本文主要是介绍HBase MemStore刷写(flush)时机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 准备知识
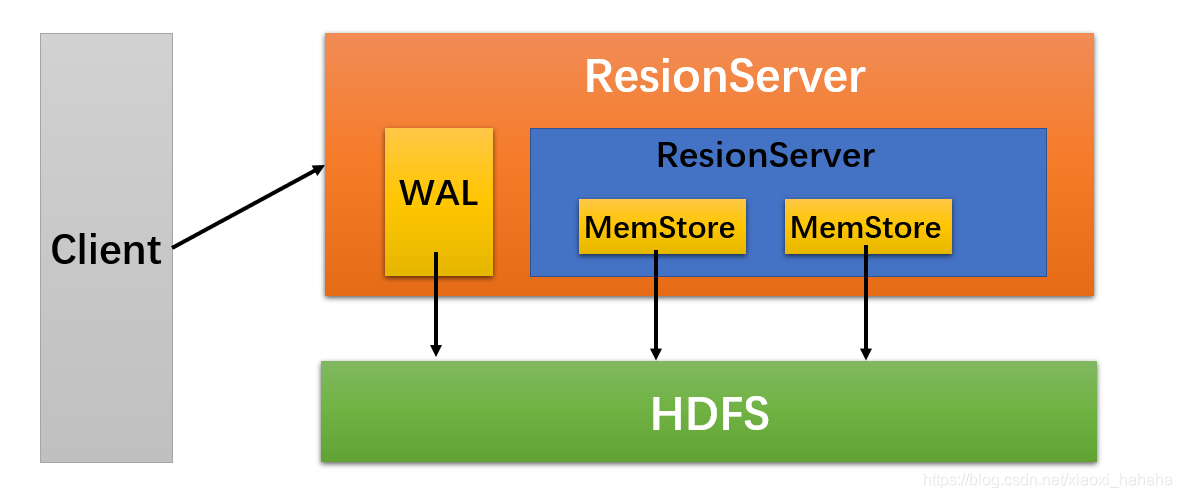
(1)HBase上RegionServer的内存分为两个部分,一部分作为MemStore,主要用来提供给用户写数据;另一部分作为BlockCache,主要用来提供给用户读数据。
(2)在ResionServer上存放着Region,每一个Resion存储着一些列。根据其列族的不同,将这些列数据存储在相应的列族(Column Family)中。
(3)每一个列族(简称CF)都存储在各自的HStore中。HStore由MemStore和HFile组成
(4)MemStore位于ResionServer的内存中,HFile被写入到HDFS(Hadoop 分布式文件系统)中。
(5)当ResionServer处理写请求的时候,数据首先写到MemStore,然后当满足某种条件后,MemStore中的数据会被刷写(flush)到HFile中。
(6)每做一次刷写操作,就生成一个HFile(Store File)文件。
(7)一个RegionServer可能包含多个region,每个region可能包含多个HStore,每一个HStore又由MemStore和HFile组成。
(8)RegionServer是JVM的一个进程,启动时可以向JVM申请栈的大小。
二 RegionServer刷写(flush)的时机
(1)情况一:当某台RegionServer内存中所有MemStore的总和大小超过指定的值时,便会触发刷写。
在hbase-default.xml文件中,我们可以看到如下的配置,当在这种条件触发读写的时候,客户端不允许读写。

(2)情况二:当满足hbase.regionserver.global.memstore.size值的0.95后,开始触发刷写条件
可以理解为一个安全的设置,有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。 在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小, 这个大小就是默认值是堆大小 * 0.4 * 0.95,也就是当regionserver级别 的flush操作触发后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止。

(3)情况三:指定从内存最后一次编辑之后,隔多长时间进行刷写,默认是1小时
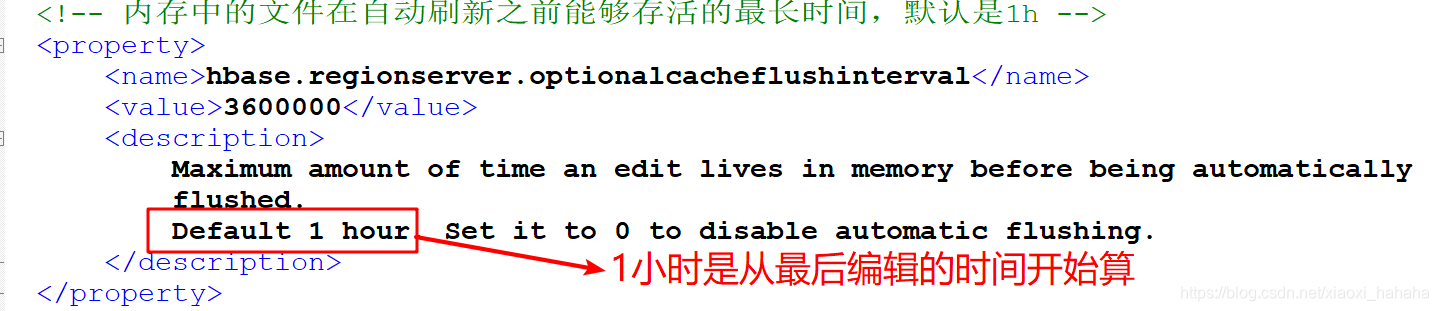
以上的都是针对RegionServer级别的
(4)情况四:region级别的刷写,当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。

这篇关于HBase MemStore刷写(flush)时机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![笔试强训,[NOIP2002普及组]过河卒牛客.游游的水果大礼包牛客.买卖股票的最好时机(二)二叉树非递归前序遍历](https://i-blog.csdnimg.cn/direct/17efc4d0a1b749cb89ebdd715e23402b.png)


