本文主要是介绍跟杂乱无章的数据说再见!全域BI,助力杰士邦决策提效90%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在推出全域数据连接器后,有粉丝后台留言,说要看全域BI模块的功能介绍。小编将全域BI分为市场、运营、服务三篇文章,依次介绍其价值。
商家在制定营销策略、寻找爆款产品、定位产品差异时,经常需要做“市场分析、竞品分析、竞店分析”等,因此需每天关注整体市场变化、对手竞争力情况,以便及时调整营销策略,提升品牌竞争力。
对于全域经营商家来说,往往会有专门的数字化团队,负责内部数据分析和展示,但通过人工采集各平台、店铺数据,汇总为表格进行分析,存在数据结果不直观(数据需要转换)、数据分析不准确(人工难免出错)、数据采集不及时(店铺多耗时长)等问题,很难支撑起整个企业的数据应用需求。
基于此,实在智能以实在RPA·数字员工为技术底座,推出「全域BI-市场」解决方案,可自动完成多店铺、多商品、多维度、多渠道的数据采集到结果呈现全过程,不仅帮助商家快速洞察市场行情、定位产品差异、打造店铺爆款,而且有效减轻数字化团队数据处理压力,极大降低决策成本。
全域BI市场版块:洞察全域增长先机,全方位赶超竞店竞品
如今的电商行业流量红利消退激化竞争、新一代消费者入局改变消费链路和逻辑,内卷压力下,电商竞争核心回归零售本质。在保证产品质量和定价的前提下,市场营销精准触达、产品设计差异定位等成为品牌获取市场的主要竞争手段。
「全域BI-市场」可将天猫、京东、抖音、拼多多等销售渠道数据打通,自动汇总、分析并统一展示为真实交易数据。与以往人工汇总分析相比,管理层不需要再等上半天或一天时间,才能看到全域市场分析报表,「全域BI-市场」只需几分钟,便可以自动完成,且所有数据准确率达100%,避免人工出错问题。
整合好的数据,可被应用到多个部门。在运营部,通过对竞店、竞品的流量来源结构分析,可以针对性优化推广渠道,调整营销策略,快速提升产品销量;在产品部,通过对不同类目的趋势和流行产品分析,可以掌握市场动态,及时调整选品策略,确保产品始终迎合消费潮流。
同时,在「全域BI-市场」页面,商家还可按照细分类目、店铺ID、商品ID、品牌、日期等维度筛选数据,分析经营销售对比、流量构成对比、大盘销售趋势、品牌市场占比等。
有了准确、及时的市场数据,商家通过「全域BI-市场」,可以更好地洞察市场趋势,指导运营决策,降低试错成本,全方位赶超竞店竞品。
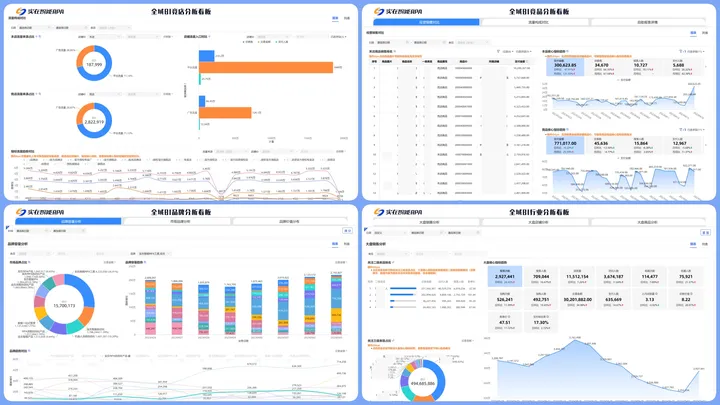
杰士邦:无人值守采集全域市场数据,决策效率提升90%
通过「全域BI-市场」进行市场分析,杰士邦、努比亚、馨生活、美岸、方卓、美裳电商等知名企业早已在业内做出成功典范。
他们通过私有化部署「全域BI-市场」,大量释放员工重复性、规律性劳动,精准获取市场大盘数据,为企业营销决策提供高效准确的数据支撑。
杰士邦项目介绍
项目背景
杰士邦在制定销售计划、店铺规划时需关注行业细分赛道规模变化,因此需每天关注整体市场变化和竞对情况。在部署「全域BI-市场」前,都是通过表格形式来查看赛道数据,不直观、不及时且人工采集易出错。
解决方案
根据杰士邦需求,实在RPA·数字员工每天定时采集所有渠道核心数据,并自动录入企业数据库中进行清洗、加工、关联等规范化处理,最后通过「全域BI-市场」可视化进行业务场景图表展示,方便业务人员按需使用数据。
项目价值
效率提升:全域BI自动完成数据获取至展示的全流程,可以节省约90%的人工处理数据时间
准确率提升:实在RPA·数字员工是机器人,不受外界环境干扰,采集的数据准确率可达100%
员工价值提升:释放数据分析团队人力,去做决策优化等更具价值的工作,产生经济价值超百万
这篇关于跟杂乱无章的数据说再见!全域BI,助力杰士邦决策提效90%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






