本文主要是介绍Ultra-high Resolution Image Segmentation via Locality-aware Context Fusion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
极高图像语义分割。
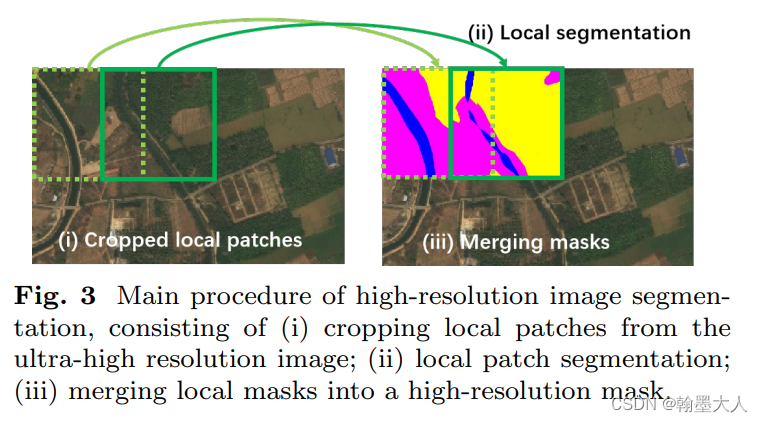
作者使用了一个高分辨率分割的pipeline,将原始的超高分辨率图像分成一块一块的用于局部分割,然后将局部的分割结果融合形成最终的高分辨率分割。
方法:1:作者引入了一个局部感知上下文融合(LCF)用于处理局部块:2:作者提出了交替局部增强模块(ALE)去完善产生的结果。
其中LCF模块用于研究局部快和上下文区域之间的关系,LCF块包含两步,局部感知上下文关系(LCC),和多尺度上下文融合(MCF)。
LCC设计是用来捕捉局部和全局的位置关系,MCF是用来平衡和结合不同尺度背景下的局部特征。但是不同尺度的背景下计算局部特征将会带来大量的冗余信息,为了去解决这个问题,提出了ALE,通过对多尺度上下文进行剪切和上缩放局部特征来避免冗余信息。
模型的主要处理流程:
模型整体的结构:
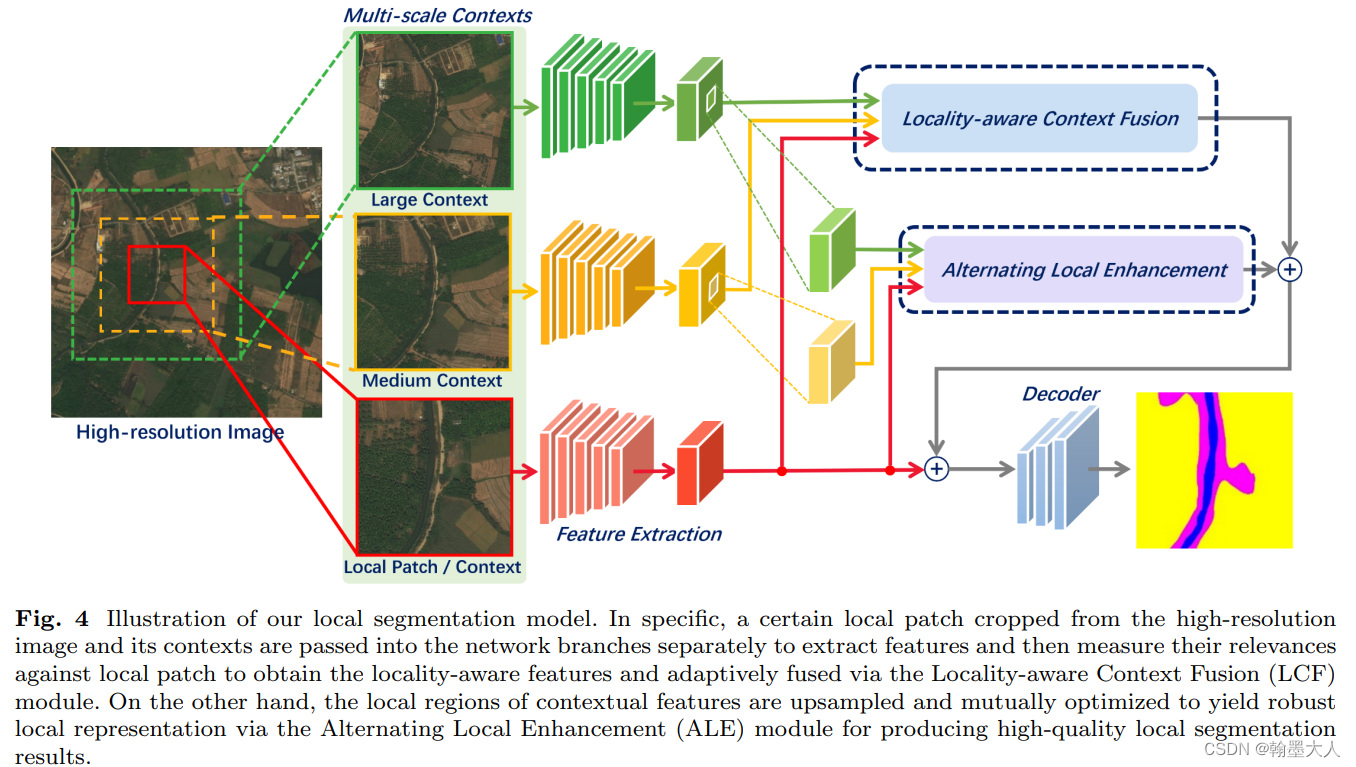
模型包含了三个encoder-decoder特征提取器,不同大笑的上下文区域通过缩放到相同的大小来较少计算量,然后送入到网络中用于特征的提取,经过提取的特征再分别送入到LCF和ALE,去增强局部特征。最后输入到decoder中。
patch是如何选取的:

**LCF:**包含LCC和MCF
LCC:设localpatch为I,中等背景为M,大背景为L。
I和他的背景U可以通过外积来计算相关性,通过建立逐像素的关系。下图的左半部分。
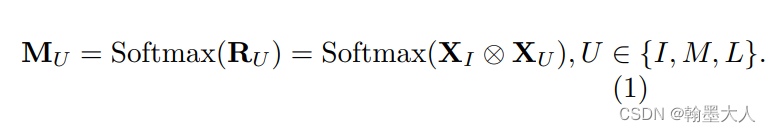
因为Mu是位置不可知的,包含了大量的无效信息,为了结合位置信息,其中一个方法是增加位置编码,作者使用门控位置编码动态的传递相对位置信息。M可以重新计算为:
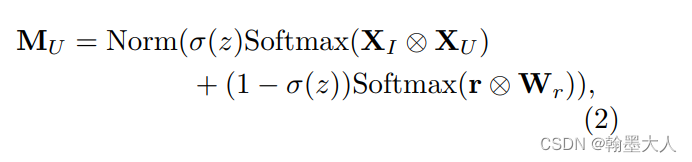

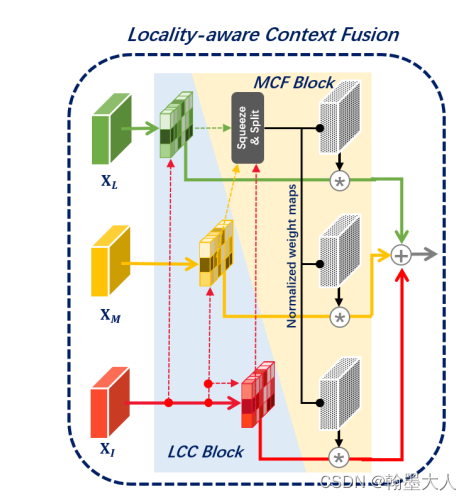
MCF:多背景融合
通过特征提取和LCF模块,我们可以获得局部特征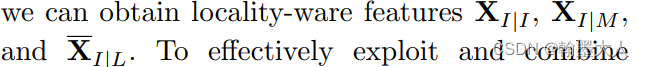
为了有效的结合和利用局部特征,我们提出了MCF模块,所有的特征首先拼接起来,然后通过一个压缩和分离模块,首先将拼接起来的特征通过1x1卷积进行压缩,然后压缩的特征通过1x1卷积重建到原始的维度,然后通过softmax获得三个权重图。生成的权重图再与结果图相乘,最后相加。
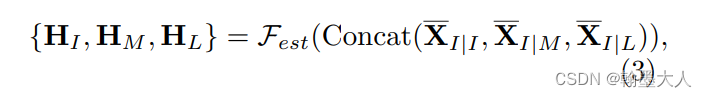

ALE:交替局部增强
ALE作用可视化:

ALE结构:
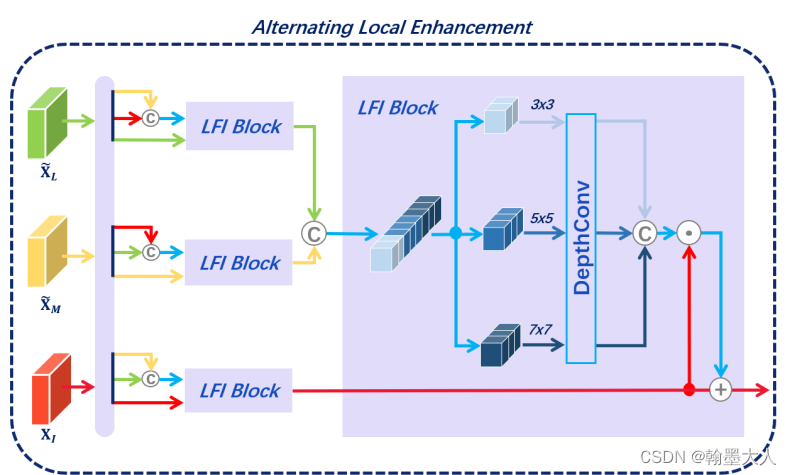
ALE是为了减少LCF产生的错误信息,使用局部特征交互模块(LFI)优化上下文特征,最终产生一个更加清晰的局部表征。LFI基于空间注意力机制,通过不同大小的卷积核,有效的使用不同的参考特生优化目标特征。
L,M,I其中两个作为参考,剩下的一个作为目标。

参考特征经过1x1卷积生成token,然后经过拼接生成参考特征,再进过一个卷积生成注意力图。和传统的卷积不同,我们使用不同窗口大小的卷积核,可视化不同大小的卷积核:

我们将拼接后的参考特征进行切片,然后通过逐深度卷积。生成Xtar。

实验:backbone采用的segformer和VGG16.
这篇关于Ultra-high Resolution Image Segmentation via Locality-aware Context Fusion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








