本文主要是介绍使用DBSCAN划分moon数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用DBSCAN可以对moon数据集进行很好的划分
前文提到,使用kmeans聚类算法时,由于kmeans无法识别非球形簇,对moon数据集的两个半月牙簇进行划分的结果很滑稽,但是另一个聚类算法——DBSCAN成功地解决了这个问题。
DBSCAN有两个重要的参数,eps和min_samples,eps有“点与点之间接近程度”的含义,eps设置的过小意味着没有点是核心样本点(可以理解为,eps过小,从某个随机的点出发,其eps半径内没有其他可以到达的点);min_samples代表着划分出来的簇中最少的样本点个数,如果个数低于这个参数,那么整个簇会被视为噪声。
DBSCAN的局限及DBSCAN的聚类结果
DBSCAN的局限与凝聚聚类一样,都是无法预测新的样本点。但是K-Means可以。
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moonsX, y = make_moons(n_samples=200, noise=0.05, random_state=0)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
dbscan = DBSCAN()
clusters = dbscan.fit_predict(X_scaled)import matplotlib.pyplot as plt
import mglearn
plt.scatter(X_scaled[:,0], X_scaled[:,1], c=clusters, cmap=mglearn.cm2, s=60)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
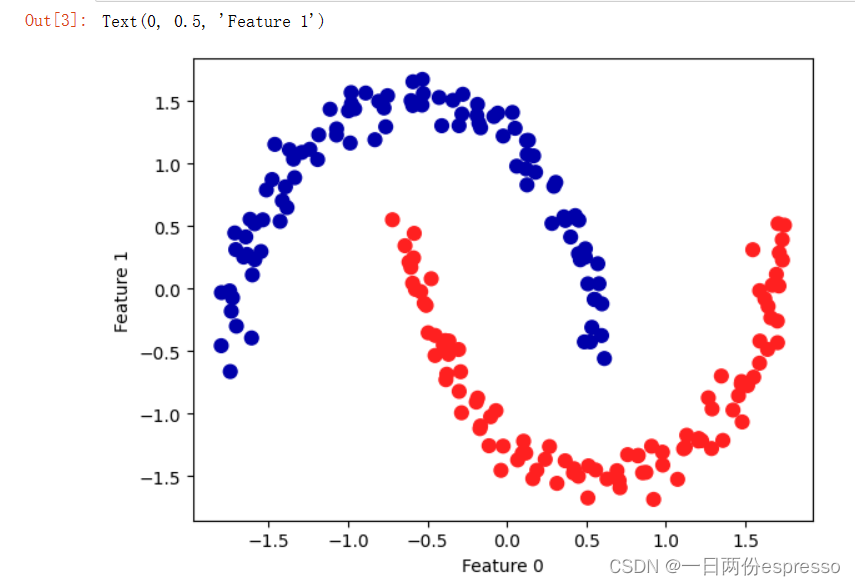
👆可以看到,DBSCAN成功地将moon中的数据点分为两个cluster,使用的参数为默认的eps=0.5。
👇调整参数eps为0.2、0.7,观察结果。
eps = 0.2👇
dbscan = DBSCAN(eps=0.2)
clusters = dbscan.fit_predict(X_scaled)import matplotlib.pyplot as plt
import mglearn
plt.scatter(X_scaled[:,0], X_scaled[:,1], c=clusters, cmap=mglearn.cm2, s=60)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
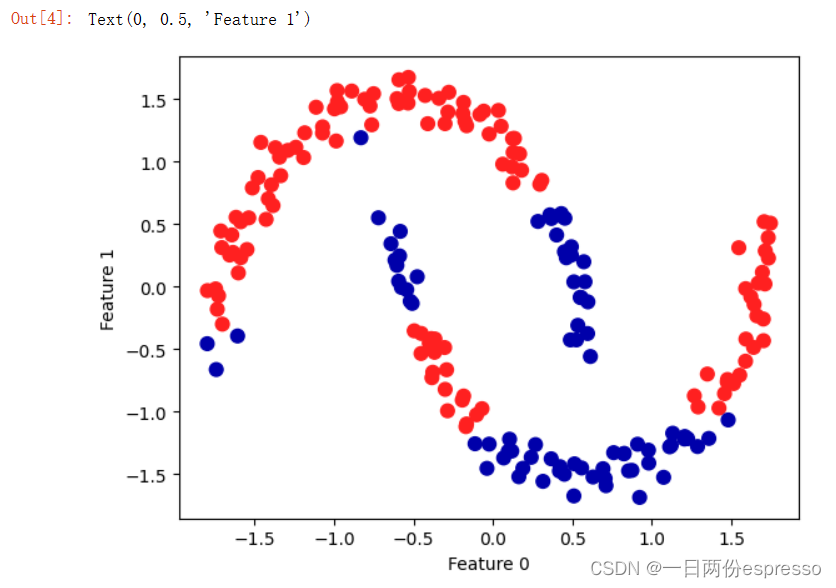
eps=0.7👇
dbscan = DBSCAN(eps=0.7)
clusters = dbscan.fit_predict(X_scaled)import matplotlib.pyplot as plt
import mglearn
plt.scatter(X_scaled[:,0], X_scaled[:,1], c=clusters, cmap=mglearn.cm2, s=60)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
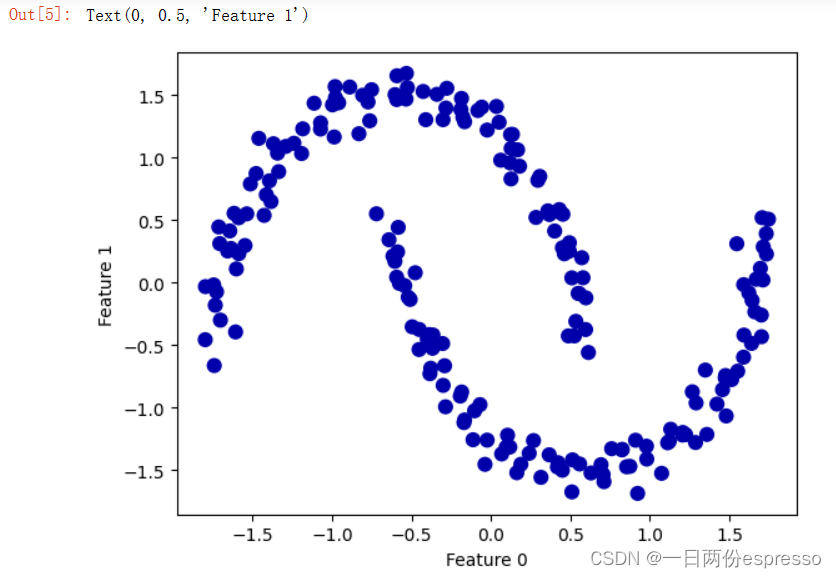
这篇关于使用DBSCAN划分moon数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







