本文主要是介绍python数据分析——认识GBR梯度提升回归模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GBR——Gradient boosting regression——梯度提升回归模型
目 录
1 Boosting
集成学习,Boosting与Bagging的区别
2 Gradient Boosting算法
算法思想,算法实现,残差与负梯度
3 终极组合GBR
1 Boosting
Boosting是一种机器学习算法,常见的机器学习算法有:
决策树算法、朴素贝叶斯算法、支持向量机算法、随机森林算法、人工神经网络算法
Boosting与Bagging算法(回归算法)、关联规则算法、EM(期望最大化)算法、深度学习
1.1 集成学习
背景
我们希望训练得到的模型是一个各方面都稳定表现良好的模型,但是实际情况中得到的却是仅在某方面偏好的模型。集成学习则可以通过多个学习器相结合,来获得比单一学习器更优越的泛化性能。
原理
一般集成学习会通过重采样获得一定数量的样本,然后训练多个弱学习器,采用投票法,即“少数服从多数”原则来选择分类结果,当少数学习器出现错误时,也可以通过多数学习器来纠正结果。
分类
1)个体学习器之间存在较强的依赖性,必须串行生成学习器:boosting类算法;
2) 个体学习器之间不存在强依赖关系,可以并行生成学习器:Bagging类算法
1.2 Boosting与Bagging区别
Boosting
是一种通用的增强基础算法性能的回归分析算法。它可以将弱学习算法提高为强学习算法,可以应用到其它基础回归算法,如线性回归、神经网络等,来提高精度。
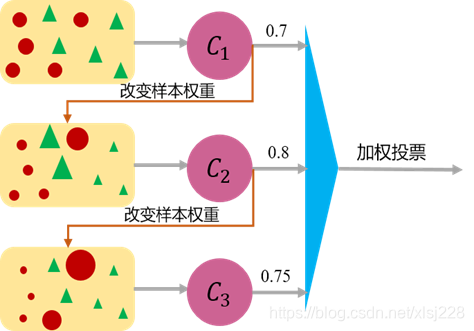
Boosting由于各基学习器之间存在强依赖关系,因此只能串行处理,也就是说Boosting实际上是个迭代学习的过程。
Boosting的工作机制为:
Bagging
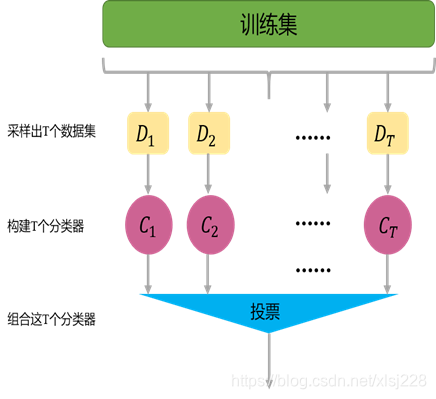
首先从数据集中采样出T个数据集,然后基于这T个数据集,每个训练出一个基分类器,再将这些基分类器进行组合做出预测。Bagging在做预测时,对于分类任务,使用简单的投票法。对于回归任务使用简单平均法。若分类预测时出现两个类票数一样时,则随机选择一个。Bagging非常适合并行处理。
2 Gradient Boosting算法
任何监督学习算法的目标是定义一个损失函数并将其最小化。
Gradient Boosting 的基本思想是:串行地生成多个弱学习器,每个弱学习器的目标是拟合先前累加模型的损失函数的负梯度,使加上该弱学习器后的累积模型损失往负梯度的方向减少。
举个简单的例子
假设有个样本真实值为 10,第一个弱学习器拟合结果为7,则残差为10-7=3;
使残差 3 作为下一个学习器的拟合目标,第二个弱学习其拟合结果为2;
则这两个弱学习器组合而成的 Boosting 模型对于样本的预测为7+2=9;
以此类推可以继续增加弱学习器以提高性能。
和其他boost方法一样,梯度提升方法也是通过迭代的方法联合弱”学习者”联合形成一个强学习者。
2.1 算法思想

2.2 算法实现
1)初始化模型函数:![]()
2)For m = 1 to M:
使用损失函数的负梯度在当前模型 Fm-1(x)上的值近似代替残差:![]()
使用基学习器 h(x)拟合近似的残差值:![]()
计算最优的ɤ:![]()
3)更新模型 :![]()
4)返回Fm(x)
2.3 残差与负梯度

3 终极组合GBR
GBR就是弱学习器是回归算法。
常见的回归算法:
线性回归(Linear Regression)
逻辑回归(Logistic Regression)
多项式回归(Polynomial Regression)
逐步回归(Stepwise Regression)
岭回归(Ridge Regression)
套索回归(Lasso Regression)
弹性回归(ElasticNet Regression)
其他GB算法:
GBRT (Gradient BoostRegression Tree)
梯度提升回归树
GBDT (Gradient BoostDecision Tree)
梯度提升决策树
这篇关于python数据分析——认识GBR梯度提升回归模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




