本文主要是介绍《TEA-PSE: TENCENT-ETHEREAL-AUDIO-LAB PERSONALIZED SPEECH ENHANCEMENTSYSTEM FOR ICASSP 2022 DNS CHA》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ABSTRACT
这篇论文提出了两阶段的网络,用ECAPA-TDNN作为获取说话人向量的网络,实现了很好的性能。第一个阶段的网络只是单单的估计幅度谱,和带噪的相位结合起来得到粗糙的复数谱,第二阶段,一个附属的网络作为一个后处理模块,进一步去除掉残余的噪声和人为干扰的声音。同时,相位信息也被跟着改变了。整个大网络用了四个损失组合成最终的损失。
INTRODUCTION
Personalized speech enhancement (PSE),也叫做说话人提取,目标是从一个复杂的多个说话人和混响的环境中提取出想要的那个说话人。多用于实时的环境中。这个比赛有两个通道,一个是没有目标说话人作为先验知识的,另一个是作为有目标说话人作为先验知识的。本文选择了通道2,有目标说话人作为先验知识的。选择做实时的语音,就需要考虑到模型的大小,验证的时间,并且不能用到未来的东西。本文提到的算法不仅仅是用来去噪去混响的,还需要考虑到有干扰的说话人。所以考虑到多阶段的优势,本文也采用多阶段的方法实现目标。
本文提到的网络叫做TES-PSE,主要是由两个模块组成,一个是说话人的编码器,提取说话人的特征,另一个是增强的网络。采用了ECAPA-TDNN作为提取说话人特征的网络。先训练出来这个网络,之后再把这个网络的参数冻结,训练第二个增强的网络。使用第一个说话人提取网络,最终会提取到256维度的特征。
增强的网络:第一阶段,只估计幅度谱,最后将估计到的幅度谱和带噪相位结合得到粗粒度的复数谱,复数谱进入到第二个阶段,进一步估计实部和虚部。其中,幅度谱采用了功率谱压缩。因为有混响,有混响存在的情况下,功率谱压缩是比较有用的一种方法。

第一阶段和第二阶段的网络和下图类似:

ECAPA-TDNN:

res2block:

损失函数采用了三种:SISDR,一个对称的函数,一个幅度谱的函数。还有一个实虚部的函数。
实验数据用的格式DNS挑战赛的数据集。训练的数据,在提取说话人那个网络里面,用到的数据是VoxCelsb2语料库,在增强的网络里面,用到的数据集是DNS数据集。测试集用到三种,第一种是模拟的数据集,用到的是KING-ASR-215。第二种是官方给到的开发集。第三种是官方给到的黑盒测试集。
用到了一些数据增强:
把原始语音随机选取一部分填充为0;
用时频域的掩码应用到输入的频谱上;
增强一种额外的噪声;
增强一种额外的混响;
速度扰动,范围在(0.9,1.1);
同时增强噪声和混响;
实验的结果:


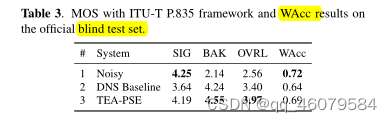
这篇关于《TEA-PSE: TENCENT-ETHEREAL-AUDIO-LAB PERSONALIZED SPEECH ENHANCEMENTSYSTEM FOR ICASSP 2022 DNS CHA》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







