本文主要是介绍达观杯数据竞赛项目--初识word2vec,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 初识词向量表示:word2vec
- 1. 课程计划
- 1.1 词义(word meaning)
- 构造词汇的相似性关系(distributional learning)
- 1.2 word2vec简介
- 1.2.1 Skip-gram model
- 1.2.2 Skip-gram 框架结构
- 1.2.3 参数矩阵更新的相关推导
- 1.3 小结
- 2 gensim实现word2vec
- 2.1 gensim 简介
- 2.2 基于model的一些操作
- 2.3 竞赛数据分词
- 3. 参考资料
初识词向量表示:word2vec
- CS224n 斯坦福NLP视频课程内容==》link
1. 课程计划
1.1 词义(word meaning)
词义通常是通单词、短语等表示的想法;在语言学中,单词像是一种语言学符号,用于指代某些具体的物品。
在计算机中常用分类资源来处理词义,例如用WordNet来处理英语词语的分类,包括查询上义词和同义词等。wordnet作为一个资源词典固然很好,但仍存在一些问题,例如:语义之间细微的差别(如同义词)、不能自动更新、缺少主观的选择、很难对词汇的相似性给出准确定义;这是离散化表征普遍存在的一个问题。
在现阶段的NLP研究中常使用原子符号去表征单词,就是常说的one_hot,但这种表述没有表示出任何词汇之间的内在关系概念,例如:web搜索中,我们想搜索Seattle motel,那么最终的匹配可以是"seattle hotel",因为 motel 和 hotel 是近义词,但one
hot 编码输出的两个vector 点积为0,即认为两者没有内在的联系。因此为解决这种问题,我们必须建立词汇之间的相似性关系。
构造词汇的相似性关系(distributional learning)
distributional similarity 分布相似性是指可以通过观察上下文得到大量表示某个词汇含义的值,基于此概念,为每个单词构造一个稠密向量,使之预测目标单词所在文本的其他词汇。
1.2 word2vec简介
我们通常会定义一个模型并根据中心词汇wt 预测它上下文的词汇w_t 来学习神经词嵌入问题,loss function = 1 - p(w_t | wt) ,word2vec 的基本应用是利用语言的意义理论去预测中心词汇和上下文的单词。目前,word2vec 已经被编译成一套软件,包含两个用于生成词汇向量的算法(Skip-gram 和 Continuous Bag of Words)及两套效率中等的训练方法(Hierarchical softmax 和 Negative sampling),故在提及word2vec时指的是其背后用于计算vector的skip_gram和CBoW模型
两种模型:
- skip-gram : 预测上下文
- CBOW : 预测目标单词
CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好
两种高效的训练方法:
- Hierarchical softmax
- Negative sampling
1.2.1 Skip-gram model
在每一个估算步都取一个词作为中心词汇,用概率表示某个单词在中心词上下文出现的概率,这里选取词汇的向量表示以让概率分布值最大化。
需注意对同一个词汇有且仅有一个条件概率分布(词袋模型,与位置无关)

目标函数:计算每个词在给定中心词附近(步长为m的窗口内)出现的最大概率

其中m为窗口大小,theta 表示词向量;在实际求解时将目标函数做一个对数似然的转化,得到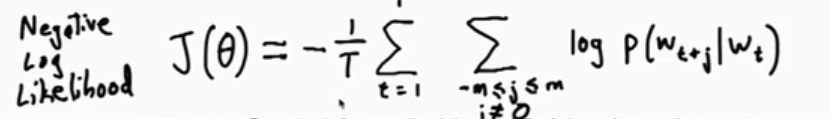
- 求解 p ( w t + j ∣ w j ) p(w_{t+j}|w_j) p(wt+j∣wj)
根据由单词向量构造而成的中心词汇 求解 上下文的概率分布。

这里的o是outside(或者output)单词索引(下标),c是中心词的索引(下标), U o U_o Uo是索引为o的单词所对应的向量, V c V_c Vc是中心词汇对应向量
注:处理上下文文本时,关心的仅仅是该单词的ID在窗口中的位置
上下文条件概率 p ( w t + j ∣ w j ) p(w_{t+j}|w_j) p(wt+j∣wj)采用 softmax 函数去构造概率分布:利用点积去衡量相似性,利用softmax将实数域等比例映射到概率范围
softmax之所叫softmax,是因为指数函数会导致较大的数变得更大,小数变得微不足道;这种选择作用类似于max函数
1.2.2 Skip-gram 框架结构
下图为一个完整的Skip-gram 模型

首先输入 中心词的one-hot词向量 w t w_t wt,将其乘以weight Matrix (W) ,得到中心词的词义表达 V c = W w t V_c = W_{w_t} Vc=Wwt,再乘以临近词(context word)的weight Matrix 矩阵W’ 得到对每个词语的“相似度”,对相似度取softmax得到概率。
最终要求的就是两个矩阵W和W’,在训练完毕之后,W和W’均包含一定的语义信息。
1.2.3 参数矩阵更新的相关推导

上述是对中心词部分的求导,还需对 u o u_o uo求导
实际上对 v c v_c vc求偏导是为了计算W的梯度,对 u o u_o uo求偏导是为了计算W‘的梯度,用于后续的参数更新。下图是link给出的一个推导:

1.3 小结
word2vec是基于网络的一种无监督模型,从语料库中随机抽取某个句子中的某个词 w c w_c wc,将中心词前后m个单词的集合作为一个window。skip-gram模型希望预测 w c w_c wc 附近是什么词,而CBOW模型希望用window中的词预测 w c w_c wc 。
2 gensim实现word2vec
2.1 gensim 简介
Gensim是一款用于处理NLP的python包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。
它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,
支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口
使用gensim做Word2vec时,只需调用gensim.models.Word2Vec()函数即可,这里主要介绍一些模型内部的参数,参考link。
gensim 的 word2vec常规用法:
from gensim.models import word2vecmodel = word2vec.Word2Vec(sentences=text, size=100,min_count=5, workers=8, sg=0, iter=5)
# 训练skip-gram模型;默认window=5
默认参数列表:
| 参数名 | 用法 |
|---|---|
| sentences=None | 训练文本(单位:句) |
| size=100 | 训练时向量的长度(one-hot的长度?) |
| alpha=0.025 | 学习率 lr |
| window=5 | 窗口大小 |
| min_count=5 | 字典截断,词频少于min_count次数的单词会被丢弃掉 |
| max_vocab_size=None | 词向量构建期间的RAM限制。如果所有不重复单词个数超过这个值,则就消除掉其中最不频繁的一个,None表示没有限制 |
| sample=1e-3 | 高频词汇的随机负采样的配置阈值,默认为1e-3,范围是(0,1e-5) |
| seed=1 | 用于随机数发生器。与初始化词向量有关 |
| workers=3 | 设置多线程训练模型,机器的核数越多,训练越快 |
| min_alpha=0.0001 | 字典截断,词出现概率少于min_alpha的单词会被丢弃掉 |
| sg=0 | 训练时用的算法,当为0时采用的是CBOW算法,当为1时会采用skip-gram |
| hs=0 | 若为1则采用hierarchica·softmax策略,若为0(默认值),则负采样策略会被使用 |
| negative=5 | 若大于0,就采用负采样,此时该值的大小就表示有多少个“noise words”被使用,通常设置在(5-20),默认是5,若该值为0,则表示不采用负采样 |
| cbow_mean=1 | 在采用cbow模型时,此值如果是0,就会使用上下文词向量的和,如果是1(默认值),就会采用均值 |
| hashfxn=hash | hash函数来初始化权重。默认使用python的hash函数 |
| iter=5 | 迭代次数 |
| trim_rule=None | 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受(word, count, min_count)并返回utils.RULE_DISCARD,utils.RULE_KEEP或者utils.RULE_DEFAULT,这个设置只会用在构建词典的时候,不会成为模型的一部分 |
| sorted_vocab=1 | 如果为1,则在分配word index 的时候会先对单词基于频率降序排序。 |
| batch_words=MAX_WORDS_IN_BATCH | 每一批传递给每个线程单词的数量,默认为10000,如果超过该值,则会被截断 |
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值
2.2 基于model的一些操作
以达观杯的训练数据为例:
- 获取特定词的词向量
print('word vector of'+text[1][1]+'is :')
print(model[text[1][1]]) #获取指定词的词向量
- 计算两个词之间的相似度
model.similarity(text[1][3], text[3][1])
- 计算某个词的相关词列表
model.most_similar(text[1][2], topn=20) # 20个最相关的
- 寻找离群词
model.doesnt_match("书 书籍 教材 很".split())
- 保存模型
model.save("name.model")
- 对应的加载方式
model = word2vec.Word2Vec.load("name.model")
2.3 竞赛数据分词
# 数据预处理:去除空格,句子转化为list
def sentence2list(sentence):return sentence.strip().split() # 去除空格后拆分# 准备数据
sentence_train = list(df_train['word_seg'].apply(sentence2list)) #数据格式为df,运用apply()对每列数据做处理
sentence_test = list(df_test['word_seg'].apply(sentence2list))
text = sentence_train + sentence_test
print('准备数据完成!')# 训练模型
model = word2vec.Word2Vec(sentences=text, size=100,min_count=5, workers=8, sg=1, iter=5)
# 训练skip-gram模型;默认window=5# 提取词汇表
wv = model.wv # 单词权重
vocab_list = wv.index2word
word_idx_dict = {}
for idx, word in enumerate(vocab_list):word_idx_dict[word] = idxvectors_arr = wv.vectors
vectors_arr = np.concatenate((np.zeros(100)[np.newaxis, :], vectors_arr), axis=0)#第0位置的vector为'unk'的vectorfeature_path = 'D:\\NLP_datasets\\daguan'
f_wordidx = open(feature_path + 'word_seg_word_idx_dict.pkl', 'wb') # 记录词序
f_vectors = open(feature_path + 'word_seg_vectors_arr.pkl', 'wb') # 记录词向量
pickle.dump(word_idx_dict, f_wordidx)
pickle.dump(vectors_arr, f_vectors)
f_wordidx.close()
f_vectors.close()
print("训练结果已保存到该目录下! ")
np.newaxis 在这一位置增加一个一维
x1 = np.array([1, 2, 3, 4, 5]) # shape is (5,)
x1_new = x1[:, np.newaxis] # shape is (1,5),有reshape 的作用
3. 参考资料
word2vec详解:
1)https://blog.csdn.net/u014665013/article/details/79128010
2)https://zhuanlan.zhihu.com/p/56176647
gensim简介:
3)https://www.jianshu.com/p/9ac0075cc4c0
word2vec多种实现方式:
4)https://www.jianshu.com/p/972d0db609f2
5)https://github.com/Heitao5200/DGB/blob/master/feature/feature_code/train_word2vec.py
这篇关于达观杯数据竞赛项目--初识word2vec的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





