达观专题

“达观杯”NLP算法大赛再启航,丰厚奖金、直通Offer等你来拿!
来源:达观数据 本文约1258字,建议阅读3分钟。 “达观杯”是由达观数据主办的全国前沿人工智能和大数据技术竞赛,此届“达观杯”以文本智能处理为主题。 人工智能在2018年继续强势发展,在运算智能和感知智能取得了很大的突破和优于人类的表现。 NLP(自然语言处理)一直是人工智能领域的重要话题,而人类语言的复杂性也给 NLP 留下了重重困难等待解决。长文本的智能解析就是颇具挑战性的任务,
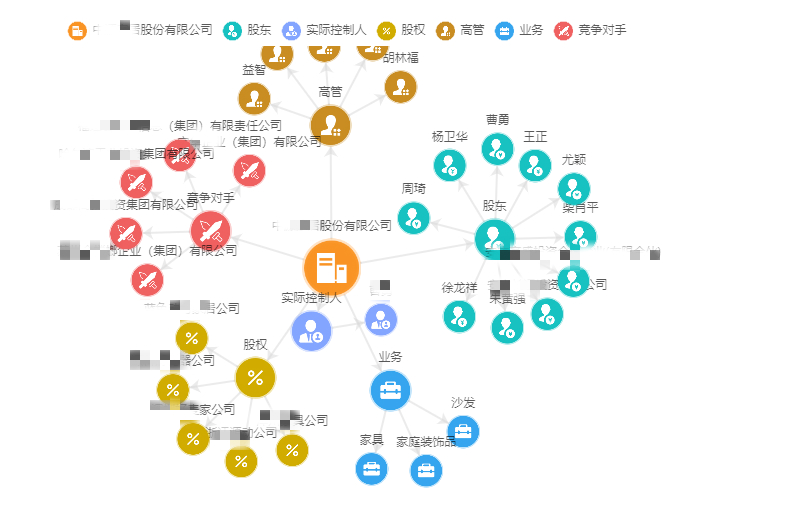
达观知识图谱赋能智能投研,可实现金融数据结构化提取与分析
知识图谱(Knowledge Graph)本质上是一种大型语义网络,旨在迅速表示客观世界中概念实体间的相互关系。随着人工智能的迅猛发展,知识图谱技术已具备落地和商用的能力,越来越多的企业,引入知识图谱技术,解决企业内部数据分析和挖掘问题,并已得到非常可观的成效。 以金融行业为例,企业内部存有很多数据,从技术上可分为结构化数据、非结构化数据、半结构化数据。 目前企业用到最多的是结构化数
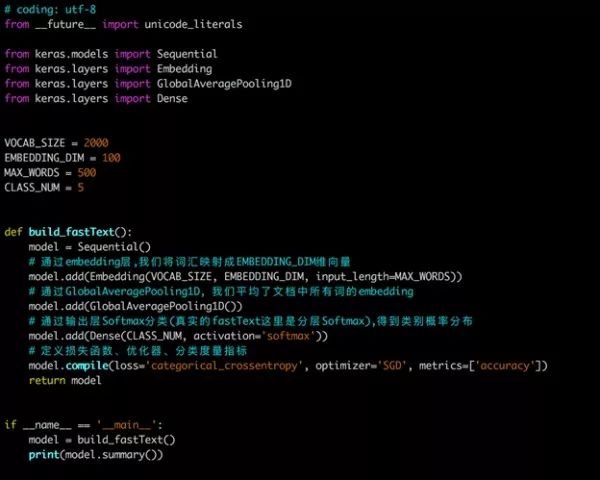
达观数据王江:fastText原理及实践
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。 本文首先会介绍一些

达观数据:用好学习排序 (LTR) ,资讯信息流推荐效果翻倍
序言 达观数据是一家基于文本语义理解为企业提供自动抽取、审核、纠错、推荐、搜索、写作等系统服务的人工智能企业,其中在推荐场景上我们也服务了很多客户企业,客户在要求推荐服务稳定、需求响应及时的基础上,对系统的效果也提出了越来越高的期望,这对算法团队也是一个挑战。本文将从资讯信息流这个场景入手,先简单介绍达观推荐引擎的架构演化,同时尽可能详细的介绍学习排序这个核心技术的实践和落地经验。 达观推荐引

达观数据技术实践:知识图谱和Neo4j浅析
在当前大数据行业中, 随着算法的升级, 特别是机器学习的加入,“找规律”式的算法所带来的“红利”正在逐渐地消失,进而需要一种可以对数据进行更深一层挖掘的方式,这种新的方式就是知识图谱。 下面我们来聊一下知识图谱以及知识图谱在达观数据中的实践。 NO.1 什么是知识图谱 知识图谱(Knowledge Graph)是一种用点来代替实体,用边代替实体之间关系的一种语义网络。通俗来说,知识

达观数据比赛 第三天任务
清明节结束,恢复上班日常啦。 【任务2.2】时长: 2天 学习word2vec词向量原理并实践,用来表示文本。 我们可以把word2vec模型简单化地看成是神经网络。如下图所示, 输入是一个one-hot向量,通过中间层(不含激活函数),输出层和输入层纬度一样 Word2Vec一般分为CBOW(Continuous Bag-of-Words )与Skip-Gram两种模型。

达观数据携手某市审批局打造智能“一业一证”申报信息系统
近日,达观数据携手某市审批局打造智能“一业一证”申报信息系统,在省政务网正式上线运行,实现首批10个行业“一证准营”。标志着在“十四五”有关政府部门数字化转型的核心策略推动下,往国家治理体系化和治理能力现代化迈上了一个新台阶。 达观数据融合自研人工智能OCR技术和RPA流程自动化机器人,为该城区“一业一证”申报信息系统打造坚实的技术支撑。从流程上优化行业准入业务流程,将一个行业准入涉及的多张
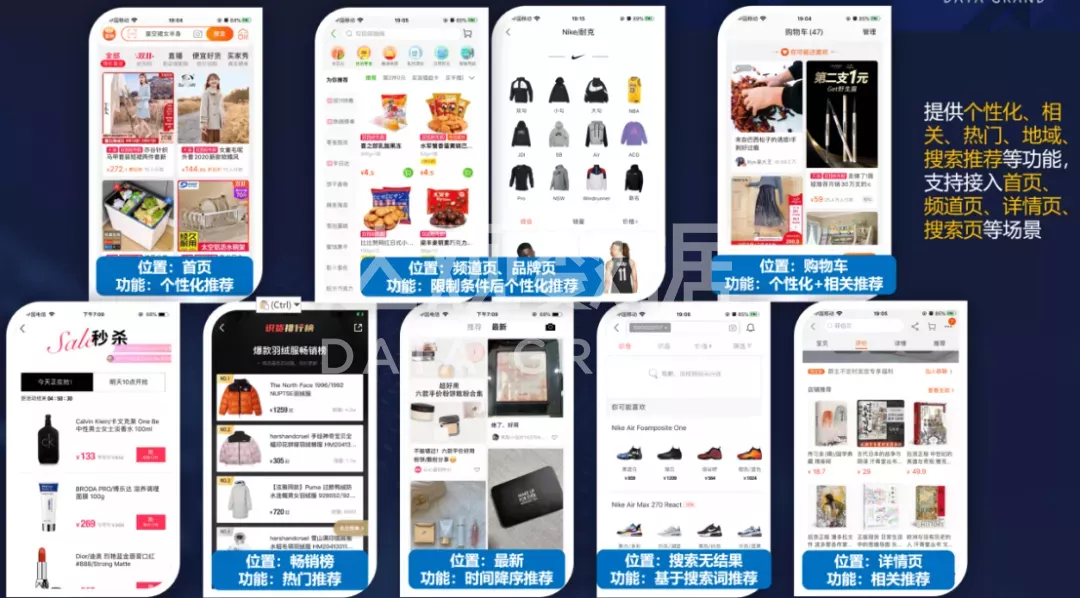
达观推荐系统助力电商行业精细化运营
伴随着实体行业的数字化转型,以及网民数量、物流快递行业的快速增长,电商平台之间的竞争也日趋增大。如今,电商行业已然进入创新发展阶段,如何直面行业痛点,在众平台中“杀出重围”呢? 电商行业痛点 多用户对商品的需求不是单一的,如何面对不同用户多种多样的需求? 快用户购物时一般都带有目的性,如何在短时间内识别用户购物需求从而吸引用户? 准商品琳琅满目,如何做到为用户精准推荐? 达观通过电商

达观杯数据竞赛项目--初识word2vec
文章目录 初识词向量表示:word2vec1. 课程计划1.1 词义(word meaning)构造词汇的相似性关系(distributional learning)1.2 word2vec简介1.2.1 Skip-gram model1.2.2 Skip-gram 框架结构1.2.3 参数矩阵更新的相关推导 1.3 小结 2 gensim实现word2vec2.1 gensim 简介2.2

“达观杯”进行时 | 万字长文详解“智能文本抽取”算法进阶与应用
首先简单地介绍一下我们公司。达观数据是一家专注于做文本智能处理的科技公司,目前完成了B轮,融资超过2亿元,投资机构包括宽带、软银、真格等等。我们主要做的是利用自然语言处理、光学字符识别(OCR)、知识图谱等技术,为大型企业和政府机构提供机器人流程自动化(RPA)、文档智能审阅、垂直搜索、智能推荐、客户意见洞察等智能产品,让计算机代替人工完成业务流程自动化,大幅度提高企业效率。 达观数据 文

2018“达观杯” TF-IDF实践
TF-IDF(term frequency–inverse document frequency) TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随著它在文件中出现的次数成正比增加,但同时会随著它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件

打造中国企业最聪明机器人员工,达观数据发布智能RPA
数据猿官网 | www.datayuan.cn 今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区 2019 年7月 26 日,业界领先的人工智能企业达观数据在北京召开“达道至简”为主题的产品发布会,正式推出国内首款自主研发集OCR(光学字符识别)与 NLP(自然语言处理)于一体的达观智能RPA。 达观数据创始


达观杯--风险事件实验记录
达观杯–风险事件实验记录 官方代码 #!/usr/bin/env python# coding: utf-8import pandas as pdfrom sklearn.model_selection import train_test_splitimport syssys.path.append("./")# ### 加载数据集,并切分train/dev# In[2]:# 加载数据