本文主要是介绍求助!使用HEG预处理导入MODIS L1B数据出现error(已破案),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(学习使用GIS工具第一天的心路历程)↓
一开始看的教程下的是MRT来处理,下好以后看到有人说L1B的数据只能用MRT Swath Tool处理,我又马不停蹄去找这个下载,但是哪也找不到,到官网看到这俩工具已经被他们用HEG 取代了,我就寻思那HEG肯定能行了吧,结果下载半天,不是给他安排的路径他不满意就是他闪退,好不容易都解决了,它还不认我从LAADS DAAC下的HDF文件,有没有哪个心软的神能救救我🙏🙏🙏
—————————————————求助的问题(已破案)————————————————
需要对MODIS L1B 1KM的数据进行波段提取、重投影和拼接
发现打开HEG导入下好的HDF文件的时候他死活不识别,同时显示如下错误。说不是HEG支持的文件?有没有大神知道是为啥,要怎么解决写🙏🙏🙏?
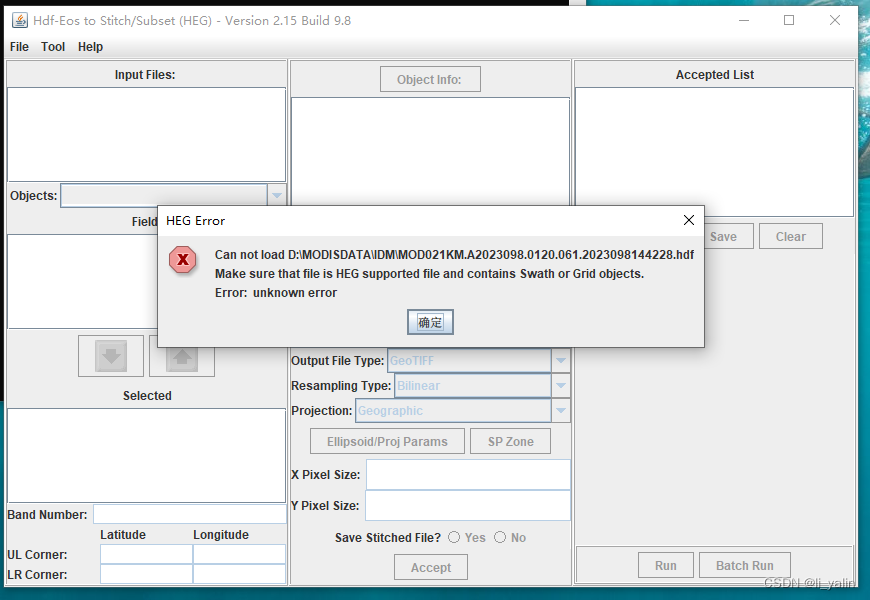
————————————————————破案了————————————————————
今天苦思冥想不知道从哪开始排查起的时候,突然想起来安装HEG的时候各种路径出错,前前后后安装了还几次才能打开他的页面。
我就想,不能说是我安装的时候哪个路径没搞对吧?我就把HEG卸了重装。
接着又去install.bat重新开始输各种路径,这次很小心,命令窗口里的话也认认真真的仔细读了一遍,直到我看见,输完Java bin的路径以后,他说的是“Java.exe没有找到”!前几次安装的时候都没有看下面的文字,只要能转到下一步我都以为没事!而实际上,在输java路径这一步上就已经在报错了。
所以我直接就是重新装java,重新配置环境变量。
重新配置java的环境变量的时候,我才发现有个path被我漏改了,还是最开始的C:/Progrem File....的,这个是有空格的!!欣喜若狂的删了,再接着点install.bat,果然这次输完java bin的路径以后显示的“找到Java.exe”
今日教训:
1、安装软件的过程中还是要多看看文字描述和引导的
2、安这个软件的时候最好手动输入路径,之前复制粘贴的路径出来的文件名非常喜欢乱码
——————————————————还未解决的疑问——————————————————
而且我还发现在nasa下载数据那个订单页面,有一个post-processing parameters可以选,里面包括波段提取、重投影、拼接、裁剪什么的,好像是下单后可以直接下处理好的数据,
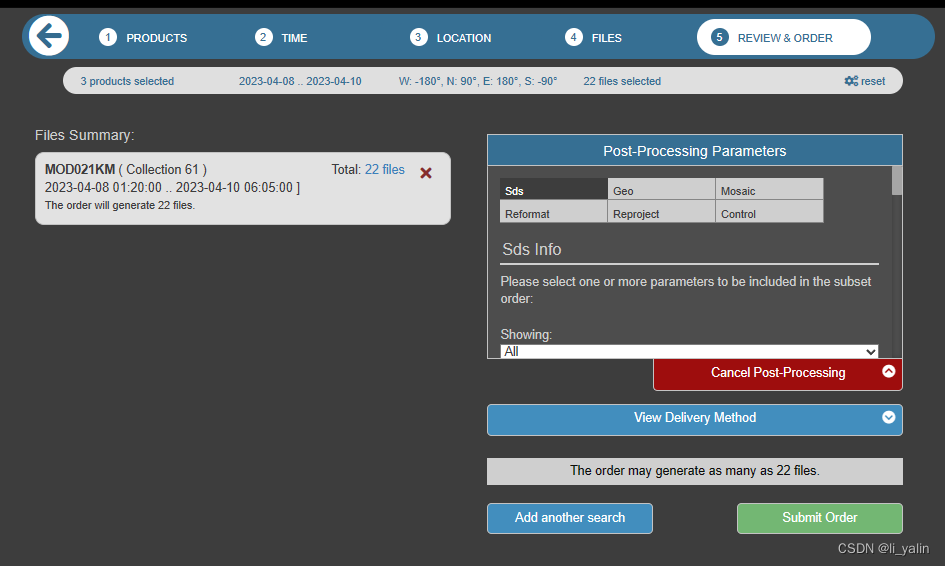
但是我昨天下单好了一个就一直在waiting,今天一看失败了(FAIL:post - processing)有大佬知道是为啥么?

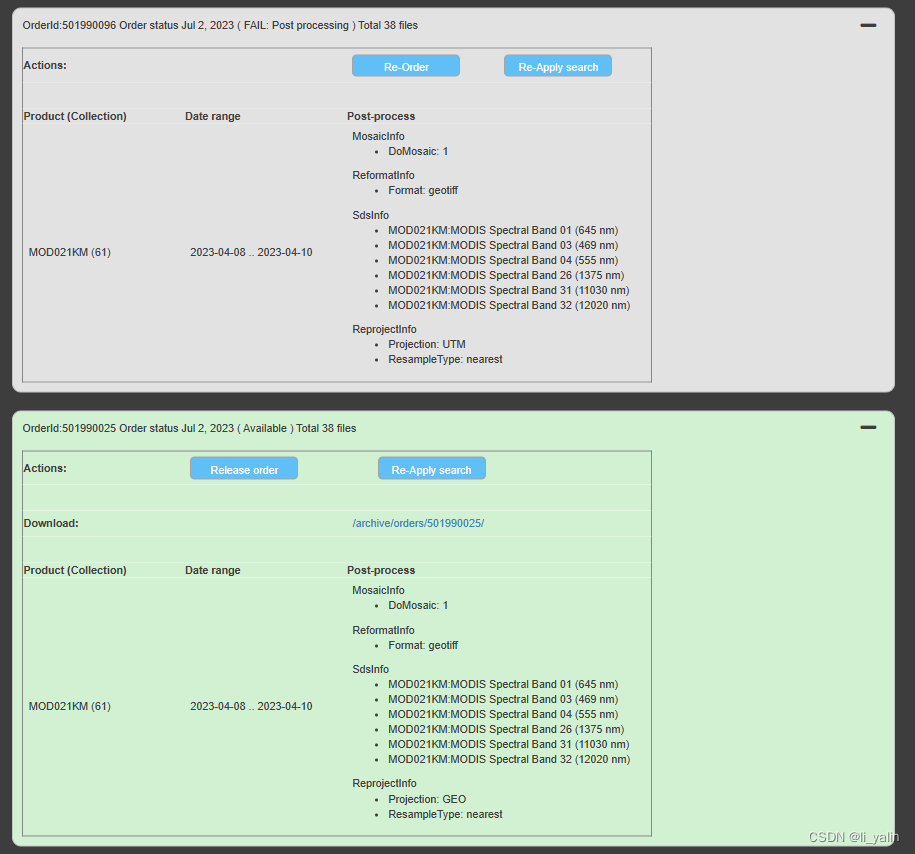
———————————————————第二次尝试——————————————————
今天又试了一下,定了两个除了重投影其他都一样的账单,一个重投影到UTM一个GEO,今天一看GEO成功了UTM还是失败,依然找不到原因......但是好在好像ENVI里可以重投影?
这篇关于求助!使用HEG预处理导入MODIS L1B数据出现error(已破案)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



