本文主要是介绍Mask TextSpotter: An End-to-End TrainableNeural Network for Spotting Text withArbitrary Shapes 中英对翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mask TextSpotter:一种用于识别任意形状文本的端到端可训练神经网络
摘要
最近,基于深度神经网络的模型在场景文本检测和识别领域占据主导地位。在本文中,我们研究了场景文本识别的问题,其目的是在自然图像中同时进行文本检测和识别。我们提出了一个用于场景文本识别的端到端可训练神经网络模型。该模型被命名为Mask TextSpotter,其灵感来源于新近发表的Mask R-CNN。与之前的方法不同,这些方法也是通过端到端可训练的深度神经网络来完成文本发现。Mask TextSpotter利用了简单而流畅的端到端学习程序,在这个过程中,通过语义分割来做到精确的文本检测和识别。此外,它在处理不规则形状的文本实例方面优于以前的方法,例如。弯曲的文本。在ICDAR2013、ICDAR2015和Total-Text上进行的实验表明,所提出的方法在场景文本检测和端到端文本检测方面取得了最先进的结果 在场景文本检测和端到端文本识别任务中都取得了最先进的结果。
Abstract. Recently, models based on deep neural networks have dominated the fields of scene text detection and recognition. In this paper, we investigate the problem of scene text spotting, which aims at simultaneous text detection and recognition in natural images. An end-to-end trainable neural network model for scene text spotting is proposed. The proposed model, named as Mask TextSpotter, is inspired by the newly published work Mask R-CNN. Different from previous methods that also accomplish text spotting with end-to-end trainable deep neural networks, Mask TextSpotter takes advantage of simple and smooth end-to-end learning procedure, in which precise text detection and recognition are acquired via semantic segmentation. Moreover, it is superior to previous methods in handling text instances of irregular shapes, for example, curved text. Experiments on ICDAR2013, ICDAR2015 and Total-Text demonstrate that the proposed method achieves state-of-the-art results in both scene text detection and end-to-end text recognition tasks.
1 介绍
近年来,场景文本检测和识别吸引了计算机视觉界越来越多的研究兴趣,特别是在神经网络的复兴和图像数据集的增长之后。场景文本检测和识别提供了一种自动、快速的方法来获取自然场景中体现的文本信息,有利于各种现实世界的应用,如地理定位[58]、即时翻译和盲人援助。场景文本识别的目的是同时定位和识别自然场景中的文本,之前已经有很多作品研究过[49,21]。然而,除了[27]和[3],在大多数作品中,文本检测和随后的识别是分开处理的。文本区域首先由经过训练的检测器从原始图像中猎取,然后送入识别模块。这个过程看起来简单而自然,但可能会导致检测和识别的次优表现,因为这两项任务是高度相关和互补的。一方面,检测的质量在很大程度上决定了识别的准确性;另一方面,识别的结果可以提供反馈,帮助在检测阶段拒绝假阳性。
In recent years, scene text detection and recognition have attracted growing research interests from the computer vision community, especially after the revival of neural networks and growth of image datasets. Scene text detection and recognition provide an automatic, rapid approach to access the textual information embodied in natural scenes, benefiting a variety of real-world applications, such as geo-location [58], instant translation, and assistance for the blind. Scene text spotting, which aims at concurrently localizing and recognizing text from natural scenes, have been previously studied in numerous works [49,21]. However, in most works, except [27] and [3], text detection and subsequent recognition are handled separately. Text regions are first hunted from the original image by a trained detector and then fed into a recognition module. This procedure seems simple and natural, but might lead to sub-optimal performances for both detection and recognition, since these two tasks are highly correlated and complementary. On one hand, the quality of detections larges determines the accuracy of recognition; on the other hand, the results of recognition can provide feedback to help reject false positives in the phase of detection.
最近,有两种方法[27, 3]被提出,它们为场景文本识别设计了端到端的可训练框架。受益于检测和识别之间的互补性,这些统一的模型大大超过了以前的竞争对手。然而,[27]和[3]有两个主要缺点。首先,它们都不能完全以端到端的方式进行训练。[27]在训练期应用了curriculum learning paradigm[1],在早期迭代中锁定文本识别子网络,并仔细选择每个阶段的训练数据。Busta等人[3]起初分别对检测和识别的网络进行预训练,然后联合训练,直到收敛。主要有两个原因阻止了[27]和[3]以平稳、端到端的方式训练模型。一个是文本识别部分需要准确的位置进行训练,而早期迭代的位置通常是不准确的。另一个是采用的LSTM[17]或CTC损失[11]比一般的CNN难以优化。[27]和[3]的第二个局限性在于这些方法只关注于阅读水平或方向的文本。然而,现实世界场景中的文本实例的形状可能会有很大的不同,从水平或定向的,到弯曲的形式。
Recently, two methods [27, 3] that devise end-to-end trainable frameworks for scene text spotting have been proposed. Benefiting from the complementarity between detection and recognition, these unified models significantly outperform previous competitors. However, there are two major drawbacks in [27] and [3]. First, both of them can not be completely trained in an end-to-end manner. [27] applied a curriculum learning paradigm [1] in the training period, where the sub-network for text recognition is locked at the early iterations and the training data for each period is carefully selected. Busta et al. [3] at first pre-train the networks for detection and recognition separately and then jointly train them until convergence. There are mainly two reasons that stop [27] and [3] from training the models in a smooth, end-to-end fashion. One is that the text recognition part requires accurate locations for training while the locations in the early iterations are usually inaccurate.The other is that the adopted LSTM [17] or CTC loss [11] are difficult to optimize than general CNNs. The second limitation of [27] and [3] lies in that these methods only focus on reading horizontal or oriented text. However, the shapes of text instances in real-world scenarios may vary significantly, from horizontal or oriented, to curved forms.
在本文中,我们提出了一个名为Mask TextSpotter的文本识别器,它可以检测和识别任意形状的文本实例。这里,任意形状是指现实世界中各种形式的文本实例。受Mask RCNN[13]的启发,它可以生成物体的形状掩码,我们通过分割实例文本区域来检测文本。因此,我们的检测器能够检测任意形状的文本。此外,与之前基于序列的识别方法[45, 44, 26]不同,这些方法是为一维序列设计的,我们通过二维空间的语义分割来识别文本,以解决阅读不规则文本实例的问题。另一个优点是,它不需要准确的位置来识别。因此,检测任务和识别任务可以完全进行端到端的训练,并受益于特征共享和联合优化。
In this paper, we propose a text spotter named as Mask TextSpotter, which can detect and recognize text instances of arbitrary shapes. Here, arbitrary shapes mean various forms text instances in real world. Inspired by Mask RCNN [13], which can generate shape masks of objects, we detect text by segment the instance text regions. Thus our detector is able to detect text of arbitrary shapes. Besides, different from the previous sequence-based recognition methods [45, 44, 26] which are designed for 1-D sequence, we recognize text via semantic segmentation in 2-D space, to solve the issues in reading irregular text instances. Another advantage is that it does not require accurate locations for recognition. Therefore, the detection task and recognition task can be completely trained end-to-end, and benefited from feature sharing and joint optimization.

图1:不同的文本点化方法的图示。左边是水平方向的文本识别方法[30, 27];中间是定向的文本识别方法[3];右边是我们提出的方法。方法[3];右边是我们提出的方法。绿色边框:检测结果 结果;绿色背景中的红色文字:识别结果。
Fig. 1: Illustrations of different text spotting methods. The left presents horizontal text spotting methods [30, 27]; The middle indicates oriented text spotting methods [3]; The right is our proposed method. Green bounding box: detection result; Red text in green background: recognition result.
我们在包括水平、定向和弯曲文本的数据集上验证了我们模型的有效性。结果表明,所提出的算法在文本检测和端到端文本识别任务中都有优势。特别是在ICDAR2015上,在单一规模的评估中,我们的方法在检测任务上达到了0.86的F-Measure,在端到端识别任务上超过了之前的顶级表现者13.2%-25.3%。
We validate the effectiveness of our model on the datasets that include horizontal, oriented and curved text. The results demonstrate the advantages of the proposed algorithm in both text detection and end-to-end text recognition tasks. Specially, on ICDAR2015, evaluated at a single scale, our method achieves an F-Measure of 0.86 on the detection task and outperforms the previous top performers by 13.2% − 25.3% on the end-to-end recognition task.
本文的主要贡献有四个方面。(1) 我们提出了一个用于文本识别的端到端可训练模型,它享有一个简单、流畅的训练方案。(2) 本文提出的方法可以检测和识别各种形状的文本,包括水平的、定向的和弯曲的文本。(3) 与以前的方法相比,我们的方法中精确的文本检测和识别是通过语义分割完成的。(4) 我们的方法在各种基准上的文本检测和文本识别方面都取得了最先进的表现。
The main contributions of this paper are four-fold. (1) We propose an endto-end trainable model for text spotting, which enjoys a simple, smooth training scheme. (2) The proposed method can detect and recognize text of various shapes, including horizontal, oriented, and curved text. (3) In contrast to previous methods, precise text detection and recognition in our method are accomplished via semantic segmentation. (4) Our method achieves state-of-the-art performances in both text detection and text spotting on various benchmarks.
2 Related Work
2.1 场景文本检测 Scene Text Detection
在场景文本识别系统中,文本检测起着重要作用[59]。已经提出了大量的方法来检测场景文本[7, 36, 37, 50, 19, 23, 54, 21, 47, 54, 56, 30, 52, 55, 34, 15, 48, 43, 57, 16, 35, 31] 。在[21]中,Jaderberg等人使用Edge Boxes[60]来生成 proposals,并通过回归来完善候选框。Zhang等人[54]通过利用文本的对称性来检测场景文本。改编自Faster R-CNN[40]和SSD[33],并进行了精心设计的修改,[56,30]被提出来检测水平词。
In scene text recognition systems, text detection plays an important role [59]. A large number of methods have been proposed to detect scene text [7, 36, 37, 50, 19, 23, 54, 21, 47, 54, 56, 30, 52, 55, 34, 15, 48, 43, 57, 16, 35, 31]. In [21], Jaderberg et al. use Edge Boxes [60] to generate proposals and refine candidate boxes by regression. Zhang et al. [54] detect scene text by exploiting the symmetry property of text. Adapted from Faster R-CNN [40] and SSD [33] with well-designed modifications, [56, 30] are proposed to detect horizontal words.
多方向的场景文本检测已经成为最近的一个热门话题。Yao等人[52]和Zhang等人[55]通过语义分割检测多方位场景文本。Tian等人[48]和Shi等人[43]提出的方法首先检测文本片段,然后通过空间关系或链接预测将它们链接成文本实例。Zhou等人[57]和He等人[16]直接从密集的分割图中回归文本框。Lyu等人[35]提出检测和分组文本的角点来生成文本框。Liao等人[31]提出了对旋转敏感的回归,用于定向场景文本检测。
Multi-oriented scene text detection has become a hot topic recently. Yao et al. [52] and Zhang et al. [55] detect multi-oriented scene text by semantic segmentation. Tian et al. [48] and Shi et al. [43] propose methods which first detect text segments and then link them into text instances by spatial relationship or link predictions. Zhou et al. [57] and He et al. [16] regress text boxes directly from dense segmentation maps. Lyu et al. [35] propose to detect and group the corner points of the text to generate text boxes. Rotation-sensitive regression for oriented scene text detection is proposed by Liao et al. [31].
与水平或多方位场景文本检测的普及相比,关注任意形状文本实例的工作很少。最近,由于现实生活场景中的应用需求,任意形状文本的检测逐渐引起了研究人员的关注。在[41]中,Risnumawan等人提出了一个基于文本对称性的任意文本检测系统。在[4]中,提出了一个专注于曲线方向文本检测的数据集。与上述大多数方法不同的是,我们提出通过实例分割来检测场景文本,可以检测任意形状的文本。
Compared to the popularity of horizontal or multi-oriented scene text detection, there are few works focusing on text instances of arbitrary shapes. Recently, detection of text with arbitrary shapes has gradually drawn the attention of researchers due to the application requirements in the real-life scenario. In [41], Risnumawan et al. propose a system for arbitrary text detection based on text symmetry properties. In [4], a dataset which focuses on curve orientation text detection is proposed. Different from most of the above-mentioned methods, we propose to detect scene text by instance segmentation which can detect text with arbitrary shapes.
2.2 场景文本识别 Scene Text Recognition
场景文本识别[53, 46]旨在将检测到的或裁剪过的图像区域解码为字符序列。以前的场景文本识别方法可以大致分为三个分支:基于字符的方法、基于单词的方法和基于序列的方法。基于字符的识别方法[2,22]大多首先定位单个字符,然后将其识别并分组为单词。在[20]中,Jaderberg等人提出了一种基于单词的方法,该方法将文本识别视为一个常见的英语单词(90k)分类问题。基于序列的方法将文本识别作为一个序列标记问题来解决。在[44]中,Shi等人使用CNN和RNN对图像特征进行建模,并通过CTC[11]输出识别的序列。在[26,45]中,Lee等人和Shi等人通过基于注意力的序列到序列模型来识别场景文本。
Scene text recognition [53, 46] aims at decoding the detected or cropped image regions into character sequences. The previous scene text recognition approaches can be roughly split into three branches: character-based methods, word-based methods, and sequence-based methods. The character-based recognition methods [2, 22] mostly first localize individual characters and then recognize and group them into words. In [20], Jaderberg et al. propose a word-based method which treats text recognition as a common English words (90k) classification problem. Sequence-based methods solve text recognition as a sequence labeling problem. In [44], Shi et al. use CNN and RNN to model image features and output the recognized sequences with CTC [11]. In [26, 45], Lee et al. and Shi et al. recognize scene text via attention based sequence-to-sequence model.
我们框架中提议的文本识别组件可以被归类为基于字符的方法。然而,与以前基于字符的方法相比,我们使用FCN[42]来同时定位和分类字符。此外,与基于序列的方法相比,我们的方法更适合处理不规则的文本(多方向的文本,弯曲的文本等),这些方法是为一维序列设计的。
The proposed text recognition component in our framework can be classified as a character-based method. However, in contrast to previous character-based approaches, we use an FCN [42] to localize and classify characters simultaneously. Besides, compared with sequence-based methods which are designed for a 1-D sequence, our method is more suitable to handle irregular text (multi-oriented text, curved text et al.).
2.3 场景文本的发现 Scene Text Spotting
以前的大多数文本识别方法[21, 30, 12, 29]将识别过程分为两个阶段。他们首先使用场景文本检测器[21, 30, 29]来定位文本实例,然后使用文本识别器[20, 44]来获取识别的文本。在[27,3]中,Li等人和Busta等人提出了端到端的方法,在一个统一的网络中定位和识别文本,但需要相对复杂的训练程序。与这些方法相比,我们提出的文本定位器不仅可以完全进行端到端的训练,而且还具有检测和识别任意形状(水平、定向和弯曲)场景文本的能力。
Most of the previous text spotting methods [21, 30, 12, 29] split the spotting process into two stages. They first use a scene text detector [21, 30, 29] to localize text instances and then use a text recognizer [20, 44] to obtain the recognized text. In [27, 3], Li et al. and Busta et al. propose end-to-end methods to localize and recognize text in a unified network, but require relatively complex training procedures. Compared with these methods, our proposed text spotter can not only be trained end-to-end completely, but also has the ability to detect and recognize arbitrary-shape (horizontal, oriented, and curved) scene text.
2.4 一般物体检测和语义分割 General Object Detection and Semantic Segmentation
随着深度学习的兴起,一般的物体检测和语义分割都取得了很大的发展。大量的物体检测和分割方法[9, 8, 40, 6, 32, 33, 39, 42, 5, 28, 13]已经被提出。受益于这些方法,场景文本检测和识别在过去几年中取得了明显的进展。我们的方法也受到这些方法的启发。具体来说,我们的方法是由一个通用的物体实例分割模型Mask R-CNN[13]改编的。然而,我们的方法的mask branch与Mask R-CNN中的mask branch存在着关键的区别。我们的mask branch不仅可以分割文本区域,还可以预测字符概率图,这意味着我们的方法可以用来识别字符图内的实例序列,而不是仅仅预测一个物体掩码。
With the rise of deep learning, general object detection and semantic segmentation have achieved great development. A large number of object detection and segmentation methods [9, 8, 40, 6, 32, 33, 39, 42, 5, 28, 13] have been proposed. Benefited from those methods, scene text detection and recognition have achieved obvious progress in the past few years. Our method is also inspired by those methods. Specifically, our method is adapted from a general object instance segmentation model Mask R-CNN [13]. However, there are key differences between the mask branch of our method and that in Mask R-CNN. Our mask branch can not only segment text regions but also predict character probability maps, which means that our method can be used to recognize the instance sequence inside character maps rather than predicting an object mask only.
3 Methodology
所提出的方法是一个端到端的可训练的文本检测器,它可以处理各种形状的文本。它由一个基于实例分割的文本检测器和一个基于字符分割的文本识别器组成。
The proposed method is an end-to-end trainable text spotter, which can handle various shapes of text. It consists of an instance-segmentation based text detector and a character-segmentation based text recognizer.
3.1 框架 Framework
我们提出的方法的整体架构见图2。从功能上看,该框架由四个部分组成:一个作为骨干的特征金字塔网络(FPN)[32],一个用于生成文本建议的区域建议网络(RPN)[40],一个用于边界框回归的快速R-CNN[40],一个用于文本实例分割和字符分割的mask branch。在训练阶段,首先由RPN生成大量的文本建议,然后将建议的RoI特征输入快速R-CNN分支和mask branch,以生成准确的文本候选框、文本实例分割图和字符分割图。
The overall architecture of our proposed method is presented in Fig. 2. Functionally, the framework consists of four components: a feature pyramid network (FPN) [32] as backbone, a region proposal network (RPN) [40] for generating text proposals, a Fast R-CNN [40] for bounding boxes regression, a mask branch for text instance segmentation and character segmentation. In the training phase, a lot of text proposals are first generated by RPN, and then the RoI features of the proposals are fed into the Fast R-CNN branch and the mask branch to generate the accurate text candidate boxes, the text instance segmentation maps, and the character segmentation maps.
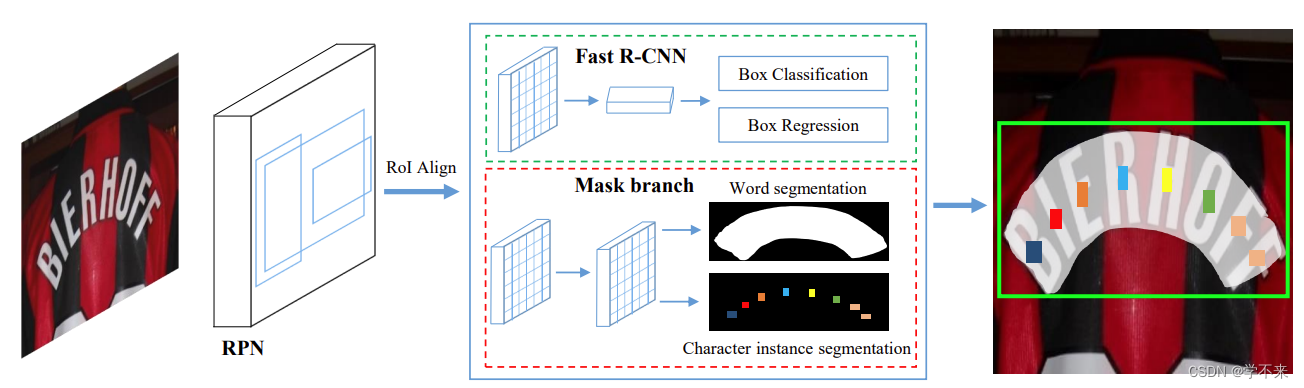
Fig. 2: Illustration of the architecture of the our method.
主干 自然界图像中的文字大小不一。为了建立所有尺度的高级语义特征图,我们采用了深度为50的特征金字塔结构[32]主干和ResNet[14]。FPN采用自上而下的结构,从单一尺度的输入中融合不同分辨率的特征,以边际成本提高准确性。
Backbone Text in nature images are various in sizes. In order to build high-level semantic feature maps at all scales, we apply a feature pyramid structure [32] backbone with ResNet [14] of depth 50. FPN uses a top-down architecture to fuse the feature of different resolutions from a single-scale input, which improves accuracy with marginal cost.
RPN RPN被用来为后续的Fast R-CNN和mask branch生成文本建议。按照[32],我们根据锚的大小在不同的阶段分配锚。具体来说,在五个阶段{P2, P3, P4, P5, P6}上,锚的面积被设置为{322 , 642 , 1282 , 2562 , 5122}像素。与[40]一样,每个阶段也采用不同的长宽比{0.5, 1, 2}。通过这种方式,RPN可以处理各种尺寸和长宽比的文本。RoI Align[13]被用来提取 proposals 的区域特征。与RoI Pooling[8]相比,RoI Align保留了更准确的位置信息,这对mask branch的分割任务相当有利。请注意,没有像以前的工作[30, 15, 34]那样对文本进行特殊的设计,如文本的特殊长宽比或锚点的方向。
RPN RPN is used to generate text proposals for the subsequent Fast R-CNN and mask branch. Following [32], we assign anchors on different stages depending on the anchor size. Specifically, the area of the anchors are set to {322 , 642 , 1282 , 2562 , 5122} pixels on five stages {P2, P3, P4, P5, P6} respectively. Different aspect ratios {0.5, 1, 2} are also adopted in each stages as in [40]. In this way, the RPN can handle text of various sizes and aspect ratios. RoI Align [13] is adapted to extract the region features of the proposals. Compared to RoI Pooling [8], RoI Align preserves more accurate location information, which is quite beneficial to the segmentation task in the mask branch. Note that no special design for text is adopted, such as the special aspect ratios or orientations of anchors for text, as in previous works [30, 15, 34].
Fast R-CNN Fast R-CNN分支包括一个分类任务和一个回归任务。该分支的主要功能是为检测提供更准确的边界框。Fast R-CNN的输入是7×7的分辨率,由RoI Align从RPN产生的建议中生成。
Fast R-CNN The Fast R-CNN branch includes a classification task and a regression task. The main function of this branch is to provide more accurate bounding boxes for detection. The inputs of Fast R-CNN are in 7 ×7 resolution, which are generated by RoI Align from the proposals produced by RPN.
Mask Branch mask branch有两个任务,包括一个全局文本实例分割任务和一个字符分割任务。如图3所示,通过四个卷积层和一个去卷积层,给一个输入的RoI(其大小固定为16*64),mask branch预测出38个maps(大小为32*128),包括一个全局文本实例map,36个字符maps和一个字符背景maps。全局文本实例maps可以给出文本区域的准确定位,而不管文本实例的形状如何。字符maps 是36个字符的 maps,包括26个字母和10个阿拉伯数字。字符的背景图,不包括字符区域,也需要进行后处理。
Mask Branch There are two tasks in the mask branch, including a global text instance segmentation task and a character segmentation task. As shown in Fig. 3, giving an input RoI, whose size is fixed to 16 ∗ 64, through four convolutional layers and a de-convolutional layer, the mask branch predicts 38 maps (with 32 ∗ 128 size), including a global text instance map, 36 character maps, and a background map of characters. The global text instance map can give accurate localization of a text region, regardless of the shape of the text instance. The character maps are maps of 36 characters, including 26 letters and 10 Arabic numerals. The background map of characters, which excludes the character regions, is also needed for post-processing.
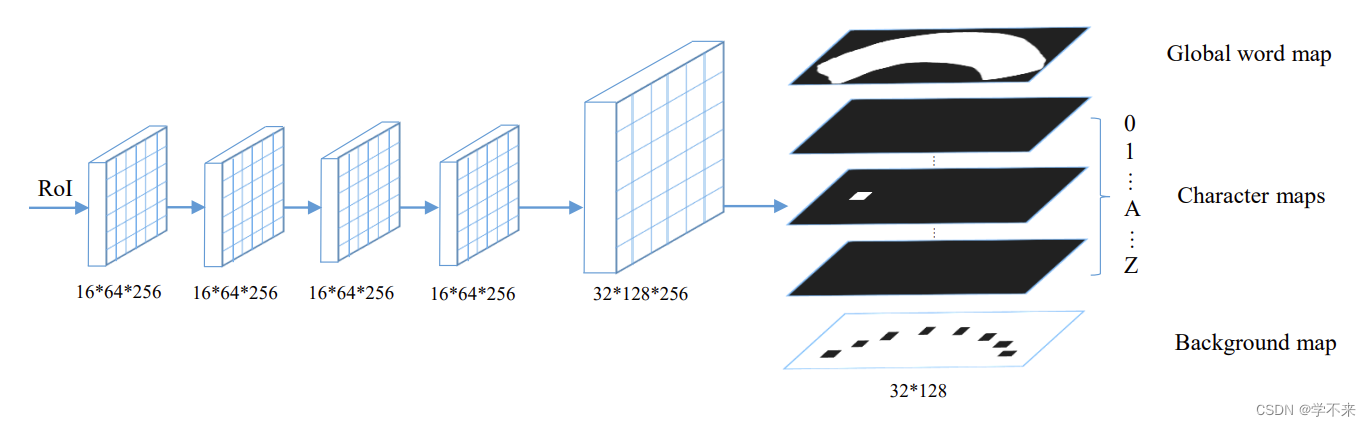
图3:mask branch的说明。随后,有四个卷积层,一个去卷积层,以及最后一个卷积层,预测38个通道的地图(1个用于全局文本实例地图;36个用于字符地图;1个用于字符的背景地图)。
Fig. 3: Illustration of the mask branch. Subsequently, there are four convolutional layers, one de-convolutional layer, and a final convolutional layer which predicts maps of 38 channels (1 for global text instance map; 36 for character maps; 1 for background map of characters).
3.2 标签生成 Label Generation
对于具有输入图像 I 和相应的 ground truth 的训练样本,我们为RPN、Fast R-CNN 和mask branch生成目标。一般来说,ground truth 包含 P = {p1, p2...pm} 和 C = {c1 = (cc1, cl1), c2 = (cc2, cl2), ..., cn = (ccn, cln)},其中 pi 是代表文本区域定位的多边形,ccj 和 clj 分别是一个字符的类别和位置。请注意,在我们的方法中,C 并不是所有训练样本都需要的
For a training sample with the input image I and the corresponding ground truth, we generate targets for RPN, Fast R-CNN and mask branch. Generally, the ground truth contains P = {p1, p2...pm} and C = {c1 = (cc1, cl1), c2 = (cc2, cl2), ..., cn = (ccn, cln)}, where pi is a polygon which represents the localization of a text region, ccj and clj are the category and location of a character respectively. Note that, in our method C is not necessary for all training samples
我们首先将多边形转化为水平矩形,以最小的面积覆盖多边形。然后我们按照[8, 40, 32]为RPN和Fast R-CNN生成目标。对于基于ground truth p,c (可能不存在)的 mask branch,以及 RPN 提出的proposal,有两种目标图: 一种是用于文本实例分割的全局图,另一种是用于字符语义分割的字符图。给定一个积极的proposal r,我们首先使用[8, 40, 32]的匹配机制来获得最佳匹配的水平矩形。可以进一步获得相应的多边形以及字符(如果有的话)。接下来,匹配的多边形和字符框被移位和调整大小,以对准proposals 和H×W的目标图,如以下公式。
We first transform the polygons into horizontal rectangles which cover the polygons with minimal areas. And then we generate targets for RPN and Fast R-CNN following [8, 40, 32]. There are two types of target maps to be generated for the mask branch with the ground truth P, C (may not exist) as well as the proposals yielded by RPN: a global map for text instance segmentation and a character map for character semantic segmentation. Given a positive proposal r, we first use the matching mechanism of [8, 40, 32] to obtain the best matched horizontal rectangle. The corresponding polygon as well as characters (if any) can be obtained further. Next, the matched polygon and character boxes are shifted and resized to align the proposal and the target map of H × W as the following formulas:
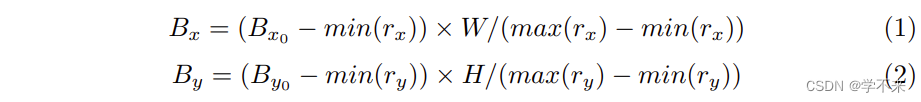
其中(Bx, By)和(Bx0 , By0)是多边形和所有字符框的更新和原始顶点;(rx, ry)是proposal r的顶点。
where (Bx, By) and (Bx0 , By0 ) are the updated and original vertexes of the polygon and all character boxes; (rx, ry) are the vertexes of the proposal r.
之后,只需在零初始化掩码上绘制归一化的多边形,并在多边形区域内填充数值1,就可以生成目标全局图。图4a显示了字符图的生成过程。我们首先通过固定中心点和将边缩短到原始边的四分之一来缩小所有的字符边界框。然后,将缩减后的字符边界框内的像素值设置为其相应的类别指数,缩减后的字符边界框外的像素值设置为0。如果没有字符边界框注释,所有的值都设置为-1。
After that, the target global map can be generated by just drawing the normalized polygon on a zero-initialized mask and filling the polygon region with the value 1. The character map generation is visualized in Fig. 4a. We first shrink all character bounding boxes by fixing their center point and shortening the sides to the fourth of the original sides. Then, the values of the pixels in the shrunk character bounding boxes are set to their corresponding category indices and those outside the shrunk character bounding boxes are set to 0. If there are no character bounding boxes annotations, all values are set to −1.
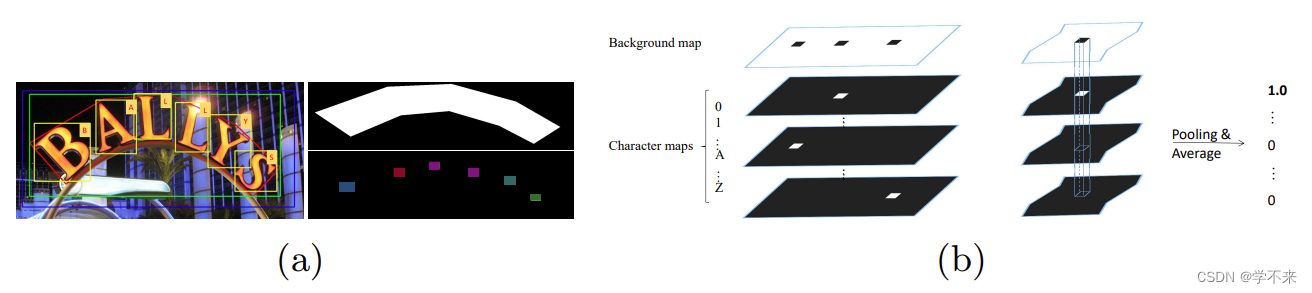
图4:(a)mask branch的标签生成。左图:蓝色方框是由RPN产生的proposal ,红色多边形和黄色方框是 ground truth 的多边形和字符框,绿色方框是以最小面积覆盖多边形的水平矩形。右图:全局图(顶部)和字符图(底部)。(b) 像素投票算法的概述。左图:预测的字符图;右图:对于每个连接的区域,我们通过对相应区域的概率值进行平均来计算每个字符的分值。
Fig. 4: (a) Label generation of mask branch. Left: the blue box is a proposal yielded by RPN, the red polygon and yellow boxes are ground truth polygon and character boxes, the green box is the horizontal rectangle which covers the polygon with minimal area. Right: the global map (top) and the character map (bottom). (b) Overview of the pixel voting algorithm. Left: the predicted character maps; right: for each connected regions, we calculate the scores for each character by averaging the probability values in the corresponding region.
3.3 Optimization
如第3.1节所述,我们的模型包括多个任务。我们自然地定义了一个多任务损失函数
As discussed in Sec. 3.1, our model includes multiple tasks. We naturally define a multi-task loss function
![]()
其中Lrpn 和 Lrcnn 是RPN和Fast R-CNN的损失函数,与[40]和[8]中的相同。掩码损失Lmask 包括一个全局文本实例分割损失Lglobal和一个字符分割损失Lchar。
where Lrpn and Lrcnn are the loss functions of RPN and Fast R-CNN, which are identical as these in [40] and [8]. The mask loss Lmask consists of a global text instance segmentation loss Lglobal and a character segmentation loss Lchar:

其中,Lglobal 是平均的二进制交叉熵损失,Lchar 是加权的空间软最大损失。在这项工作中,α1、α2、β,根据经验设定为1.0。
where Lglobal is an average binary cross-entropy loss and Lchar is a weighted spatial soft-max loss. In this work, the α1, α2, β, are empirically set to 1.0.
文本实例分割的损失 文本实例分割任务的输出是一个单一的地图。设N为全局地图中的像素数,yn为像素标签(yn∈0,1),xn为输出像素,我们定义Lglobal 如下。
Text instance segmentation loss The output of the text instance segmentation task is a single map. Let N be the number of pixels in the global map, yn be the pixel label (yn ∈ 0, 1), and xn be the output pixel, we define the Lglobal as follows:
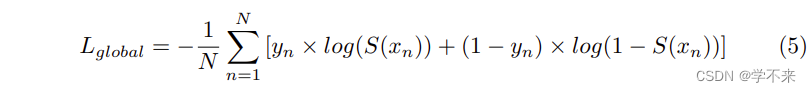
where S(x) is a sigmoid function.
字符分割损失 字符分割的输出由37张图组成,对应于37个类(36个字符类和 背景类)。设T为类的数量,N为每个图中的像素数量。每个地图的像素数。输出的地图X可以被看作是一个N×T矩阵。通过这种方式。加权空间 soft-max 损失可以定义如下。
Character segmentation loss The output of the character segmentation consists of 37 maps, which correspond to 37 classes (36 classes of characters and the background class). Let T be the number of classes, N be the number of pixels in each map. The output maps X can be viewed as an N × T matrix. In this way, the weighted spatial soft-max loss can be defined as follows:

其中,Y是X的对应的 ground truth。权重 w 用于平衡 positives(字符类)和背景类的损失值。设背景像素数为 Nneg,背景类指数为0,权重可计算为:。
where Y is the corresponding ground truth of X. The weight W is used to balance the loss value of the positives (character classes) and the background class. Let the number of the background pixels be Nneg, and the background class index be 0, the weights can be calculated as:
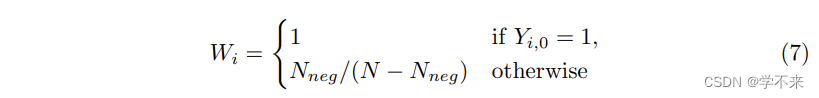
请注意,在推论中,应用了一个sigmoid函数和一个soft-max函数来分别生成全局图和字符分割图。
Note that in inference, a sigmoid function and a soft-max function are applied to generate the global map and the character segmentation maps respectively.
3.4 Inference
与mask branch的输入 roi 来自 RPN 的训练过程不同,在推理阶段,我们使用 Fast R-CNN 的输出作为方案来生成预测的全局映射和字符映射,因为 Fast R-CNN 的输出更加精确。
Different from the training process where the input RoIs of mask branch come from RPN, in the inference phase, we use the outputs of Fast R-CNN as proposals to generate the predicted global maps and character maps, since the Fast R-CNN outputs are more accurate.
特别是,推论过程如下:首先,输入测试图像,我们获得Fast R-CNN的输出,如[40],并通过NMS过滤掉多余的候选框;然后,保留的建议被送入掩码分支,生成全局图和字符图;最后,预测的多边形可以直接通过计算全局图上文本区域的轮廓得到,字符序列可以通过我们提出的像素投票算法在字符图上生成。
Specially, the processes of inference are as follows: first, inputting a test image, we obtain the outputs of Fast R-CNN as [40] and filter out the redundant candidate boxes by NMS; and then, the kept proposals are fed into the mask branch to generate the global maps and the character maps; finally the predicted polygons can be obtained directly by calculating the contours of text regions on global maps, the character sequences can be generated by our proposed pixel voting algorithm on character maps.
像素投票 我们通过我们提出的像素投票算法将预测的字符图解码为字符序列。我们首先对背景图进行二值化处理,其数值从0到255,阈值为192。然后,我们根据二值化地图中的连接区域获得所有的字符区域。我们计算出所有字符图中每个区域的平均值。这些值可以被看作是该区域的字符类概率。具有最大均值的字符类将被分配到该区域。之后,我们根据英语的书写习惯,将所有的字符从左到右分组。
Pixel Voting We decode the predicted character maps into character sequences by our proposed pixel voting algorithm. We first binarize the background map, where the values are from 0 to 255, with a threshold of 192. Then we obtain all character regions according to connected regions in the binarized map. We calculate the mean values of each region for all character maps. The values can be seen as the character classes probability of the region. The character class with the largest mean value will be assigned to the region. After that, we group all the characters from left to right according to the writing habit of English.
加权编辑距离 编辑距离可以用来寻找一个预测序列中与给定词库最匹配的词。然而,可能有多个词同时与最小编辑距离相匹配,而算法无法决定哪一个是最好的。造成上述问题的主要原因是,原始编辑距离算法中的所有操作(删除、插入、替换)都有相同的成本,这实际上是不合理的。
Weighted Edit Distance Edit distance can be used to find the best-matched word of a predicted sequence with a given lexicon. However, there may be multiple words matched with the minimal edit distance at the same time, and the algorithm can not decide which one is the best. The main reason for the abovementioned issue is that all operations (delete, insert, replace) in the original edit distance algorithm have the same costs, which does not make sense actually.
受[51]的启发,我们提出了一种加权编辑距离算法。如图5所示,与编辑距离不同的是,我们提出的加权编辑距离的成本取决于由像素投票产生的字符概率。在数学上,两个长度分别为|a|和|b|的字符串a和b之间的加权编辑距离可以描述为
,其中
Inspired by [51], we propose a weighted edit distance algorithm. As shown in Fig. 5, different from edit distance, which assign the same cost for different operations, the costs of our proposed weighted edit distance depend on the character probability which yielded by the pixel voting. Mathematically, the weighted edit distance between two strings a and b, whose length are |a| and |b| respectively, can be described as
, where
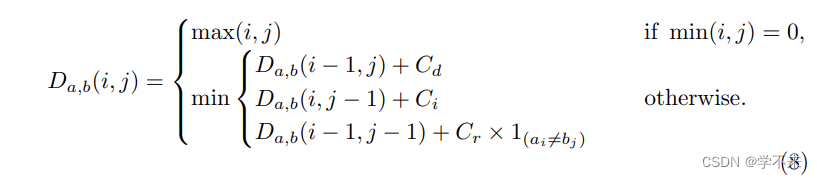
其中, 是指标函数,当ai = bj时等于0,否则等于1;是a的前 i 个字符和b的前 j 个字符之间的距离;Cd、Ci、Cr分别是删除、插入和替换成本。相比之下,这些成本在标准编辑距离中被设置为1。
where is the indicator function equal to 0 when ai = bj and equal to 1 otherwise;
is the distance between the first i characters of a and the first j characters of b; Cd, Ci , and Cr are the deletion, insert, and replace cost respectively. In contrast, these costs are set to 1 in the standard edit distance.
4 Experiments
为了验证所提方法的有效性,我们在三个公共数据集上进行了实验,并与其他最先进的方法进行了比较:水平文本集ICDAR2013[25]、定向文本集ICDAR2015[24]和曲线文本集Total-Text[4]。
To validate the effectiveness of the proposed method, we conduct experiments and compare with other state-of-the-art methods on three public datasets: a horizontal text set ICDAR2013 [25], an oriented text set ICDAR2015 [24] and a curved text set Total-Text [4].

图5:编辑距离和我们提出的加权编辑距离的说明。红色字符是将被删除、插入和替换的字符。绿色字符表示候选字符。 为字符概率,index为字符索引,c为当前字符。
Fig. 5: Illustration of the edit distance and our proposed weighted edit distance. The red characters are the characters will be deleted, inserted and replaced. Green characters mean the candidate characters. is the character probability, index is the character index and c is the current character.
4.1 Datasets
SynthText is a synthetic dataset proposed by [12], including about 800000 images. Most of the text instances in this dataset are multi-oriented and annotated with word and character-level rotated bounding boxes, as well as text sequences.
ICDAR2013 is a dataset proposed in Challenge 2 of the ICDAR 2013 Robust Reading Competition [25] which focuses on the horizontal text detection and recognition in natural images. There are 229 images in the training set and 233 images in the test set. Besides, the bounding box and the transcription are also provided for each word-level and character-level text instance.
ICDAR2015 is proposed in Challenge 4 of the ICDAR 2015 Robust Reading Competition [24]. Compared to ICDAR2013 which focuses on “focused text” in particular scenario, ICDAR2015 is more concerned with the incidental scene text detection and recognition. It contains 1000 training samples and 500 test images. All training images are annotated with word-level quadrangles as well as corresponding transcriptions. Note that, only localization annotations of words are used in our training stage.
Total-Text is a comprehensive scene text dataset proposed by [4]. Except for the horizontal text and oriented text, Total-Text also consists of a lot of curved text. Total-Text contains 1255 training images and 300 test images. All images are annotated with polygons and transcriptions in word-level. Note that, we only use the localization annotations in the training phase.
4.2 Implementation details
Training 与之前使用两个独立模型[22,30](检测器和识别器)或交替训练策略[27]的文本识别方法不同,我们模型的所有子网都可以同步和端到端地训练。整个培训过程包括两个阶段:对SynthText进行预培训和对真实数据进行微调。
Training Different from previous text spotting methods which use two independent models [22, 30] (the detector and the recognizer) or alternating training strategy [27], all subnets of our model can be trained synchronously and end-toend. The whole training process contains two stages: pre-trained on SynthText and fine-tuned on the real-world data.
在预训练阶段,我们将mini batch设置为8,并将输入图像的所有较短边缘调整为800像素,同时保持图像的纵横比。RPN和Fast R-CNN的批量大小设置为每张图像256和512,正片和负片的采样率为1:3。掩码分支的批量大小为16。在微调阶段,由于缺乏真实样本,采用了数据增强和多尺度训练技术。具体来说,为了增强数据,我们在的特定角度范围内随机旋转输入图片。其他一些增强技巧,如随机修改色调、亮度和对比度,也在后面使用[33]。对于多尺度训练,输入图像的短边随机调整为三个尺度(600、800、1000)。此外,在[27]之后,还使用[56]中用于字符检测的额外1162幅图像作为训练样本。小批量图像保持为8,在每个小批量中,SynthText、ICDAR2013、ICDAR2015、Total Text和额外图像的不同数据集的采样率分别设置为4:1:1:1:1。RPN和Fast R-CNN的批量大小保持为预训练阶段,而掩模分支的批量大小在微调时设置为64。
In the pre-training stage, we set the mini-batch to 8, and all the shorter edge of the input images are resized to 800 pixels while keeping the aspect ratio of the images. The batch sizes of RPN and Fast R-CNN are set to 256 and 512 per image with a 1 : 3 sample ratio of positives to negatives. The batch size of the mask branch is 16. In the fine-tuning stage, data augmentation and multi-scale training technology are applied due to the lack of real samples. Specifically, for data augmentation, we randomly rotate the input pictures in a certain angle range of . Some other augmentation tricks, such as modifying the hue, brightness, contrast randomly, are also used following [33]. For multi-scale training, the shorter sides of the input images are randomly resized to three scales (600, 800, 1000). Besides, following [27], extra 1162 images for character detection from [56] are also used as training samples. The mini-batch of images is kept to 8, and in each mini-batch, the sample ratio of different datasets is set to 4 : 1 : 1 : 1 : 1 for SynthText, ICDAR2013, ICDAR2015, Total-Text and the extra images respectively. The batch sizes of RPN and Fast R-CNN are kept as the pre-training stage, and that of the mask branch is set to 64 when fine-tuning.
我们使用SGD优化模型,权重衰减为0.0001,动量为0.9。在预训练阶段,我们训练我们的模型进行170k次迭代,初始学习率为0.005。然后,在120k迭代中,学习速率衰减到十分之一。在微调阶段,初始学习率设置为0.001,然后在40k迭代时降低到0.0001。微调过程在80k迭代时终止。
We optimize our model using SGD with a weight decay of 0.0001 and momentum of 0.9. In the pre-training stage, we train our model for 170k iterations, with an initial learning rate of 0.005. Then the learning rate is decayed to a tenth at the 120k iteration. In the fine-tuning stage, the initial learning rate is set to 0.001, and then be decreased to 0.0001 at the 40k iteration. The fine-tuning process is terminated at the 80k iteration.
Inference 在推理阶段,输入图像的规模取决于不同的数据集。NMS之后,1000份 proposals被输入Fast R-CNN。Fast R-CNN和NMS分别过滤掉假警报和冗余候选框。保留的候选框被输入到mask branch,以生成全局文本实例映射和字符映射。最后,根据预测的地图生成文本实例边界框和序列。
Inference In the inference stage, the scales of the input images depend on different datasets. After NMS, 1000 proposals are fed into Fast R-CNN. False alarms and redundant candidate boxes are filtered out by Fast R-CNN and NMS respectively. The kept candidate boxes are input to the mask branch to generate the global text instance maps and the character maps. Finally, the text instance bounding boxes and sequences are generated from the predicted maps.
我们在Caffe2中实现了我们的方法,并使用Nvidia Titan Xp GPU在常规工作站上进行了所有实验。该模型并行训练,并在单个GPU上进行评估。
We implement our method in Caffe2 and conduct all experiments on a regular workstation with Nvidia Titan Xp GPUs. The model is trained in parallel and evaluated on a single GPU.
4.3 Horizontal text
我们在ICDAR2013数据集上评估了我们的模型,以验证其在检测和识别水平文本方面的有效性。我们将所有输入图像的短边调整为1000,并在线评估结果。表1和表3列出了我们模型的结果,并与其他最先进的方法进行了比较。如图所示,我们的方法在检测、单词定位和端到端识别方面取得了最先进的结果。具体来说,对于检测,虽然在单尺度下进行了评估,但我们的方法优于以前在多尺度设置下评估的一些方法[18,16](F-测量:91.7%vs.90.3%);对于单词识别,我们的方法与之前最好的方法相当;对于端到端识别,尽管[30,27]已经取得了惊人的结果,但我们的方法仍比它们高出1.1%− 1.9%.
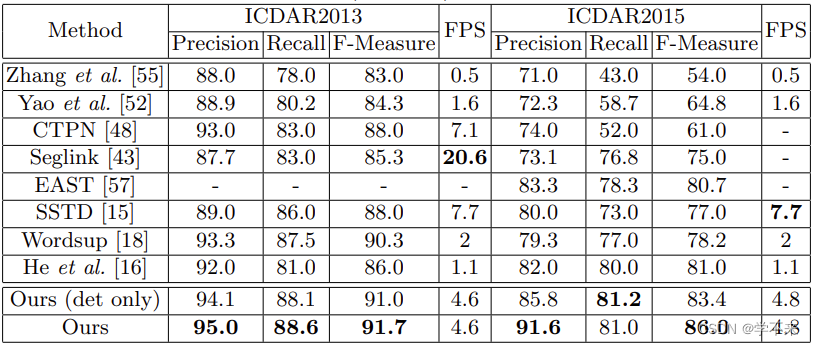
We evaluate our model on ICDAR2013 dataset to verify its effectiveness in detecting and recognizing horizontal text. We resize the shorter sides of all input images to 1000 and evaluate the results on-line. The results of our model are listed and compared with other state-of-the-art methods in Table 1 and Table 3. As shown, our method achieves state-of-the-art results among detection, word spotting and end-to-end recognition. Specifically, for detection, though evaluated at a single scale, our method outperforms some previous methods which are evaluated at multi-scale setting [18, 16] (F-Measure: 91.7% v.s. 90.3%); for word spotting, our method is comparable to the previous best method; for end-to-end recognition, despite amazing results have been achieved by [30, 27], our method is still beyond them by 1.1% − 1.9%.
4.4 Oriented text
通过在ICDAR2015上的实验,验证了该方法在面向文本检测和识别中的优越性。我们以三种不同的比例输入图像:原始比例(720×1280)和两个更大的比例,其中输入图像的短边为1000和1600,这是因为ICDAR2015中有很多小文本实例。我们在线评估了我们的方法,并将其与表2和表3中的其他方法进行了比较。我们的方法在检测和识别方面都大大优于以前的方法。对于检测,当在原始尺度下进行评估时,我们的方法实现了84%的F-度量,比在多个尺度下评估的当前最佳方法[16]高出3.0%。当在更大范围内进行评估时,可以获得更令人印象深刻的结果(F-Measure:86.0%),比竞争对手至少高出5.0%。此外,我们的方法在单词识别和端到端识别方面也取得了显著的效果。与最新技术相比,我们的方法的性能显著提高了13.2%− 25.3%,适用于所有评估情况。
We verify the superiority of our method in detecting and recognizing oriented text by conducting experiments on ICDAR2015. We input the images with three different scales: the original scale (720×1280) and two larger scales where shorter sides of the input images are 1000 and 1600 due to a lot of small text instance in ICDAR2015. We evaluate our method on-line and compare it with other methods in Table 2 and Table 3. Our method outperforms the previous methods by a large margin both in detection and recognition. For detection, when evaluated at the original scale, our method achieves the F-Measure of 84%, higher than the current best one [16] by 3.0%, which evaluated at multiple scales. When evaluated at a larger scale, a more impressive result can be achieved (F-Measure: 86.0%), outperforming the competitors by at least 5.0%. Besides, our method also achieves remarkable results on word spotting and end-to-end recognition. Compared with the state of the art, the performance of our method has significant improvements by 13.2% − 25.3%, for all evaluation situations.
表1:ICDAR2013的结果。“S”、“W”和“G”分别表示对强、弱和类属词汇的识别。
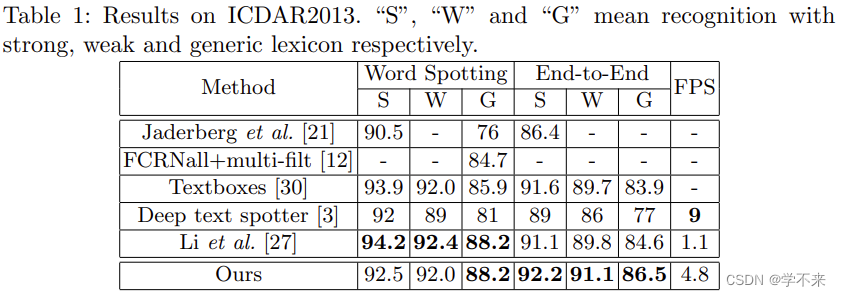
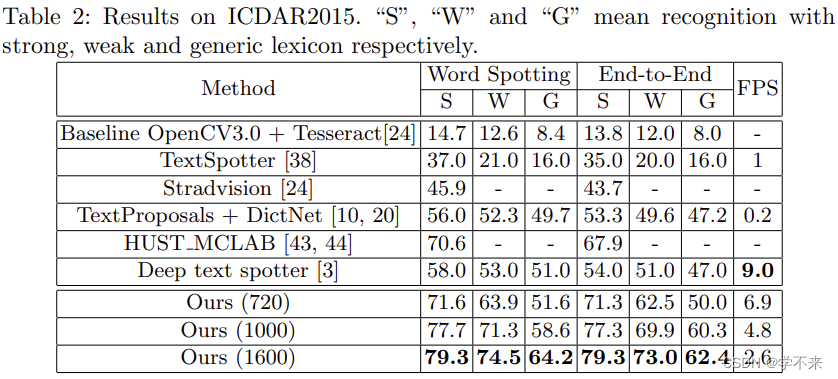

图6:ICDAR 2013(左)、ICDAR 2015(中)和总文本(右)的可视化结果。
表3:ICDAR2013和ICDAR2015的检测结果。对于ICDAR2013,所有方法都按照“DetEval评估协议”进行评估。“Ours(仅det)”和“Ours”中输入图像的短边设置为1000。
4.5 Curved text
检测和识别任意文本(如曲线文本)是我们的方法优于其他方法的巨大优势。我们对整个文本进行了实验,以验证我们的方法在检测和识别曲线文本方面的鲁棒性。同样,我们输入的测试图像的短边大小调整为1000。检测的评估协议由[4]提供。端到端识别的评估协议遵循ICDAR 2015,同时将多边形的表示从四个顶点更改为任意数量的顶点,以便处理任意形状的多边形。
Detecting and recognizing arbitrary text (e.g. curved text) is a huge superiority of our method beyond other methods. We conduct experiments on Total-Text to verify the robustness of our method in detecting and recognizing curved text. Similarly, we input the test images with the short edges resized to 1000. The evaluation protocol of detection is provided by [4]. The evaluation protocol of end-to-end recognition follows ICDAR 2015 while changing the representation of polygons from four vertexes to an arbitrary number of vertexes in order to handle the polygons of arbitrary shapes.
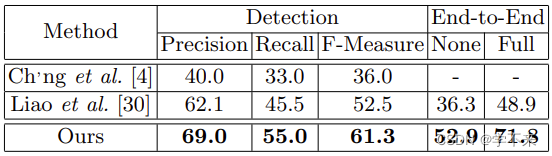
为了与其他方法进行比较,我们还使用[30]3中的代码使用相同的训练数据训练了一个模型[30]。如图7所示,我们的方法在检测和识别曲线文本方面都有很大的优势。表4中的结果表明,我们的方法在检测方面超过[30]8.8个点,在端到端识别方面至少超过16.6%。检测的显著改进主要来自更精确的定位输出,它用多边形而不是水平矩形包围文本区域。此外,我们的方法更适合处理二维空间(如曲线)中的序列,而[30,27,3]中使用的序列识别网络是针对一维序列设计的。
To compare with other methods, we also trained a model [30] using the code in [30] 3 with the same training data. As shown in Fig. 7, our method has a large superiority on both detection and recognition for curved text. The results in Table 4 show that our method exceeds [30] by 8.8 points in detection and at least 16.6% in end-to-end recognition. The significant improvements of detection mainly come from the more accurate localization outputs which encircle the text regions with polygons rather than the horizontal rectangles. Besides, our method is more suitable to handle sequences in 2-D space (such as curves), while the sequence recognition network used in [30, 27, 3] are designed for 1-D sequences.

图7:没有词汇的文本总量的定性比较。顶部:文本框的结果[30];底部:我们的结果。
表4:全部文本的结果。“无”意味着没有任何词汇的认可。“完整”词典包含测试集中的所有单词。
4.6 Speed
与以前的方法相比,我们提出的方法具有良好的速度精度折衷。它可以以每秒6.9帧的速度运行,输入刻度为720×1280。虽然比最快的方法[3]慢了一点,但它在精确度上大大超过了[3]。此外,我们的速度大约是[27]的4.4倍,这是ICDAR2013上目前最先进的速度。
Compared to previous methods, our proposed method exhibits a good speedaccuracy trade-off. It can run at 6.9 FPS with the input scale of 720 × 1280. Although a bit slower than the fastest method [3], it exceeds [3] by a large margin in accuracy. Moreover, the speed of ours is about 4.4 times of [27] which is the current state-of-the-art on ICDAR2013.
4.7 Ablation Experiments
Some ablation experiments, including “With or without character maps”, “With or without character annotation”, and “With or without weighted edit distance”, are discussed in the Supplementary.
补充部分讨论了一些烧蚀实验,包括“有或没有字符映射”、“有或没有字符注释”和“有或没有加权编辑距离”。
5 Conclusion
In this paper, we propose a text spotter, which detects and recognizes scene text in a unified network and can be trained end-to-end completely. Comparing with previous methods, our proposed network is very easy to train and has the ability to detect and recognize irregular text (e.g. curved text). The impressive performances on all the datasets which includes horizontal text, oriented text and curved text, demonstrate the effectiveness and robustness of our method for text detection and end-to-end text recognition.
在本文中,我们提出了一种文本检测器,它在一个统一的网络中检测和识别场景文本,并且可以完全端到端地进行训练。与以前的方法相比,我们提出的网络非常容易训练,并且具有检测和识别不规则文本(例如曲线文本)的能力。在所有数据集(包括水平文本、定向文本和曲线文本)上令人印象深刻的性能证明了我们的文本检测和端到端文本识别方法的有效性和鲁棒性。
这篇关于Mask TextSpotter: An End-to-End TrainableNeural Network for Spotting Text withArbitrary Shapes 中英对翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!