本文主要是介绍Kubernetes深度剖析,从基础到高级,带你领略K8s的魅力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心。
建于 Docker 之上的 Kubernetes 可以构建一个容器的调度服务,其目的是让用户透过 Kubernetes 集群来进行云端容器集群的管理,而无需用户进行复杂的设置工作。系统会自动选取合适的工作节点来执行具体的容器集群调度处理工作。其核心概念是 Container Pod。一个 Pod 由一组工作于同一物理工作节点的容器构成。这些组容器拥有相同的网络命名空间、IP以及存储配额,也可以根据实际情况对每一个 Pod 进行端口映射。此外,Kubernetes 工作节点会由主系统进行管理,节点包含了能够运行 Docker 容器所用到的服务。
二、架构模型为master/nodes(work)
可以理解master为蜂后,nodes为工蜂(干活的)
1. master为集群唯一入口,需要做高可用。
2. 每一个node节点都提供一部分计算能力和存储能力。(运行容器的节点)
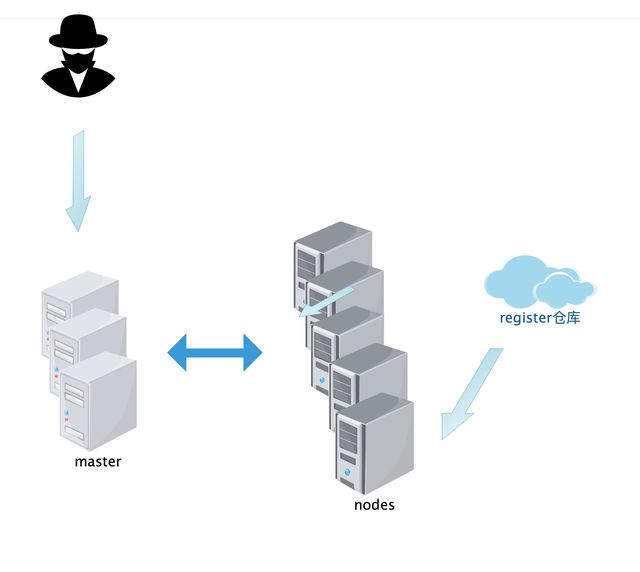
请求过程:
1 客户端请求(创建启动容器)首先发往master,master当中有一个调度器,会去分析各node节点的资源状态.
2 找一个最佳适配运行用户所请求的容器的节点,并把它调度上去,由这个node的docker或是其他容器引擎来负责把这个容器启动起来。
3 启动容器时检查本地是否有镜像,如果没有需要从镜像仓库中pull来启动(镜像仓库可以是云上的,也可以是自检的私有仓库,也可以以容器运行在node节点上)。
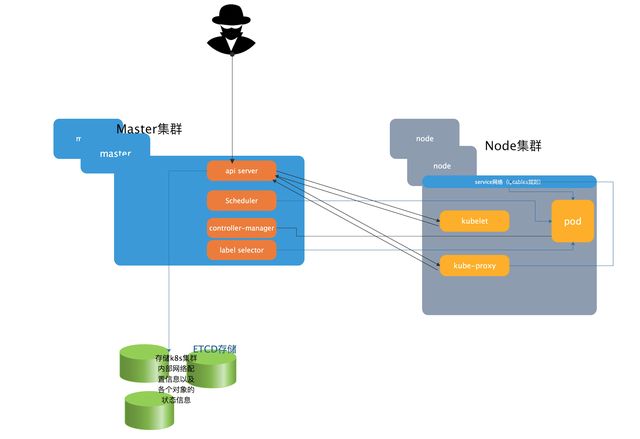
三、Master集群组件
- API Server 接收并处理用户请求
- Scheduler 调度容器创建的请求
- controller-manager 确保已创建的容器处于健康状态
控制器管理器是确保控制器健康的,控制器是用来确保容器健康的。
- label selector 可以通过控制器给pod打标签,之后控制器可以根据tag来识别出pod
创建pod时可以给pod直接打上一个标签,然后让控制器通过标签的值来识别出pod来
四、Node集群组件
- kubelet 与apiserver交互运行的,接收并处理master调度过来的各种任务。
- docker 运行pod中的容器
1. 在K8s上运行的最小单元不是容器,而是pod
2. kubernets并不直接调度容器,而是调度pod,pod是对容器的一层封装。
3. pod里可以有多个容器,他们共享同一网络协议栈,存储卷
4. 一般一个pod只有一个容器
- kube-proxy 与apiserver进行通信,每一个pod发生变化,结果是需要保存到apiserver中,apiserver会生成一个通知事件,该事件可以被任何关联的组建所接收到, 管理service,service的创建及变动是依靠kube-proxy在iptables上创建出规则
Pod简介
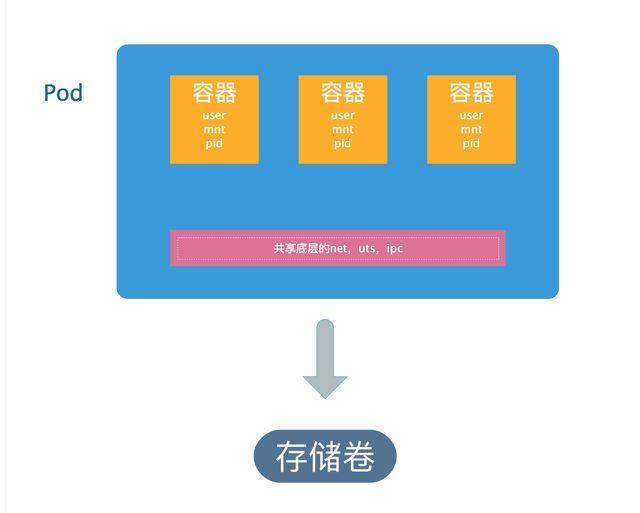
- pod中的每一个容器有自己的user,mnt,pid的名称空间,然后他们共享pod的net,uts,ipc的名称空间。
- 一般一个pod中只有一个容器,除非容器之间有特别特别紧密的关系需要放在同一pod中,如果一个pod放置了多个容器,通常有一个为主容器,其他容器来辅助主容器上的应用程序完成更多功能来实现。
- 创建pod时可以给pod直接打上一个标签,然后让控制器通过标签的值来识别出pod来
由于pod为kubernet集群中的原子单元,是不可再分割的,一个pod中无论是一个容器还是多个容器,当pod被master调度至某一node上时,这个pod中的所有容器都被调度到了一台node上
1. 自主式Pod
自我管理,创建后仍然要提交给apiserver,由apiserver将其调度至指定的node的节点,由node启动此pod,如果一个pod中的容器出现故障,需要重启容器,需要又kubelet来完成。但是,如果节点故障了,该容器就消失了。无法实现全局进行调度。
2. 控制管理的Pod
- 正是有控制器机制的引入使得pod成为有生命周期的对象,而后由调度器将其调度至集群中的某节点运行以后,有一些任务作为守护进程运行为pod或容器,要确保它们随时处于运行状态,一旦发生故障,要随时重启它或者替代它。
pod控制器种类
1. Replication Controller
- 多退少补,必须精确符合人定义的期望- 滚动更新(类似用户无感知发布)- 回滚
2. ReplicaSet
3. Deployment 只能管理无状态应用
4. StatefulSet 管理有状态的应用
5. DaemonSet 每个node上运行一个副本,而不是随意运行
6. Job,Cronjob 运行作业或者周期性作业
- 有些任务是临时需要而运行,运行完以后结束,这种不需要一直处于运行状态,可以运行为一个job
7 . HPA(HorizontalPodAutoscaler) 自动监控并系统负载分析添加或减少pod
服务发现功能
- 每重新生成一个pod都是一个全新的pod,比如ip地址和主机名之前的是不一样的。
- kubernets为每一组提供同类服务的pod和它的客户端之间添加了一个中间层,这个中间层(service)是固定的,service再将客户端请求端口代理至后端pod上(通过dnat规则 ),一旦其中一个pod宕机了,一个新的pod会立即被关联上来(通过标签选择器,具有相同标签的来关联起来),然后在动态探测新关联的pod的ip地址和主机名,
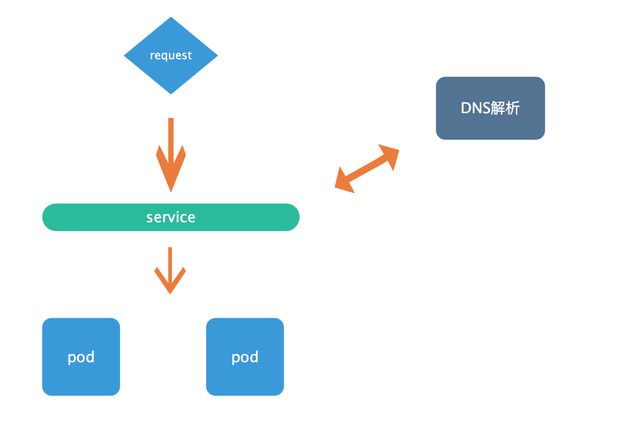
五、k8s网络模型
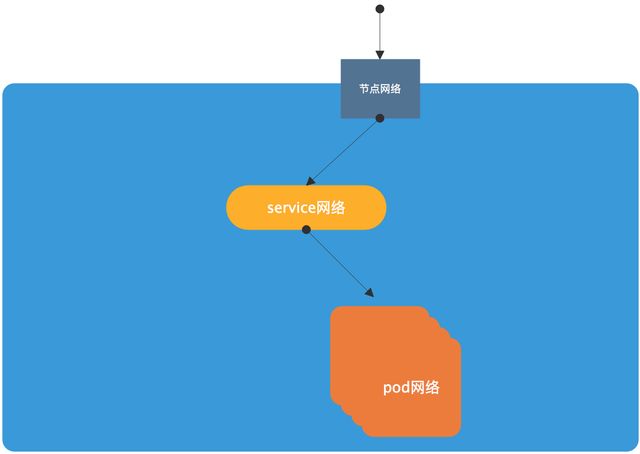
1. pod网络。各pod运行在同一个网络,pod的网络地址是真实的地址,存在于它的网络名称空间当中。
2. service网络(集群网络)。service地址不是真的地址,存在于iptables中或者ipvs规则中。
3. 节点网络 。
六、k8s通信分类
1. 同一pod内的多个容器间:lo网络
2. 各pod之间通信。(overlay network,叠加网络)
各pod之间直接通信,无论pod运行在哪个节点之上,各pod的地址是不应该也绝对不可以相同。
3. pod与servic之间通信
service地址只不过是主机上的一条iptables规则中的地址,所以需要配置一下目标地址不是自己的指向网关。每个主机上都应该有所有的service的地址规则。当pod试图访问service的地址时,首先将请求送给网关(一般为docker0桥),然后docker0桥通过内核发现当前访问的地址为一条iptables或ipvs规则,然后将请求送达。
之前说过,当service后端的node节点宕机,pod的控制器通过标签选择器会自动创建一个新的pod并加入至该服务中,而node中的另一个组件,kube-proxy 在此时会将service的变动存储在master上的api server中,然后api server生成通知事件,又kube-porxy将iptables规则的变化反映至每一个节点的iptables规则上。
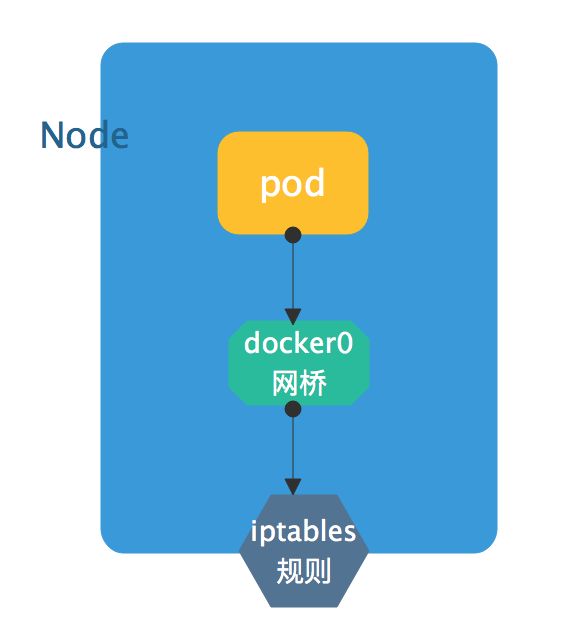
七、etcd k8s的存储
Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息。
存储集群的所有变化信息以及网络配置,非常重要,所以需要做高可用。
八、k8s集群组成要件
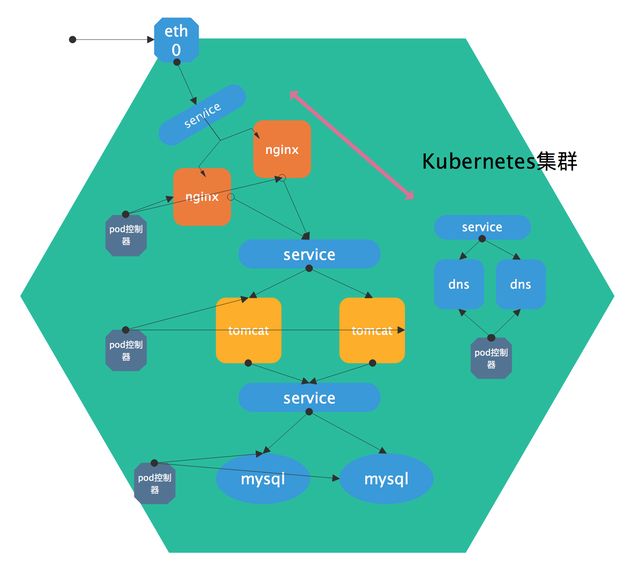
如图所示,每一个服务都有一个service,用来调度请求流量。
如果其中的某个服务中的pod宕机了,pod控制器会自动创建一个新的pod并加入到该服务中。不同的pod的控制器通过pod标签来管理其所属的pod。
当然k8s集群内部也是需要主机名来表示不同的主机的,提供dns服务的也是通过pod,同样的它也有一个service,也有一个pod控制器来管着的dns的pod。
总结。
画了个图总结一下整个的k8s集群,如下。
这篇关于Kubernetes深度剖析,从基础到高级,带你领略K8s的魅力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





