本文主要是介绍大模型LLMs 部分常见面试题答案-基础面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题库来源:GitHub - km1994/LLMs_interview_notes: 该仓库主要记录 大模型(LLMs) 算法工程师相关的面试题
目录
1. Prefix Decoder、Causal Decoder和Encoder-Decoder的区别
1.1 Prefix Decoder
1.2 Causal Decoder
1.3 Encoder-Decoder
2. 大模型LLM的训练目标
3. 涌现能力的原因
4. 为何现在的大模型大部分是Decoder only结构
4.1 计算效率
4.2 训练效果
4.3 数据利用
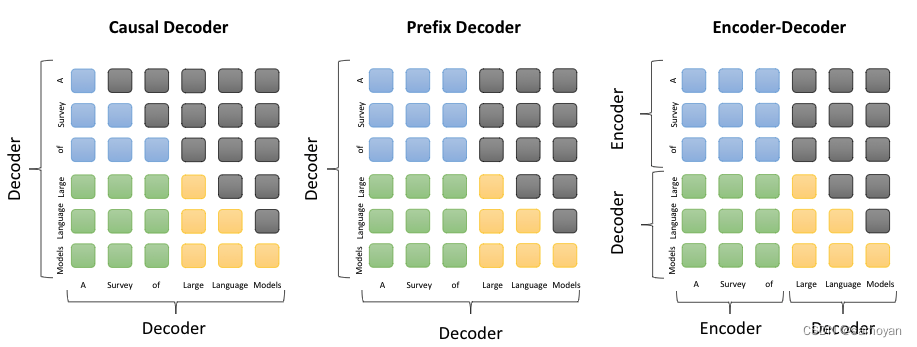
1. Prefix Decoder、Causal Decoder和Encoder-Decoder的区别
1.1 Prefix Decoder
Prefix Decoder是一种解码器结构,它在生成新的输出时,会考虑到所有之前生成的输出。这种结构在自然语言处理任务中常见,例如机器翻译、文本生成等。
1.2 Causal Decoder
Causal Decoder也是一种解码器结构,它在生成新的输出时,只会考虑到之前的输出,而不会考虑到未来的输出。这种结构在处理时间序列数据或者语音信号等任务中常见。
1.3 Encoder-Decoder
Encoder-Decoder是一种常见的神经网络结构,它包括一个编码器(Encoder)和一个解码器(Decoder)。编码器负责将输入数据转化为一个连续的向量,解码器则负责将这个向量转化为最终的输出。这种结构在许多任务中都有应用,例如机器翻译、语音识别等。
2. 大模型LLM的训练目标
大模型LLM(Language Model)的训练目标是学习语言的统计规律,以便能够生成或者理解人类语言。具体来说,LLM通常通过最大化训练数据的似然性来进行训练,也就是尽可能地让模型生成的语言与人类语言相似。
3. 涌现能力的原因
涌现能力是指模型在训练过程中自然产生的能力,例如理解语法、词义等。这主要是因为模型在训练过程中,通过大量的数据学习到了语言的统计规律,从而能够理解和生成符合这些规律的语言。
4. 为何现在的大模型大部分是Decoder only结构
现在的大模型大部分是Decoder only结构,主要有以下几个原因:
4.1 计算效率
Decoder only结构比Encoder-Decoder结构更加简单,计算效率更高。因为Decoder only结构只需要一次前向传播,而Encoder-Decoder结构则需要两次前向传播。
4.2 训练效果
Decoder only结构在许多任务上的表现与Encoder-Decoder结构相当,甚至更好。例如在语言模型任务上,Decoder only结构通常能够达到更好的效果。
4.3 数据利用
Decoder only结构可以更好地利用无标签数据进行训练。因为它可以直接使用大量的文本数据进行无监督学习,而不需要标签数据。
以上内容主要基于对神经网络结构和大模型的理解,具体的实现可能会因模型和任务的不同而有所不同。
这篇关于大模型LLMs 部分常见面试题答案-基础面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






