本文主要是介绍朴素贝叶斯(右心室肥厚的辅助识别),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
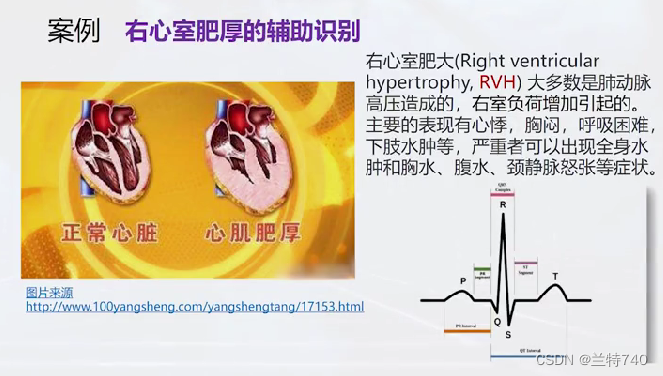

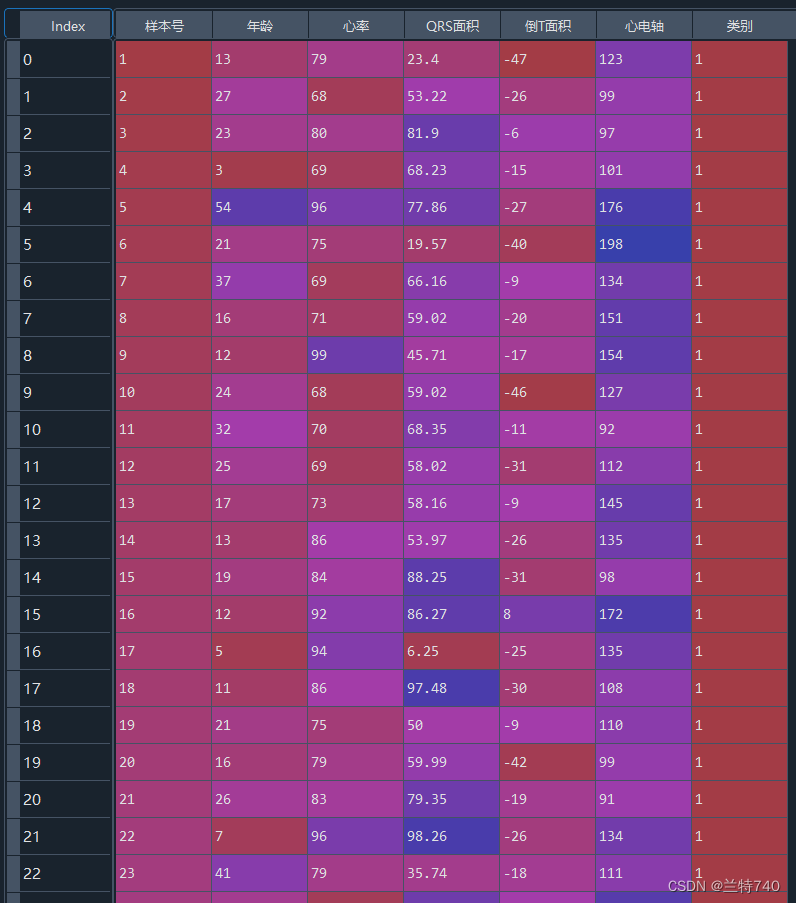
现在我们判断右心室是否肥厚通常的做法都是借助心电图来识别,左侧的是右心室肥厚的,右侧的是右心室厚度正常,那接下来就要按照给出的图像来处理特征,提取出正常组和肥厚组的不同特征。
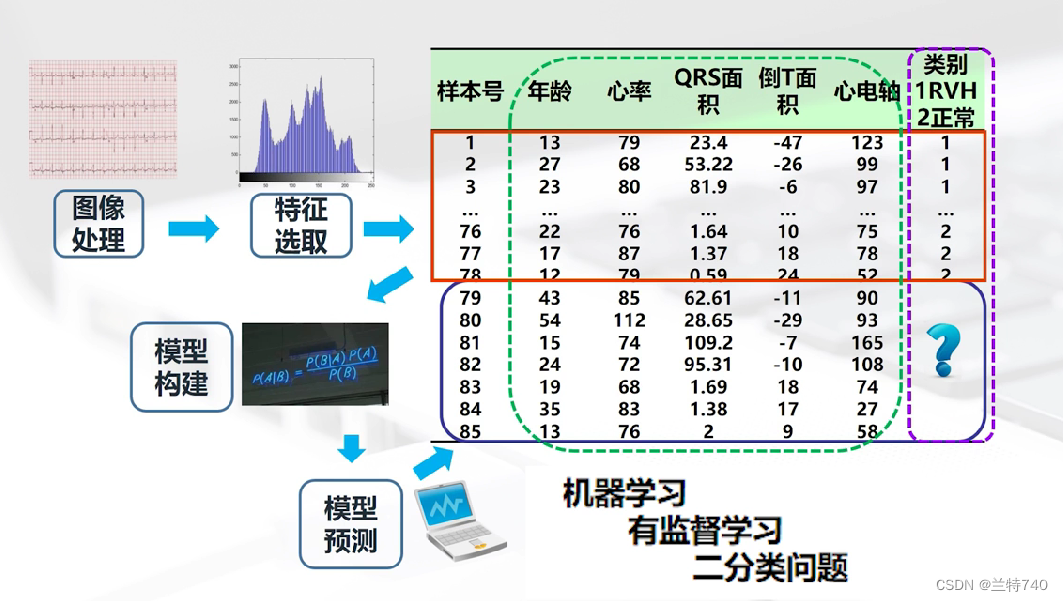
根据上图我们可以得出通过图像提取出了年龄、心率、心电轴等多个不同的特征,右侧前78行是有类标号的,代表正常与不正常,后边7行没有类标号是需要训练的模型进行预测的。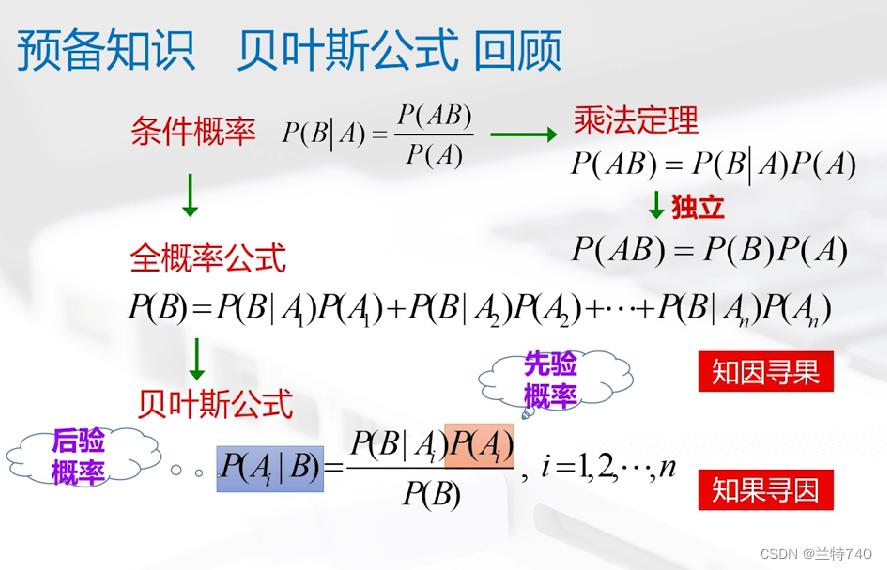
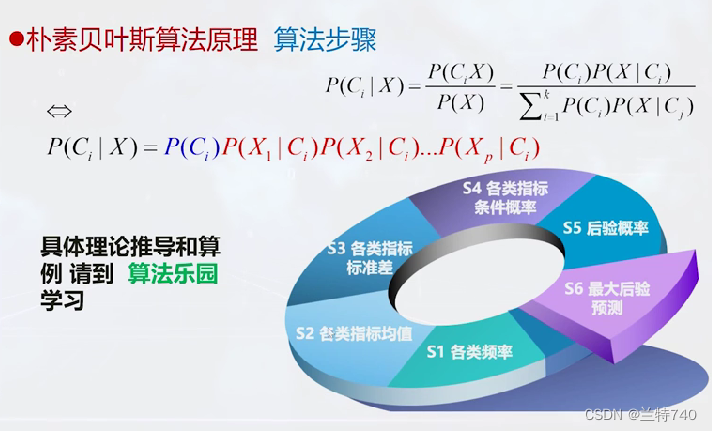
要计算贝叶斯公式需要的预备知识有条件概率、全概率公式和贝叶斯公式,全概率公式主要有在知道有 A1 到 An 等 n 个条件下,分别求这些条件下B发生的概率是多少,最终求总的 B 发生的概率为多少,也就是全概率公式。

在这个公式中X就是总的样本,Ci 就是要求的样本所属的类别,计算样本归属于某个类别的概率不会达到100%,所以现在要计算的就是其归属于哪个类别的后验概率最大就将其归属于哪个类别。

argmax 是numpy和其他库中的一个常用函数,它的作用是:
从数组或者列表中返回最大值所在的索引位置。
基本语法如下:
import numpy as np
arr = np.array([5, 2, 8, 3])
index = np.argmax(arr)
print(index)
# 输出 2
这里arr数组中的最大值8位于索引2的位置,所以argmax返回2。
另一个例子:
import numpy as np
a = np.array([[1,2,3], [4,5,6]])
index = np.argmax(a)
print(index)
# 输出 5
对于二维数组,它返回的是整个数组的最大值元素的索引位置。
argmax常见的使用场景有:
- 在机器学习中,找到概率预测最大的类别
- 在数组搜索中,找到目标值的索引
- 获取数组或者序列的最大值
所以argmax一个很有用的函数,可以快速定位到数组或序列的最大值元素。
对于所有的类别来说,它的分母的值也就是全概率的值是相同的,是一个常量;所以我们只需要对分子进行求解。


'''step1 调用包'''
import pandas as pd
from sklearn.model_selection import train_test_split
#朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
#调用准确率计算函数
from sklearn.metrics import accuracy_score '''step2 导入数据'''
data = pd.read_excel('data_RVH.xlsx')'''step3 数据预处理'''
# 把带类标号数据(用于训练和检验)
# 和待判(最后7行)数据分开
data_used = data.iloc[:78,1:]
#Python从0开始计数,故上一行代码从第0行取到第77行
#共提取了78行。#最后7行为待判集合
data_unused = data.iloc[78:,1:]
'''step4 划分数据集'''
#(将带类标号数据
#划分为训练集(75%)
#和检验集(25%)#将类别列和特征列拆分,
#便于下面调用划分函数
y_data=data_used.iloc[:,5]
x_data=data_used.iloc[:,:5]#调用sklearn中的函数划分上述数据
x_train, x_test, y_train, y_test = train_test_split(x_data,y_data,test_size=0.25,random_state=0)'''step5 模型计算(训练、检验、评价)'''
#step5.1 训练模型
model_NGB = GaussianNB()
model_NGB.fit(x_train, y_train)#step5.2 检验模型
pred_test = model_NGB.predict(x_test)#step5.3 模型评价(准确率)
#这里y_test为真实检验集类标号
#pred_test为模型预测的检验集类标号
#比较二者即可得到准确率
acc_test = accuracy_score(y_test,pred_test)
print('检验准确率为:',acc_test)'''step6 预测结果'''
#模型训练完,检验效果满意,即可对最后7行
#未知类别样本进行预测(分类)
x_unused = data_unused.iloc[:,:5]
pred_unused = model_NGB.predict(x_unused)
print('待判样本预测类别为:',pred_unused)
以上是程序求解的全过程,下边我们分步来求解一下。
1.调用必要的包
'''step1 调用包'''
import pandas as pd
from sklearn.model_selection import train_test_split
#朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
#调用准确率计算函数
from sklearn.metrics import accuracy_score
这里我们调用的是朴素贝叶斯分类器中的高斯贝叶斯分类器
2.读入数据
'''step2 导入数据'''
data = pd.read_excel('data_RVH.xlsx')
3.数据预处理
'''step3 数据预处理'''
# 把带类标号数据(用于训练和检验)
# 和待判(最后7行)数据分开
data_used = data.iloc[:78,1:]
#Python从0开始计数,故上一行代码从第0行取到第77行
#共提取了78行。
#最后7行为待判集合
data_unused = data.iloc[78:,1:]
将用于训练检验和预测的数据划分开来。
4.划分数据集
'''step4 划分数据集'''
#(将带类标号数据
#划分为训练集(75%)
#和检验集(25%)
#将类别列和特征列拆分,
#便于下面调用划分函数
y_data=data_used.iloc[:,5]
x_data=data_used.iloc[:,:5]#调用sklearn中的函数划分上述数据
x_train, x_test, y_train, y_test = train_test_split(x_data,y_data,test_size=0.25,random_state=0)
5.模型计算
'''step5 模型计算(训练、检验、评价)'''
#step5.1 训练模型
model_NGB = GaussianNB()
model_NGB.fit(x_train, y_train)#step5.2 检验模型
pred_test = model_NGB.predict(x_test)#step5.3 模型评价(准确率)
#这里y_test为真实检验集类标号
#pred_test为模型预测的检验集类标号
#比较二者即可得到准确率
acc_test = accuracy_score(y_test,pred_test)
print('检验准确率为:',acc_test)
调用模型之后训练模型、检验模型再得到模型计算的准确率。
6.预测结果
'''step6 预测结果'''
#模型训练完,检验效果满意,即可对最后7行
#未知类别样本进行预测(分类)
x_unused = data_unused.iloc[:,:5]
pred_unused = model_NGB.predict(x_unused)
print('待判样本预测类别为:',pred_unused)
将刚才最后未加类标号用于预测的数据预测出来。
这篇关于朴素贝叶斯(右心室肥厚的辅助识别)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!