本文主要是介绍Image Splicing Localization Using Superpixel Segmentation and Noise Level Estimation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2019 12th International Congress on Image and Signal Processing,
BioMedical Engineering and Informatics (CISP-BMEI)
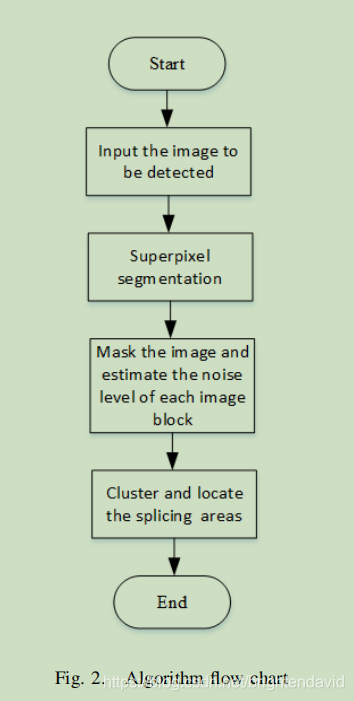
根据超像素划分每个图像块,
对每个图像块 求噪声水平,
对于上面的图像块-噪声水平 求聚类
默认,小的聚类是篡改区域,大的聚类是原本的背景。
超像素分割有很多的好处,能够划分边界。使用超像素划分图像直接就简化问题。但是splicing里面也有一些路子很野的,不考虑语义信息,乱篡改图像的,这种情况可能就会出现问题了。 因为此时,篡改区域可能被分到不同的超像素中, 这种情况是可行的,因为是聚类。
但是大面积的篡改会出现问题,二义性的问题。无法分清篡改区域。灾难性的后果是完全预测反了,指标全部飙0.
噪声水平分析:
图像的噪声通常均匀的分布在图像中,如果引入其他图像的图像块,那么splicing 区域的噪声水平将会完全不同。依据此原理,分析篡改的区域。一般是基于块的方法。

这篇关于Image Splicing Localization Using Superpixel Segmentation and Noise Level Estimation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









