本文主要是介绍Events-to-Video: Bringing Modern Computer Vision to Event Cameras,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Events-to-Video: Bringing Modern Computer Vision to Event Cameras
摘要
- 事件相机具有诸多优点,但其生成的数据流无法直接应用于传统视觉网络。
- 提出了一种能从事件数据进行视频重建的视觉策略,并应用于后续的视觉任务。
Introduction
- 这里列举了事件相机的优点,后续笔锋一转,就开始讲当前研究的困境。
- 困境是因为事件相机无法直接用传统网络,且之前的一些工作比如事件帧或者时间表面等图像都不是自然图像。这就引出了本文的工作内容:利用事件相机做自然图像重建,进而就能应用于现成的(off-the-shelf)视觉模型。
- 主要贡献:
1)一个基于事件数据的递归神经网络。
2)模拟事件生成并用于网络训练。
3)可用于物体分类和视觉里程计等任务
Realted Work
- 因为本文做的事情是Event-To-Video,所以上来讲讲了一下static scene,抛砖引玉。这部分提到的 Asynchronous, photometric feature tracking using events and frames 比较有开创性,大致想法是用亮度增量图像来做跟踪,假设在很小的事件范围 Δ t \Delta t Δt内,亮度增量是由像素移动引起的,则增量公式和移动公式就能联系起来,frame的光流、梯度和事件积分就能等价了。
- 第二段开始谈时间到视频的建模,这里的topic主要是说做视频的话可以重建任意时刻的灰度帧。这里作者提到了一个事情,就是大多数基于时间的视频重建都是直接由事件积分得来的,这样的做法会不可避免的遭遇边缘模糊和鬼影等类型的噪声,这是事件相机激发阈值设置的问题,也就是说传统做法无法解决。
- 第三段就开始引出深度学习的做法,提到了一个06年的工作,利用字典学习从模拟的事件数据中得到局部的像素梯度,并利用泊松积分来重建强度图像。本文的改进是不再使用局部窗口,而是一次生成整张强度图像。
Video Reconstuction Approach
- 这里介绍了文章的整体思路,下面的流程图展示了模型的机制,这里的 K K K和 e N k e^k_N eNk都是固定值,可以提前设置。为了方便理解,所以设置成了 N = 7 N=7 N=7,实际上 N N N的取值远远要大于7,下文中给出的值是25000。
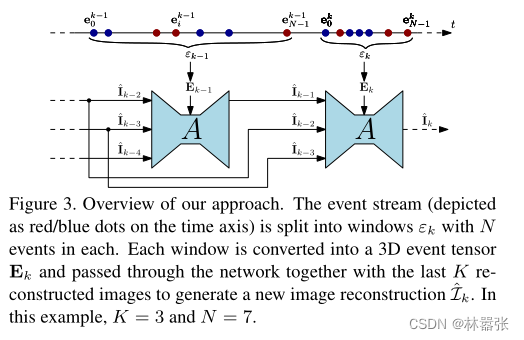
- 训练模型需要大量的事件点和自然图像,但是现有的事件数据集无法提供众多的frame作为groundtruth,这里文章的想法是利用现有的事件生成器ESIM在原有的视觉数据集上进行部署。
- 训练阶段使用UNet架构来进行图像重建,并利用递归网络来重复UNet的训练过程,这里的递归网络应该是LSTM。
这篇关于Events-to-Video: Bringing Modern Computer Vision to Event Cameras的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





