本文主要是介绍linux网络编程之System V 信号量(三):基于生产者-消费者模型实现先进先出的共享内存段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生产者消费者问题:该问题描述了两个共享固定大小缓冲区的进程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
我们可以用信号量解决生产者消费者问题,如下图:
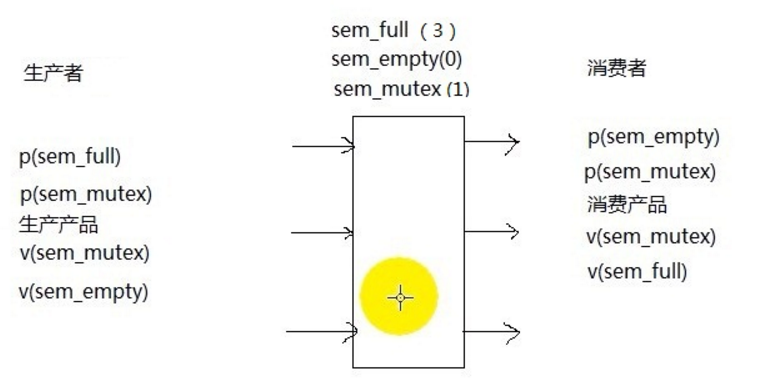
定义3个信号量,sem_full 和 sem_empty 用于生产者进程和消费者进程之间同步,即缓冲区为空才能生产,缓冲区不为空才能消费。由于共享同一块缓冲区,在生产一个产品过程中不能生产/消费产品,在消费一个产品的过程中不能生产/消费产品,故再使用一个 sem_mutex 信号量来约束行为,即进程间互斥。
下面基于生产者消费者模型,来实现一个先进先出的共享内存段:

如上图所示,定义两个结构体,shmhead 是共享内存段的头部,保存了块大小,块数,读写索引。shmfifo 保存了共享内存头部的指针,有效负载的起始地址,创建的共享内存段的shmid,以及3个信号量集的semid。
下面来封装几个函数:
#include "shmfifo.h"
#include <assert.h>shmfifo_t *shmfifo_init(int key, int blksize, int blocks)
{shmfifo_t *fifo = (shmfifo_t *)malloc(sizeof(shmfifo_t));assert(fifo != NULL);memset(fifo, 0, sizeof(shmfifo_t));int shmid;shmid = shmget(key, 0, 0);int size = sizeof(shmhead_t) + blksize * blocks;if (shmid == -1){fifo->shmid = shmget(key, size, IPC_CREAT | 0666);if (fifo->shmid == -1)ERR_EXIT("shmget");fifo->p_shm = (shmhead_t *)shmat(fifo->shmid, NULL, 0);if (fifo->p_shm == (shmhead_t *) - 1)ERR_EXIT("shmat");fifo->p_payload = (char *)(fifo->p_shm + 1);fifo->p_shm->blksize = blksize;fifo->p_shm->blocks = blocks;fifo->p_shm->rd_index = 0;fifo->p_shm->wr_index = 0;fifo->sem_mutex = sem_create(key);fifo->sem_full = sem_create(key + 1);fifo->sem_empty = sem_create(key + 2);sem_setval(fifo->sem_mutex, 1);sem_setval(fifo->sem_full, blocks);sem_setval(fifo->sem_empty, 0);}else{fifo->shmid = shmid;fifo->p_shm = (shmhead_t *)shmat(fifo->shmid, NULL, 0);if (fifo->p_shm == (shmhead_t *) - 1)ERR_EXIT("shmat");fifo->p_payload = (char *)(fifo->p_shm + 1);fifo->sem_mutex = sem_open(key);fifo->sem_full = sem_open(key + 1);fifo->sem_empty = sem_open(key + 2);}return fifo;
}void shmfifo_put(shmfifo_t *fifo, const void *buf)
{sem_p(fifo->sem_full);sem_p(fifo->sem_mutex);memcpy(fifo->p_payload + fifo->p_shm->blksize * fifo->p_shm->wr_index,buf, fifo->p_shm->blksize);fifo->p_shm->wr_index = (fifo->p_shm->wr_index + 1) % fifo->p_shm->blocks;sem_v(fifo->sem_mutex);sem_v(fifo->sem_empty);
}void shmfifo_get(shmfifo_t *fifo, void *buf)
{sem_p(fifo->sem_empty);sem_p(fifo->sem_mutex);memcpy(buf, fifo->p_payload + fifo->p_shm->blksize * fifo->p_shm->rd_index,fifo->p_shm->blksize);fifo->p_shm->rd_index = (fifo->p_shm->rd_index + 1) % fifo->p_shm->blocks;sem_v(fifo->sem_mutex);sem_v(fifo->sem_full);
}void shmfifo_destroy(shmfifo_t *fifo)
{sem_d(fifo->sem_mutex);sem_d(fifo->sem_full);sem_d(fifo->sem_empty);shmdt(fifo->p_shm);shmctl(fifo->shmid, IPC_RMID, 0);free(fifo);
}1、shmfifo_init:先分配shmfifo 结构体的内存,如果尝试打开共享内存失败则创建,创建的共享内存段大小 = shmhead大小 + 块大小×块数目,然后shmat将此共享内存段映射到进程地址空间,然后使用sem_create 创建3个信号量集,每个信号集只有一个信号量,即上面提到的3个信号量,设置每个信号量的资源初始值。如果共享内存已经存在,则直接shmat映射下即可,此时3个信号量集也已经存在,sem_open 打开即可。sem_xxx 系列封装函数参考这里。
2、shmfifo_put:参照第一个生产者消费者的图,除去sem_p,sem_v 操作之外,中间就将buf 的内容memcpy 到对应缓冲区块,然后移动wr_index。
3、shmfifo_get:与shmfifo_put 类似,执行的是相反的操作。
4、shmfifo_destroy:删除3个信号量集,将共享内存段从进程地址空间剥离,删除共享内存段,释放shmfifo 结构体的内存。
下面是生产者程序和消费者程序:
shmfifo_send.c
#include "shmfifo.h"typedef struct stu
{char name[32];int age;
} STU;
int main(void)
{shmfifo_t *fifo = shmfifo_init(1234, sizeof(STU), 3);STU s;memset(&s, 0, sizeof(STU));s.name[0] = 'A';int i;for (i = 0; i < 5; i++){s.age = 20 + i;shmfifo_put(fifo, &s);s.name[0] = s.name[0] + 1;printf("send ok\n");}free(fifo);return 0;
}shmfifo_recv.c
#include "shmfifo.h"typedef struct stu
{char name[32];int age;
} STU;int main(void)
{shmfifo_t *fifo = shmfifo_init(1234, sizeof(STU), 3);STU s;memset(&s, 0, sizeof(STU));int i;for (i = 0; i < 5; i++){shmfifo_get(fifo, &s);printf("name = %s age = %d\n", s.name, s.age);}shmfifo_destroy(fifo);return 0;
}先运行生产者进程,输出如下:
simba@ubuntu:~/Documents/code/linux_programming/UNP/system_v/shmfifo$ ./shmfifo_send
send ok
send ok
send ok
因为共享内存只有3块block,故发送了3次后再次P(semfull)就阻塞了,等待消费者读取数据,现在运行消费者进程
simba@ubuntu:~/Documents/code/linux_programming/UNP/system_v/shmfifo$ ./shmfifo_recv
name = A age = 20
name = B age = 21
name = C age = 22
name = D age = 23
name = E age = 24
因为生产者已经创建了一块共享内存,故消费者只是打开而已,当读取了第一块数据之后,生产者会再次写入,依次输出后两个 send ok,可以推论的是D是重新写到共享内存开始的第一块,E是第二块,类似环形队列。
从输出可以看出,的确实现了数据的先进先出。
PS:在生产实践中也可以看到利用共享内存实现环形缓冲区 or 哈希表 的例子。
参考:《UNP》
转载自http://blog.csdn.net/jnu_simba/article/details/9103059
这篇关于linux网络编程之System V 信号量(三):基于生产者-消费者模型实现先进先出的共享内存段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





