flush专题

cache flush和cache invalid区别
“Cache flush”和“Cache invalidation”是两种管理缓存的操作,尽管它们有一些相似之处,但在作用和使用场景上有所不同。 ### Cache Flush - **定义**: Cache flush 是指将整个缓存清空,也就是移除缓存中的所有数据。所有缓存的内容都会被删除,缓存回到一个空的状态。 - **使用场景**: Cache flush 通常在以下情况下使用: -

ends,flush,endl 用法区别
ends函数 终止字符串flush函数 刷新缓冲区endl函数 终止一行并刷新缓冲区#include <iostream>int main(){using namespace std;cout << "a" ;cout << "b" <<ends;cout << "c" <<endl;cout << "e" << flush;cout << "f" << flush;cout << "g"

Lucene随笔-记录一下自动flush的触发条件
Luncene 6.5.1 在lucene中flush存在两种flush:主动flush与自动flush。那么在哪些情况下会触发自动flush呢? MaxBufferedDocs MaxBufferedDocs描述了索引信息被写入到磁盘前暂时缓存在内存中允许的文档最大数量,也就是每个DWPT缓存的最大文档数量,当一个DWPT中的文档数量超过这个值时会触发自动flush,该参数在建立In
session.flush方法到底干了一些什么事情,举一个具体的例子说明
session.flush方法到底干了一些什么事情,举一个具体的例子说明? 答:session.flush将缓存中的持久化对象转换成sql语句,向数据库中执行sql语句,并清空缓存
NHibernate2.1中Flush的调用模式(转自http://blog.csdn.net/nileel/archive/2009/09/23/4583652.aspx)
有很多NHibernate的初学者搞不清Flush()这个方法调用的时机和策略。 事实上,ISession有个叫FlushMode的属性,对其赋值即可控制调用Flush()的时机和策略。 那么具体赋什么值对应什么策略呢?NHibernate提供了一个枚举类型。其代码和注释如下: using System; namespace NHibernate { // 摘要: //
Hibernate的flush效率问题
程序中使用了声明式事务管理,所有service中以add打头的配置是PROPAGATION_NOT_SUPPORTED,每个请求过来产生100个更新,当service处理完毕后,hibernate会把数据刷新到数据库,这个刷新的过程非常消耗时间。偶然间把事务的传播属性改成了PROPAGATION_REQUIRED,刷新到数据库的速度反而快了。暂时不知道为什么。。。 APPARENT DE
unblock with ‘mysqladmin flush-hosts‘ 解决方法
MySql Host is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts' 解决方法 环境:linux,mysql5.5.21 错误:Host is blocked because of many connection errors; unblock with 'mysqladmi
hibernate的save,persis,update,saveOrUpdte,merge,flush,lock等区别
一,比较merge与update的区别 首先, merge作用大致相当于saveorupdate这个方法, 即有唯一性标识, 则运行save, 没有则运行update 下面来比较2者的区别, update(object), 方法运行后, object是持久化状态, 而Object obj = merge(object), 方法运行后, object是脱管状态, obj是持久化状态
Hibernate Session的Flush模式
Hibernate会尽量将与数据库的操作延迟,直到必须要与数据库进行交互,例如save方法一般会在提交时才真正执行,最终在提交时会以批处理的方式与数据库进行交互,以提高效率。 而将操作延迟,就是利用缓存,将最后要处理的操作放到缓存中。 flush方法的主要作用就是清理缓存,强制数据库与Hibernate缓存同步,以保证数据的一致性。它的主要动作就是向数据库发送一系列的sql语句,并执行这
关于文件读写缓存的问题(flush的使用场景)
核心提示: 根据linux操作系统定义,底层的文件的write()方法是会进行缓存的 当用python或者java操作文件时,尤其是需要又读又写同一个文件的,比如: 我需要从头先读这个文件f1,同时往这个f1 又需要向末尾添加写,同时还要保证,内容不能重复,当需要执行很多次这种操作时,这个时候如果不考虑,文件底层的缓存问题,极有可能出现重复内容,即使你已经做了重复性检测,而且重复内容不是很多
MySQL参数:innodb_flush_log_at_trx_commit 和 sync_binlog
innodb_flush_log_at_trx_commit 和 sync_binlog 是 MySQL 的两个配置参数,前者是 InnoDB 引擎特有的。之所以把这两个参数放在一起讨论,是因为在实际应用中,它们的配置对于 MySQL 的性能有很大影响。 1. innodb_flush_log_at_trx_commit 简而言之,innodb_flush_log_at_trx_comm
设置Flush刷新模式setFlushMode()
6.2.8 设置Flush刷新模式setFlushMode() 上面的flush()函数是手动调用的,如果不手动调用,则只能依赖于容器的自动刷新。在默认情况下容器是自动刷新的,这是因为它对应了刷新了的AUTO值: public enum FlushModeType { AUTO, COMMIT } 我们可以调用下面的方法改变刷新模式: em.setFlushM

innodb_flush_log_at_timeout
文档解释 innodb_flush_log_at_timeoutProperty ValueSystem Variable innodb_flush_log_at_timeoutScope GlobalDynamic YesType integerDefault Value 1Minimum Value 1Maximum Value 2700Write
多线程回放+flush tables with read lock 死锁
文章目录 多线程回放+flush tables with read lock 死锁一、场景描述二、死锁排查三、解决办法四、如何复现的? 多线程回放+flush tables with read lock 死锁 一、场景描述 MySQL-5.7.18 slave实例上夜间进行备份操作时, processlist 结果,只列出关键部分 mysql> show processl
mysql connect unblock with mysqladmin flush-hosts
原因 同一个ip在短时间内产生太多(超过max_connect_errors的最大值)中断的数据库连接而导致的阻塞。 查看 max_connect_errors show variables like 'max_connect_errors'; 解决 前提:需要换一个IP地址连接 方法一 增大 max_connect_errors set global max_connect_er
flush privileges;的时候error 1033 (hy000) incorrect information in file: './mysql/table_priv.frm'
出现这个问题,一定要记录下来,我设置mysql远程访问时候,最后一句flush privileges出现错误,error 1033 (hy000) incorrect information in file: './mysql/table_priv.frm',目前正在想办法中,求解啊,有答案一定要记录下这个

MySQL 8.0 引入 innodb_flush_method 等新参数的系统调用分析
本文我们将讨论如何在操作系统级别验证 innodb_flush_method 和 innodb_use_fdatasync 修改为默认值之外的其它值(特别是 O_DIRECT 是最常用的)后的效果。 介绍 首先,让我们定义该 innodb_flush_method 参数的作用。它规定了 InnoDB 如何管理数据刷新到磁盘的行为。文章不会详细说明每个有效值的作用,更多详细介绍请查看参数值文档。
[SXT][WY]Hibernate06 Session Flush
session flush测试: session flush方法主要做了两件事: * 清理缓存 // 注意!:一个对象在session中保存有两份。一份是临时的用于生成sql语句的,一份是持久的。 // flush只是清理了那个临时的对象,不清理持久的 // evict是清理持久的,不清理临时的。 * 执行sql
关于java的flush
java中在write()方法后尽量手动调用flush()方法,原因呢: 这里首先应该对I/O对计算机体系结构要有一个简单的了解,计算机分为运算器、控制器、存储器、输入/输出。cpu由运算器、控制器和寄存器等等组成。存储器分为内存和外存,这里简单说一下I/O。 I/O主要是对外存的读/写,而cpu的速度远远大于I/O,此时就有很多策略解决,这时将数据加入缓冲区是一个高效的方法,这样减少了cpu的I
MySQL中FLUSH TABLES命令语法
在MySQL中,FLUSH TABLES 命令的作用是刷新表。当你使用 FLUSH TABLES 命令的具体选项时(例如 FLUSH TABLES WITH READ LOCK),该选项必须是在 FLUSH 语句中唯一指定的命令。即,在一个 FLUSH 语句中,你只能使用单一的 FLUSH TABLES 选项。此外,FLUSH TABLE 是 FLUSH TABLES 等价的。 注意: 对于描述
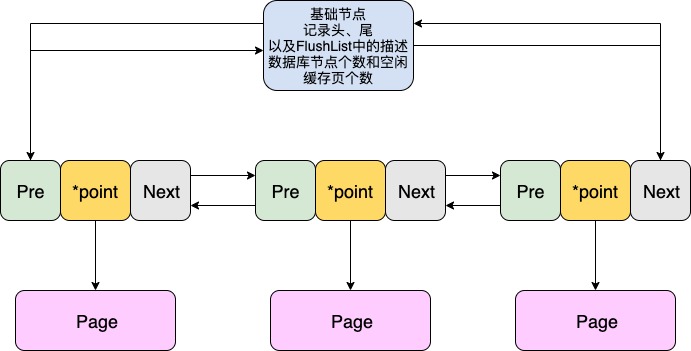
mysql数据落盘详解_MySQL的Flush-List和脏页的落盘机制
一、回顾 MySQL启动后Buffer Pool会初始化。Buffer Pool也会初始化好N多个空白的缓存页,以及它们的描述数据会被组织成LRU链表以及FreeList 双向链表。 这时你从磁盘中读取一个数据页,会先从Free List中找出一个空闲缓存页的描述信息,然后将你读出的数据页中加载进缓存页中。同时将缓存页的描述信息从Free List中剔除,此外该描述信息块还会被维护进LRU链表中
C#中 Flush Dispose和Close的区别!
【个人学习过程记录,不一定准确】 想知道,C#中的文件缓冲的 流是什么意思?Flush() 执行的时候,究竟做了什么,流程是什么啊 缓冲区干嘛的 你写了一个程序,其中要对硬盘上的一个文件操作,FileStream

关于mysqladmin flush-hosts问题的解决
问题 最近在排查一个线上项目问题时发现,有一个同步资源状态的模块无法连接数据库 分析 当数据库发现连接数据库的错误连接数超过了规定的数量时,会拒绝客户端发起新的连接,使用mysqladmin flush-hosts命令可以清除数据库缓存信息。使用show variables like ‘%conn%’;命令可以查看当前数据库允许的最大错误连接数 可以通过命令set global max_

HBase – Memstore Flush、StoreFile、File解析
Memstore Memstore 概述 Memstore是HBase框架中非常重要的组成部分之一,是HBase能够实现高性能随机读写至关重要的一环。深入理解Memstore的工作原理、运行机制以及相关配置,对hbase集群管理、性能调优都有着非常重要的帮助 HBase中,Region是集群节点上最小的数据服务单元,用户数据表由一个或多个Region组成。在Region中每个C