一、实验对象
实验对象为星巴克在全球的门店数据,我们可以使用pandas对其进行简单的分析,如分析每个国家星巴克的数量,根据门店数量对国家进行排序等。
二、数据分析
1、读取数据并获取数据行列数
首先读取数据:
import numpy as np
import pandas as pdstarbucks = pd.read_csv("D:\\directory.csv")
print "数据的列标签如下:"
print starbucks.columns
print "每列的数据类型:"
print starbucks.dtypes
print "文件行数:"
print len(starbucks.index)
print "文件列数:"
print starbucks.columns.size输出:
数据的列标签如下:
Index([u'Brand', u'Store Number', u'Store Name', u'Ownership Type',u'Street Address', u'City', u'State/Province', u'Country', u'Postcode',u'Phone Number', u'Timezone', u'Longitude', u'Latitude'],dtype='object')
每列的数据类型:
Brand object
Store Number object
Store Name object
Ownership Type object
Street Address object
City object
State/Province object
Country object
Postcode object
Phone Number object
Timezone object
Longitude float64
Latitude float64
dtype: object
文件行数:
25600
文件列数:
13可以看到文件共有25600条数据,每条数据有13列。
2、查看数据
#查看文件的前五行数据
print starbucks.head()输出: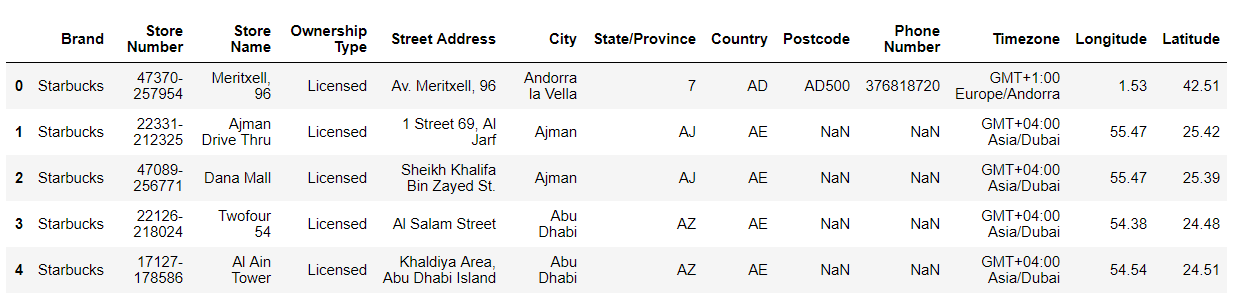
可以通过DataFrame.head(n)来获取数据帧的前n行数据,未指定n则返回前5行,同样的函数还有DataFrame.tail(n)。上图中有些数据为NaN,如果NaN对数据处理有影响的话可以使用DataFrame.fillna(value)将NaN替换成value



