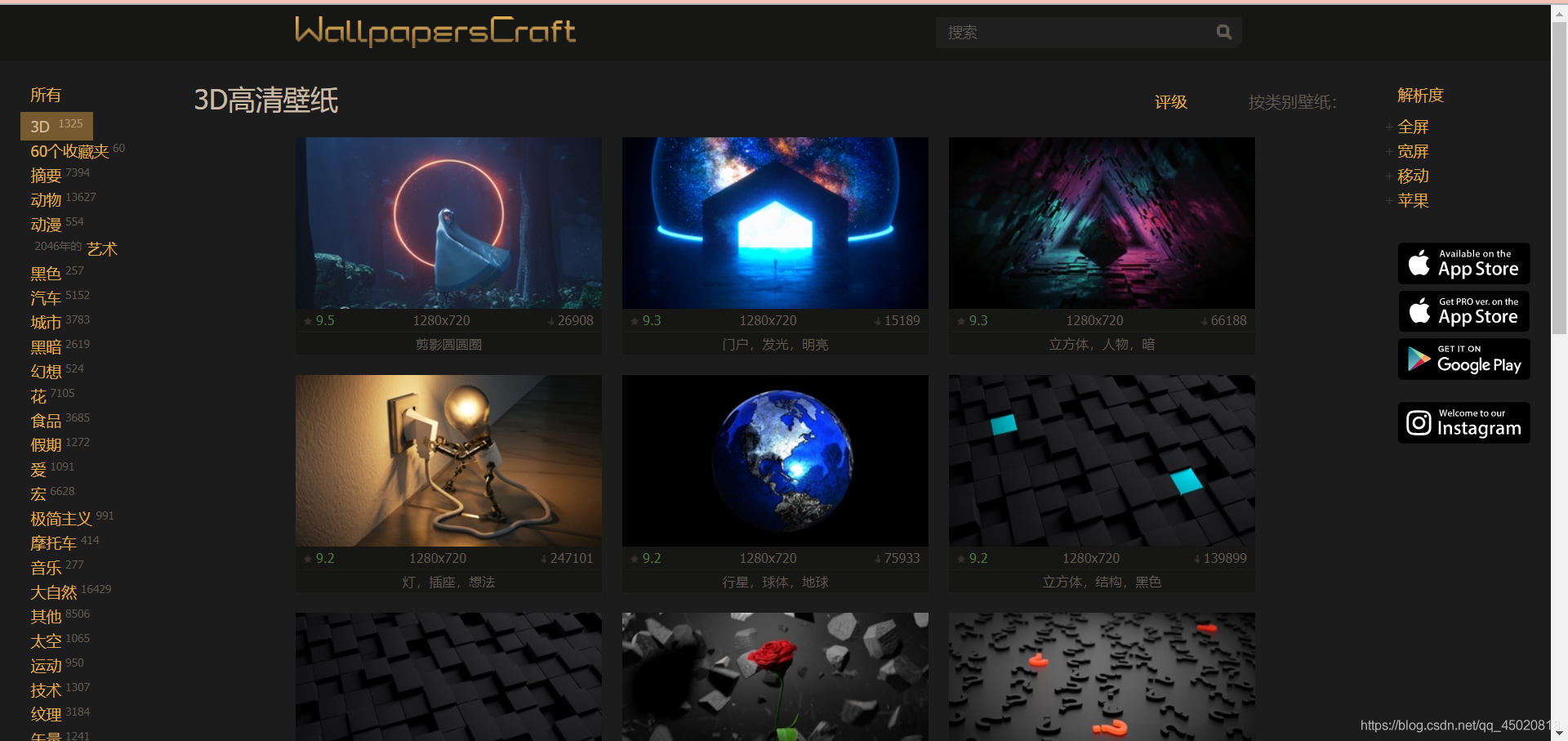
网址:https://wallpaperscraft.com/catalog/3d
网站的壁纸种类很多,而且都是高清呀,质量也不赖啊,都挺好看的。那就不多说了,爬它!
先 Ctrl+U 看一波网页源码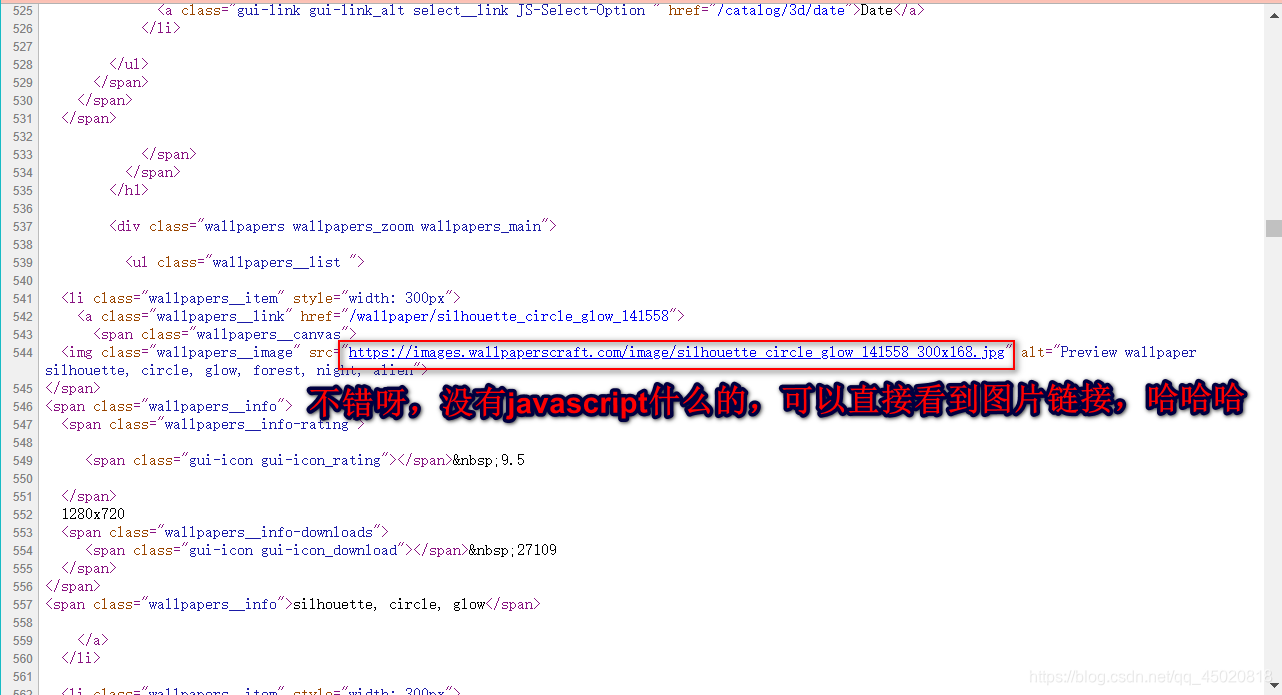
点进去一看,图片好小,果真没那么简单,上面的只是缩略图的链接。
把链接拎出来瞅瞅
https://images.wallpaperscraft.com/image/silhouette_circle_glow_141558_300x168.jpg
300x168 !!??!, 这不分辨率嘛,换成1920x1080试试?(换成其他行不行?待会再慢慢讲)
誒,它成了,那不就好办了,从网页找出所有壁纸缩略图链接,然后换一下分辨率参数,那就搞定!
到这里,可以确定,只用requests就可以搞定,不需要selenium来掺和了。
-
还有一个问题,就是前边提到的换链接的参数问题。
-
-
这里就要注意了,选择好解析度后,网页的链接也发生了变化,注意看图中的框框。
| https://wallpaperscraft.com/catalog/3d /1920x1080 |
|---|
| 不难发现,最后两个参数分别是 关键词/类别、分辨率/解析度 |
然后看一看第二页的链接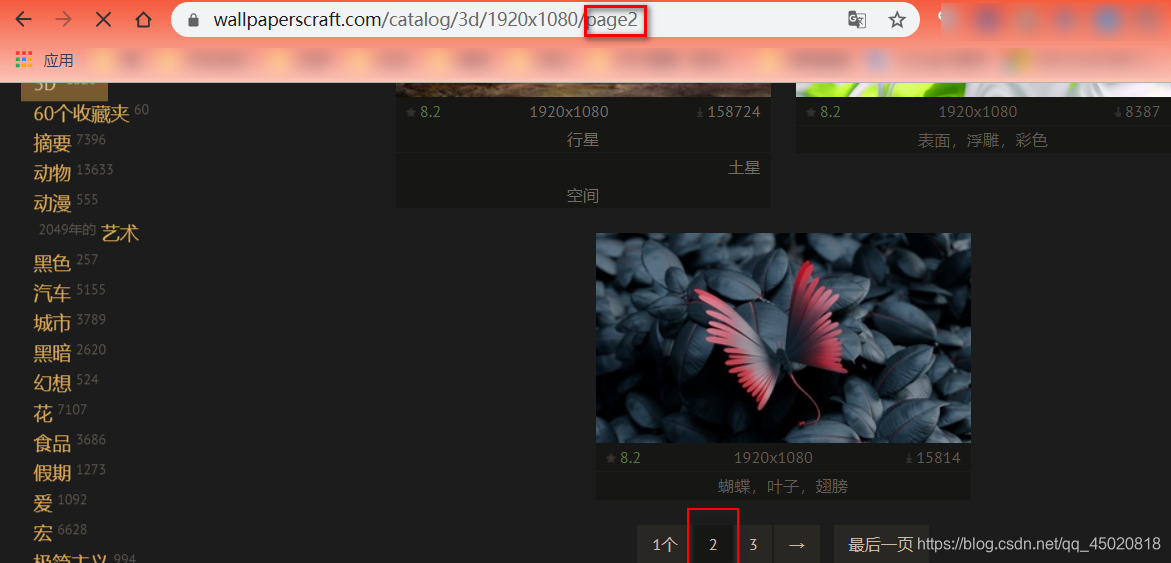
| https://wallpaperscraft.com/catalog/3d/1920x1080/page2 |
|---|
| 对比一下,发现就多了个参数: page2,这就很好办了 |
-
首先,确定好关键词(网页左边那一列,关掉翻译,看英文),以及适当的分辨率(在右侧解析度一栏 存在的值)
这样就大致确定了开始页的链接形式:
https://wallpaperscraft.com/catalog/(关键词)/(分辨率)/
接下来的工作就是每一页的去爬取数据,那到底有多少页呢?我是直接点‘最后一页’看了,当然也可以在爬虫里做判断。
import requests
def get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',}
接着就是Get一下传入的网页链接,然后返回网页的 HTML
try:requests.adapters.DEFAULT_RETRIES = 10r = requests.get(url, headers=headers, timeout=30)r.raise_for_status()r.encoding = 'utf-8'return r.textexcept Exception as t:print(t)return None
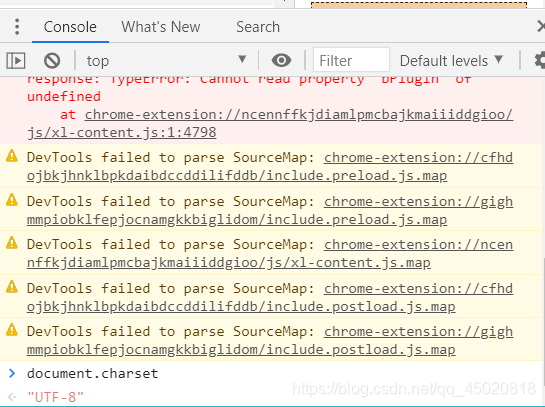
你凭什么直接说编码是‘utf-8’? 不急,这个可以在chrome浏览器的Console里输入:
document.charset
然后就可以看到了,如图
这里就不来什么选择器了,直接上正则大法,粗lan糙de一yao点ming。
那么,先观察一下链接所在的位置
梳理一下
-
前有:src=
-
-
以== https:// == 开头,以== jpg ==结尾,而且不包含双引号
于是,匹配模板出来了
pt = re.compile(r'src="(https://[^"]+jpg)"')
由于只要双引号里的链接,那就加个括号,括号外的不要!
没错,就是这么简答粗暴
def parse_links(html):pt = re.compile(r'src="(https://[^"]+jpg)"')links = pt.findall(html)for link in links:yield link
到这里,只是得到了缩略图的链接,可别忘了,那么只需要再换换参数就OK了
再来一个正则。匹配出分辨率参数部分,然后给它换喽
def sub_url(url):pt = re.compile(r'_[^_]+jpg')return pt.sub('_1920x1080.jpg', url)
然后页面解析函数就可以获取到原图链接了
def parse_links(html):pt = re.compile(r'src="(https://[^"]+jpg)"')links = pt.findall(html)for link in links:yield sub_url(link)
-
搞定好获取一页链接的方法,那就只用循环一下搞完其它的就ok
| 再来复习一下链接的形式 |
|---|
| https://wallpaperscraft.com/catalog/(关键词)/(分辨率)/page(n) |
| 参数 | 注意! |
|---|
| 关键词 | 英文。看主页左侧,英文原网页,有翻译记得先关一下 |
| 分辨率 | 网页右上角 解析度 那里有的值才能填,要不得翻车! |
| page(n) | n值可以是 1 ,最大不超过当前关键词下的总页数 |
交代完就可以开始循环爬取了
老样子,定义一个函数,链接模板放里边,然后传入‘关键词’、‘分辨率’、‘总页数’ 就构造出了链接的大概
def get_links(key_w, res, pages):start_url = f'https://wallpaperscraft.com/catalog/{key_w}/{res}/'
爬它趴着爬着崩了了,导致之前的爬取数据都跟着废,每爬取一页,就把获得的链接顺手写入文件存着,以防万一
links = []f = open(out_path + f'\\{key_w}.txt', 'a')for page in range(pages):url = start_url + f'page{page+1}'if html:=get_page(url):for link in parse_links(html):f.write(link + '\n')links.append(link)f.close()return links
-
不出意外,循环完后便可以得到一个壁纸链接的列表,接着就可以下载了
-
也不能不留一手,假如真的崩了,毕竟也是个外网,又不会科学上网 ,稳重一点,哈哈哈
-
-
那么就得稍微判断一下,链接的话直接下载,文件路径的话先读取出链接添加到列表,接着再下载
def download_pic(out_path, list_or_txt):if isinstance(list_or_txt, str):if op.isfile(list_or_txt):links = []with open(list_or_txt, 'r') as f:for link in f.readlines():link = link.strip('\n')links.append(link)else:links = []elif isinstance(links_or_txt, list):links = list_or_txt
isinstance(), 用来判断第二个参数是否是字符串(文件路径),不放心的话还可以用 os.path.isfile() 来判断一下下
祖传请求头别给忘了
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',}
为了方便,就把图片链接最后的部分直接用作文件名吧(别忘了用os.path.join()拼接出完整路径)
for url in links:try:img_name = url.split('/')[-1]img_path = op.join(out_path, img_name)
如果文件存在的话,那就跳过,下载下一个
if op.exists(img_path):continue
然后就可以下载了(闲着没事可以把认证给关了,hhhhh~)
requests.adapters.DEFAULT_RETRIES = 10requests.packages.urllib3.disable_warnings()r = requests.get(url, headers=headers, timeout=300, verify=False)with open(img_path, 'ab') as f:f.write(r.content)f.close()print(f'\r_第_[{links.index(url)+1}]_张__已下载【共{len(links)}张】', end='')
来个完整的循环下载部分。(一般报错都是超时,那么,报错也得给我继续爬!)
for url in links:try:img_name = url.split('/')[-1]img_path = op.join(out_path, img_name)if op.exists(img_path):continuerequests.adapters.DEFAULT_RETRIES = 10requests.packages.urllib3.disable_warnings()r = requests.get(url, headers=headers, timeout=300, verify=False)with open(img_path, 'ab') as f:f.write(r.content)f.close()print(f'\r_第_[{links.index(url)+1}]_张__已下载【共{len(links)}张】', end='')except Exception as t:download_pic(out_path, list_or_txt)
然后就是枯燥的主函数部分(需要的参数都给写喽)
def main():global out_pathout_path = r'c:\users\pxo\desktop\tem_pic'if not op.exists(out_path):os.mkdir(out_path)key_w = 'minimalism'res = '1920x1080' all_pages = 30links = get_links(key_w=key_w, res=res, pages=all_pages)
单线程多没意思,不如来试试多线程下载
threads = []for i in range(5):th = threading.Thread(target=download_pic, args=(out_path, links))threads.append(th)for th in threads:th.setDaemon(True)th.start()th.join()
| threading.Thread(target, args) |
|---|
| target | 子线程对应的目标函数、程序 |
|---|
| args | 目标函数的参数。以元组形式传入 |
那么为什么可以同时运行几个下载函数呢,不怕下重复啦?这就不用担心了,是否还记得下载函数中有一个判断
img_name = url.split('/')[-1]
img_path = op.join(out_path, img_name)
if op.exists(img_path):continue
这样就能保证文件已经被创建了的话,将不会重复下载,可以放心来。
完整代码
import requests
import re
import os
import os.path as op
import threadingdef sub_url(url):pt = re.compile(r'_[^_]+jpg')return pt.sub('_1920x1080.jpg', url)def get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',}try:requests.adapters.DEFAULT_RETRIES = 10r = requests.get(url, headers=headers, timeout=30)r.raise_for_status()r.encoding = 'utf-8'return r.textexcept Exception as t:print(t)return Nonedef parse_links(html):pt = re.compile(r'src="(https://[^"]+jpg)"')links = pt.findall(html)for link in links:yield sub_url(link)def get_links(key_w, res, pages):start_url = f'https://wallpaperscraft.com/catalog/{key_w}/{res}/'links = []f = open(out_path + f'\\{key_w}.txt', 'a')for page in range(pages):url = start_url + f'page{page+1}'if html:=get_page(url):for link in parse_links(html):f.write(link + '\n')links.append(link)f.close()return linksdef download_pic(out_path, list_or_txt):if isinstance(list_or_txt, str):if op.isfile(list_or_txt):links = []with open(list_or_txt, 'r') as f:for link in f.readlines():link = link.strip('\n')links.append(link)else:links = list_or_txtheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',}for url in links:try:img_name = url.split('/')[-1]img_path = op.join(out_path, img_name)if op.exists(img_path):continuerequests.adapters.DEFAULT_RETRIES = 10requests.packages.urllib3.disable_warnings()r = requests.get(url, headers=headers, timeout=300, verify=False)with open(img_path, 'ab') as f:f.write(r.content)f.close()print(f'\r_第_[{links.index(url)+1}]_张__已下载【共{len(links)}张】', end='')except Exception as t:download_pic(out_path, list_or_txt)def main():global out_pathout_path = r'c:\users\pxo\desktop\tem_pic'if not op.exists(out_path):os.mkdir(out_path)key_w = 'minimalism'res = '1920x1080' all_pages = 30links = get_links(key_w=key_w, res=res, pages=all_pages)threads = []for i in range(5):th = threading.Thread(target=download_pic, args=(out_path, links))threads.append(th)for th in threads:th.setDaemon(True)th.start()th.join()main()
这篇关于python requests爬虫 发现了一个超棒的壁纸网站,爬它!告别壁纸荒的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







