本文主要是介绍一体化模型图像去雨+图像去噪+图像去模糊(图像处理-图像复原-代码+部署运行教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要讲述了一体化模型进行去噪、去雨、去模糊,也就是说,一个模型就可以完成上述三个任务。实现了良好的图像复原功能!
先来看一下美女复原.jpg


具体的:
- 在图像恢复任务中,需要在恢复图像的过程中保持空间细节和高级上下文信息之间的复杂平衡。
- 在这篇论文中,我们提出了一种新颖的协同设计,可以在这些竞争目标之间实现最佳平衡。我们的主要提议是一个多阶段架构,逐步学习对退化输入进行恢复的函数,从而将整个恢复过程分解为更可管理的步骤。
- 具体而言,我们的模型首先使用编码器-解码器架构学习上下文特征,然后与保留局部信息的高分辨率分支相结合。
- 在每个阶段,我们引入一种新颖的逐像素自适应设计,利用原位监督注意力来重新加权局部特征。这种多阶段架构的一个关键组成部分是不同阶段之间的信息交流。
- 为此,我们提出了一种双重方法,在信息不仅从早期到晚期阶段顺序交换的同时,还存在特征处理块之间的侧向连接,以避免任何信息损失。
- 结果紧密关联的多阶段架构,在包括图像去雨、去模糊和去噪等多个任务的十个数据集上实现了强大的性能提升。
去噪结果
该论文提出的方法在图像恢复任务中引入了一个多阶段架构,可以有效平衡空间细节和上下文信息。其核心思想是逐步学习破损输入的恢复函数,并通过多个阶段的信息交流来实现更好的恢复效果。

去模糊结果
具体而言,该方法使用编码器-解码器架构学习上下文特征,并将其与保留局部信息的高分辨率分支相结合。

去雨对比结果
在每个阶段,它还引入了一种新颖的自适应设计,通过利用原位监督注意力对局部特征进行重新加权。此外,该方法还使用了早期到晚期阶段的顺序信息交流和侧向连接来避免信息损失。

代码部署

要部署和运行该论文的代码,您可以按照以下步骤进行:
-
获取代码:首先,您需要从论文作者的代码存储库或其他公开来源获取代码。
git clone my_code 联系我----->qq1309399183 -
环境设置:确保您的计算机上已安装所需的软件和库。根据代码要求,您可能需要安装Python、PyTorch、NumPy等。
conda create -n pytorch1 python=3.7 conda activate pytorch1 conda install pytorch=1.1 torchvision=0.3 cudatoolkit=9.0 -c pytorch pip install matplotlib scikit-image opencv-python yacs joblib natsort h5py tqdmcd pytorch-gradual-warmup-lr; python setup.py install; cd .. -
数据准备:准备用于图像恢复任务的数据集。根据您的需求,您可以选择合适的数据集,并确保按照代码的要求组织数据。
点击代码中的链接获取!
-
模型训练:使用提供的代码,您可以使用准备好的数据集对模型进行训练。根据代码的具体实现,您可能需要指定模型架构、训练参数和优化器等。
python train.py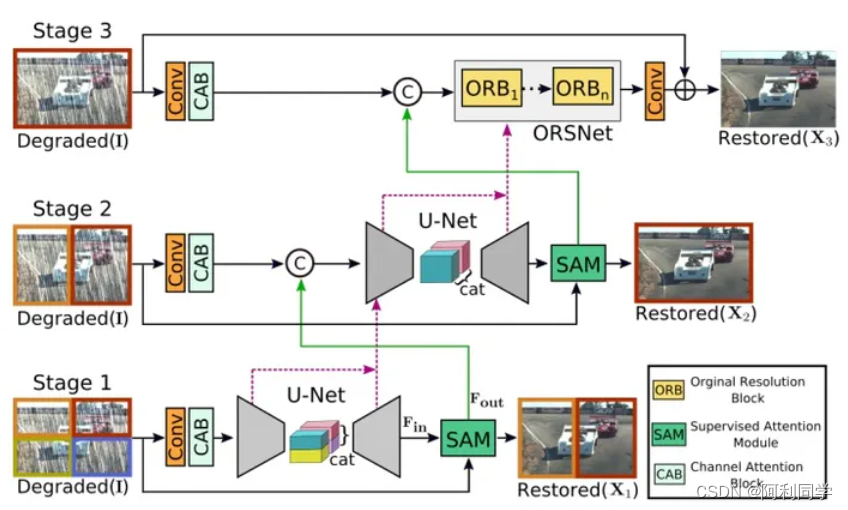
-
模型测试:在训练完成后,您可以使用训练得到的模型对新的图像进行恢复。根据代码的实现,您可能需要提供待恢复图像的路径或其他必要的输入
python demo.py --task Task_Name --input_dir path_to_images --result_dir save_images_here touch me:qq---->130933183
这篇关于一体化模型图像去雨+图像去噪+图像去模糊(图像处理-图像复原-代码+部署运行教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





