本文主要是介绍轻松来自实力,亚马逊云科技助力边界智能应对业务高峰值数据考验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
边界智能(Bianjie.AI)是2016年创立于上海的国家高新技术企业和专精特新企业,同时也是以香港为全球总部、服务全球的区块链技术创新团队。公司专注于区块链技术支持的下一代互联网应用服务,自主研发了跨多条联盟链的分布式应用服务平台AVATA、开发许可联盟链文昌链、企业级基础联盟链IRITA等核心产品。
面对边界智能AVATA平台及文昌链开发遇到的技术难点及业务交易数据高峰值考验等痛点,亚马逊云科技为边界智能提供了Amazon Aurora、Amazon EKS、Amazon EC2、Amazon VPC、Amazon Security Hub等产品来优化其区块链业务系统,帮助客户实现了系统的高可用性和可扩展性,并节省了50%的成本。
机会:跨多条联盟链的分布式应用服务平台AVATA遭遇业务技术双重挑战
边界智能面对的是下一代互联网的应用需求,由于业务的特殊性,对性能的并发、安全、用户体验都有着极高的要求。不仅如此,边界智能还需要提供安全合规且能有序发展的应用。面对复杂的商业逻辑,以及繁重的链上链下的互操作,边界智能的客户大多是传统的企业级应用开发者,边界智能不仅需要为这些开发者提供低成本安全的下一代互联网开发分布式应用,还需要提供给他们所熟悉的基于传统API开发形态一样的服务。
在技术层面上,边界智能于2022年3月推出了跨多条联盟链的分布式应用服务平台AVATA,也面临着诸多挑战:
● 现有服务器容量扩展难,不能及时解决业务增长带来的高峰期流量压力;
● IT基础设施维护成本高,可用性、灵活性和安全性急需提升;
● 搭建开发环境和测试环境耗时耗力;
● 缺乏弹性的计算能力来运行大规模数据分析任务。
为了解决这些难题,边界智能技术合伙人张业龙表示:“我们需要一个与我们项目架构基础需求高度匹配的云服务商来改善我们平台的性能,亚马逊云科技具备足够可靠的基础设施,其在全球范围内部署了大量数据中心和服务节点,高可用性和灾备能力的解决方案,可以确保我们的业务不会受到中断或丢失数据。”
解决方案:亚马逊云科技助力边界智能多种业务,轻松应对高峰值数据考验
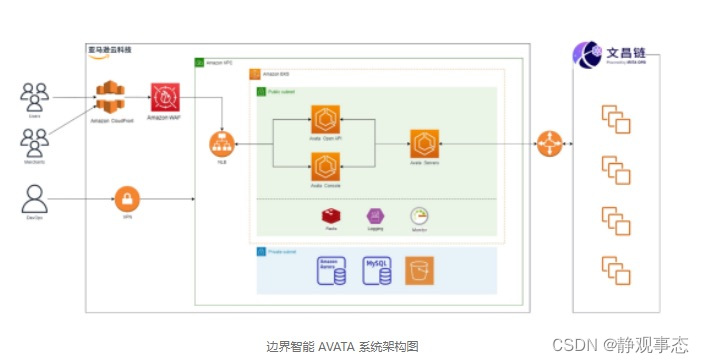
Amazon Aurora助力客户突破数据库性能瓶颈,实现云服务“零运维”
“在开发AVATA平台的过程中,主要面临的问题是数据库性能的瓶颈。”边界智能技术合伙人张业龙说。经过多种解决方案选型之后,边界智能最终选择了Amazon Aurora,它几乎可以提供非常完善的“零运维”的云服务。在数据量达到瓶颈之前,技术人员可将数据顺利平滑地向Amazon Aurora迁移。出乎意料的是,迁移完成之后的数据库吞吐性能明显较之前提升了3-5倍。Amazon Aurora极致的弹性和扩展能力,帮助边界智能不需要在开发上做很大改造的同时,也节省了成本。
Amazon EKS低成本实现业务流量及负载的弹性架构,让边界智能省心省力
边界智能技术合伙人张业龙还提到,边界智能使用过且目前还在使用中的包括自建服务器、IDC托管、和亚马逊云科技服务。但IDC需要自采购服务器资源,如果有流量拓宽的需求,硬件资源无法很快地进行弹性扩容,除非提前采购冗余的资源,但会导致成本非常高。Amazon EKS的服务集成了Kubernetes所有的优点,边界智能通过持续运营的方式,实现了便捷部署。到目前为止,系统还没发生过容灾处理,即使遇到个别工作节点出现问题,Amazon EKS也会自动进行容器服务迁移,来保证边界智能服务的可靠性和安全性。
得益于Amazon EKS双重弹性扩容的特性,边界智能在配置容器副本的时候,可自定义弹性范围。随着负载的变化,Amazon EKS会自动扩缩容器副本的数量。其次,客户还制定了工作节点的弹性,随着容器数量和工作节点负载的变化,Amazon EKS会自动弹性扩缩工作节点的数量,给固定需要使用的节点采购预留资源。在面临业务高峰和突发请求的时候,Amazon EKS可以快速自动增加弹性资源,让边界智能无惧流量的压力。其按量付费的模式,也有效降低了边界智能的采购成本。
利用Amazon EC2安全灵活的调整云资源配置,助力客户降本增效
启动新的联盟链节点并同步链上的数据,其耗时可能是小时级别甚至几天才能同步完所有的数据。如果遇到突发的流量进来,对整个运营状态要求是非常高的,还要考虑安全备份的工作。
边界智能通过Amazon EC2部署了区块链节点并根据负载情况动态调整资源配置,如CPU、内存、磁盘IO等,降低了企业的运营成本。同时,借助Amazon EC2数据生命周期管理器制定的节点数据盘快照策略,恢复磁盘的过程更是秒级完成,大幅提升了边界智能系统故障恢复以及新节点启动的效率。
亚马逊云科技初创团队的陪伴是对客户的深情告白
从AVATA平台开发伊始,亚马逊云科技云创计划就为边界智能提供了一系列免费的云计算服务资源/技术选型建议及专家培训指导。包括免费测试额度体验Amazon Aurora、通过Amazon VPC进行文昌链网络链接、基于Amazon EKS托管服务搭建运营环境等。经过与亚马逊云科技初创团队深入的交流与合作,边界智能不但降低了开发成本,还加速了业务的创新和发展。
业务成果:企业总体成本降低50%,业务效率提升80%
边界智能技术合伙人张业龙谈到AVATA平台的出色表现时说:“AVATA自去年3月上线,发展非常快速。经过一年多的使用,亚马逊云科技的服务给我印象最深的就是它的可靠性,在数据增长的过程中,我们没有感受到任何压力,系统性能也没受到任何的影响。”
系统可扩展性和稳定性改善显著,业务效率提升80%
基于Amazon Aurora自动化管理、扩展性和弹性计费的模式,边界智能处理业务响应的时间也比Amazon RDS数据库快了近3倍且没有发生过任何故障。企业无需再为备份、故障转移、缩放这些业务花费额外的成本或者人力资源,员工可以更聚焦于核心业务并投入更多精力来创新,业务效率提升了80%。
企业总体成本降低50%
利用亚马逊云科技丰富的产品服务和工具,边界智能的产品从开发到面世的周期缩短了30%。企业总体成本降低了50%,其中系统运维成本、人工成本和IT资源成本都分别降低了40%。尤其在使用了Amazon Aurora后,成本降低了60%,这也得益于该产品的自动化管理、可扩展性和弹性计费模式。
Amazon Security Hub为企业数据资产保驾护航
边界智能还启用了Amazon Security Hub这款产品,利用其自动化安全检查机制,快速识别安全隐患并解决了任何潜在的风险问题,企业数据安全性提升了50%。边界智能创始人兼CEO曹恒表示,“亚马逊云科技为边界智能提供了非常专业且有创新导向的合作。在推进互联网产品技术向前高速发展的进程中,云服务商的重要支撑作用是不可或缺的。”作为亚马逊云科技合作伙伴网络(APN)的一员,边界智能对下一代互联网的区块链技术怀有美好的期待。未来,在全球的数字银行、全球的可信计算环境、跨境贸易等一些新的应用领域,边界智能也非常希望和亚马逊云科技有更多合作,一同帮助技术开发者社区,共建行业影响力。
这篇关于轻松来自实力,亚马逊云科技助力边界智能应对业务高峰值数据考验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







