本文主要是介绍VLSI 设计中的线性 RC 延迟模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
VLSI 设计中的线性 RC 延迟模型
众所周知,为了使晶体管更小,人们做了大量工作。然而,仍然需要对 VLSI 电路和模块进行相应的工作,以适应更小的设计。这些 VLSI 电路和模块可能很简单,只有几个逻辑门(包含两到四个晶体管),也可能是包含成千上万个晶体管的更大系统。相反,这些系统需要满足各种工作条件下的速度/延迟和功率要求。
在本文中,我们将讨论如何确定单个晶体管的大小,以便在考虑到这些需求的情况下与其他晶体管正确集成。我们将首先介绍 RC 延迟模型。
这篇文章是系列文章的一部分,在该系列文章中,我们还将讨论其他流行的模型,例如用于估计 VLSI 电路延迟的 Elmore 延迟和逻辑努力。在这些后续文章中,我们还将研究如何组合这些晶体管和栅极以提供面积,同时提供性能。
线性 RC 延迟
与大多数电气系统一样,晶体管可以建模为简单的 RC 电路,其中通道宽度建模为电阻器,而扩散(即源极/漏极)之间的空间建模为电容器。
这创建了一个 RC 网络,该网络以在输入端(在本例中为晶体管的栅极)应用阶跃输入时具有指数上升/下降瞬态响应而闻名。上升/下降时间(即输出电压电平与输入电压电平匹配所需的时间)定义了晶体管电路的延迟。
计算晶体管的电阻
现在,什么是晶体管的有效电阻?我们如何计算晶体管的电阻?
通常,晶体管的电阻是漏源电压与漏源电流之间的比率。
在建模中,单位 NMOS 晶体管的有效电阻为 R,等于单元库或工艺中使用的尺寸 NMOS 晶体管的电阻。并且由于具有大宽度的晶体管驱动更多电流,因此 k 倍单位宽度的 NMOS 晶体管具有RkRk的电阻。而由于PMOS晶体管的迁移率较低,其有效电阻通常为2Rk2Rk。
晶体管的有效电容
对于 k 倍单位宽度,单位 NMOS/PMOS 晶体管的有效电容为“C”或“kC”。用于驱动类似逆变器的逆变器的等效 RC 电路如下图 1 所示。
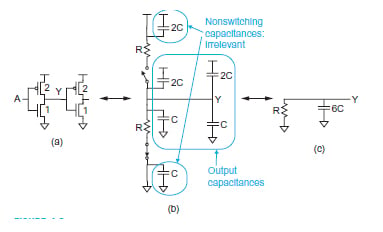
图 1.所有图像改编自CMOS VLSI 设计(第 4 版)1,作者 Neil HE Weste 和 David Money Harris
由于反相器的PMOS晶体管尺寸为2倍单位,NMOS为单位宽度,因此它通常为驱动电路提供总计3C的输入电容。
回顾一下,当输入为高电平 (3.3V) 时,NMOS(底部晶体管)导通,并在将输出电压下拉至地 (0V) 的同时提供“R”电阻。但是,当输入为低电平 (0V) 时,PMOS(顶部)导通,并且在将输出电压拉至高电平 (3.3V) 的同时还提供 R 的电阻。
这意味着,在上升/下降转换中,等效 RC 电路的有效电阻为“R”。同时,每个晶体管(3C)的总电容不随晶体管的变化而变化。由于我们有两个逆变器级联在一起,它们总共提供 6C 的电容。
为 3 输入与非门调整晶体管大小
为了进一步了解晶体管在逻辑门中的大小,让我们看一下 3 输入与非门。
作为参考,如果任何输入为低电平,与非门将提供高电平输出。相反,当所有输入均为高电平时,输出将为低电平。这为我们提供了三个并联的 PMOS——只有一个 PMOS 足以将输出电压拉至高电平——以及三个串联的 NMOS——这三个 NMOS 需要先导通才能将输出电压拉至低电平。
为了有效地调整每个晶体管的尺寸,我们必须注意,电路中的晶体管尺寸必须以 NMOS 部分提供单位电阻“R”而 PMOS 部分必须提供两倍单位电阻“2R”的方式确定以确保相等的上升/下降时间。
由于三个 NMOS 晶体管串联连接,它们的总电阻必须为 ((frac{R}{3} + frac{R}{3} + frac{R}{3} = R))其中 k = 3。由于只有一个 PMOS 足以将输出拉至高电平,因此在坏情况下,每个 PMOS 晶体管保持有效电阻 (frac {2R}{2} = R ) 其中 k = 2.( R 3+ R 3+ R 3= R )(R3个+R3个+R3个=R)2对2= R2个R2个=R
在上升/下降晶体管处,每个输入将呈现 5C 的输入电容,而输出端 Y 的总输出电容为 (2C+2C+2C+3C = 9C)。
向前推进,可以开发等效 RC 电路以给出图 2(c) 和 2(d) 中所示的电路。
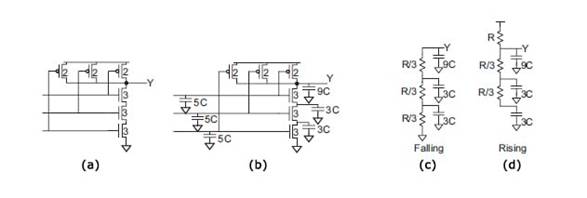
图 2。
下降过渡 (2(c)) 显示所有 NMOS 晶体管都需要导通,而上升过渡 (2(d)) 显示坏情况,其中一个 PMOS 导通同时两个 NMOS 晶体管导通, ,有助于电路的总电容。
评估电路的瞬态响应:传播延迟、STC 和 TTC
在推导出合适的等效 RC 电路后,下一步是检查电路的瞬态响应。如果我们检查下面图 3 中所示逆变器的等效 RC 电路,目标是估计在输出端看到输入电压的时间。
施加输入 (V DD) 与输出 (frac {V_{DD}}{2})之间的时间称为传播延迟。传播延迟的表达式可以从给出的一阶电路的经典传递函数导出:V D D 2V丁丁2个
买电子元器件现货上唯样商城
H ( s ) = 1 1 + s R CH(秒)=1个1个+秒RCV o u t = V D D e ? t R CVo你吨=V丁丁电子?吨RC
因此,传播延迟是瞬态响应的时间常数 (τ),即:
t p d = R C吨pd=RC
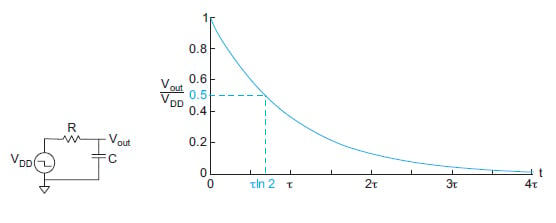
图 3。
从图 3 中的延迟响应来看,目标是将传播延迟推至接近于零以生成总体上更快的电路。在文献中,这种方法通常被称为单时间常数(STC) 方法,这是一种估算电路延迟的简单方法。
然而,这种方法在估计较大电路的延迟时似乎不准确,这导致了双时间常数(TTC) 近似的发展,由于第二个时间常数,它使我们有机会获得更好的延迟估计。
检查上面讨论的 3 输入与非门,其 RC 电路可以如图 4 所示给出。
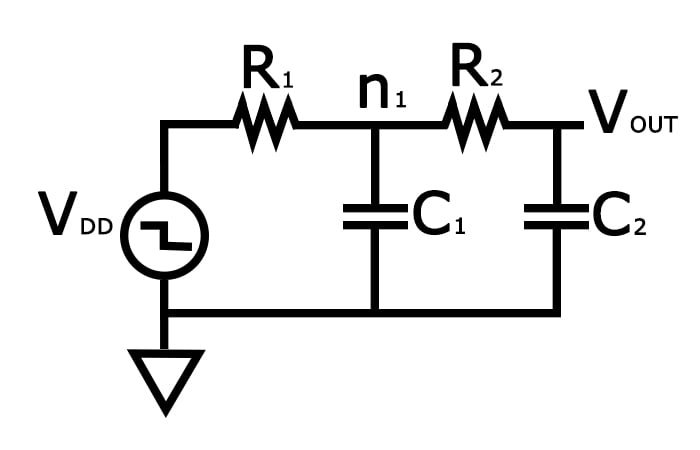
图 4。
该电路的阶跃响应为
H ( s ) = 1 1 + s [ R 1 C 1 + ( R 1 + R 2 ) C 2 ] + s 2 R 1 C 1 R 2 C 2H(秒)=1个1个+秒[R1个C1个+(R1个+R2个)C2个]+秒2个R1个C1个R2个C2个
和
V o u t (t)= V D D τ 1 e ? τ τ 1? τ 2 e ? τ τ 2τ 1 ? τ 2Vo你吨(吨)=V丁丁τ1个电子?ττ1个?τ2个电子?ττ2个τ1个?τ2个
在哪里
τ 1 , 2 = R 1 C 1 + ( R 1 + R 2 ) C 2 2[ 1 ± √ 1 ? 4 R * C * [ 1 + ( 1 + R * ) C * ] 2]τ1个,2个=R1个C1个+(R1个+R2个)C2个2个[1个±1个?4个R*C*[1个+(1个+R*)C*]2个]
和
R * = R 2 R 1; C * = C 2 C 1R*=R2个R1个;C*=C2个C1个
但由于 TTC 近似的复杂性,这违背了将 CMOS 电路延迟简化为简单 RC 网络的目的。然而,它可以通过 STC 模型进行简化,给出一个近似的时间常数 (τ)。
τ = τ 1 + τ 1 = R 1 C 1 + ( R 1 + R 2 ) C 2τ=τ1个+τ1个=R1个C1个+(R1个+R2个)C2个
单时间常数 (STC) 与双时间常数 (TTC)
根据 Mark Alan Horowitz1 的说法,如果性常数明显大于另一个,则此近似值有效。
然而,根据 Neil HE Weste 和 David Money Harris2 的说法,这种近似被认为会产生 7%-15% 的误差,因此不能给出中间节点的准确延迟描述。
这篇关于VLSI 设计中的线性 RC 延迟模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








