本文主要是介绍171205 逆向-JarvisOJ(文件数据修复),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1625-5 王子昂 总结《2017年12月5日》 【连续第431天总结】
A. JarvisOJ-Re-文件数据修复
B.
有个文件加密工具,能将一个文件加密到一个.ctf文件中去。
有一个犯罪分子将存有犯罪记录的一个名为“CTFtest.ctf”的加密文件被删除了。
现经过数据恢复,我们已经恢复了该文件。但是很不幸,该文件头部的部分数据已经被覆盖掉了。这个.ctf文件已经不能正常打开了。
而且加密该文件的口令,犯罪分子也不愿意交代,我们只知道他惯用的口令是一个8位纯数字口令。
请分析压缩包里的.ctf文件以及解密程序最大限度地恢复出文件中的内容,flag就在里面。Flag形式为大写32位md5。
这个题目好有感觉~
但是也好复杂OTZ有点怂
首先初步分析,无壳,MFC程序

通过xspy找到3个按钮的对应点击函数,分别查看
发现sub_402570对应“解密”按钮

往下阅读流程,发现它依次读取了4字节、4字节、X字节、16字节、4字节、Y字节
第一个4字节是验证格式,为固定内容
第二个4字节标识X的长度
第三个X字节存下来留用(后发现是用来表示原文件的文件名)
第四个16字节与KEY校验
第五个4字节标识Y的长度
第六个Y字节就是真正的数据

分析头部缺失的文件,发现这里很可疑
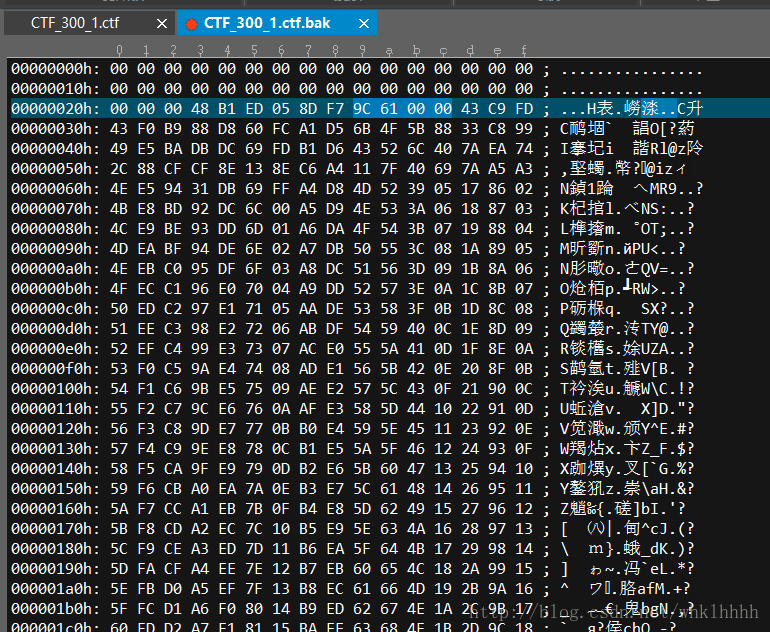
观察总文件长度为0x61c8,刨掉头部0x2c正好就是0x619c
那么这里的4字节就是数据长度了
于是只要依据之前的6个字节,反推出key即可
首先逆向key计算流程,发现就是两次md5,再根据提示8位纯数字进行爆破即可得到密钥20160610
然后补全文件头,通过程序进行解密
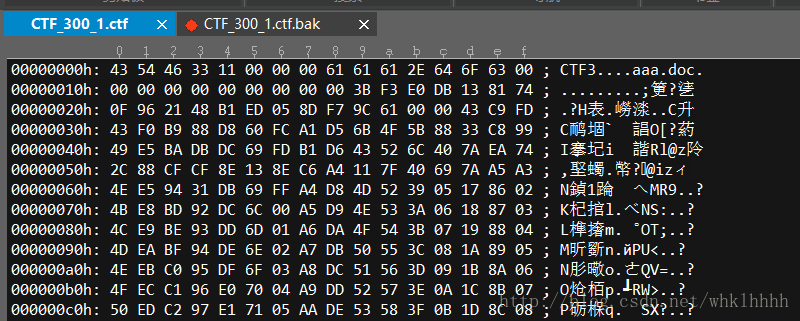
解密出的文件头是PK,zip打开后发现类似doc
于是再将后缀改为doc用word打开,终于得到flag
难度不算太大,但是很有意思~
C. 明日计划
JarvisOJ
这篇关于171205 逆向-JarvisOJ(文件数据修复)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








