本文主要是介绍Jupyter地铁数据分析预测地铁后7天小时客流量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
地铁数据分析预测地铁后7天小时客流量
基于八月地铁刷卡数据,以前23天的数据作为训练数据,预测后7天各个地铁站点在6点—23点每个小时的客流量。
import pandas as pd
import time
import numpy as np
import matplotlib.pyplot as plt使用二分法目的,找到每天的最后一刻 数据的索引
def find_day_index(A,a0,a2):tA=Awhile True:I1=int(len(tA)/2)-1I2=I1+1
# 获取I1和I2的日期t0=int(tA.iloc[I1,0][8:10])t2=int(tA.iloc[I2,0][8:10])if t2!=t0:r=(tA.iloc[I1,0],tA.index[I1])return rbreakif t2==t0 and t2==a0: tA=tA.iloc[I2:,:]if t2==t0 and t2==a2:tA=tA.iloc[:I1+1,:]reader = pd.read_csv('#数据.csv',usecols=[6],chunksize=100000)
start = time.perf_counter() #计算耗费时间
# 读取站台信息
A = pd.read_csv('acc_08_final.csv',usecols=[5],nrows=1000)
S = pd.Series(A.iloc[:,0].values)
Ad = S.unique()# 站台信息去重R_day = [('', -1)]# 存储每天的截止时间下标
for A in reader:a0 = int(A.iloc[0,0][8:10])a2 = int(A.iloc[len(A)-1,0][8:10])if a0 !=a2:r = find_day_index(A,a0,a2)R_day.append(r)end = time.perf_counter()
print("耗时: ",end-start)#耗时:27.6368365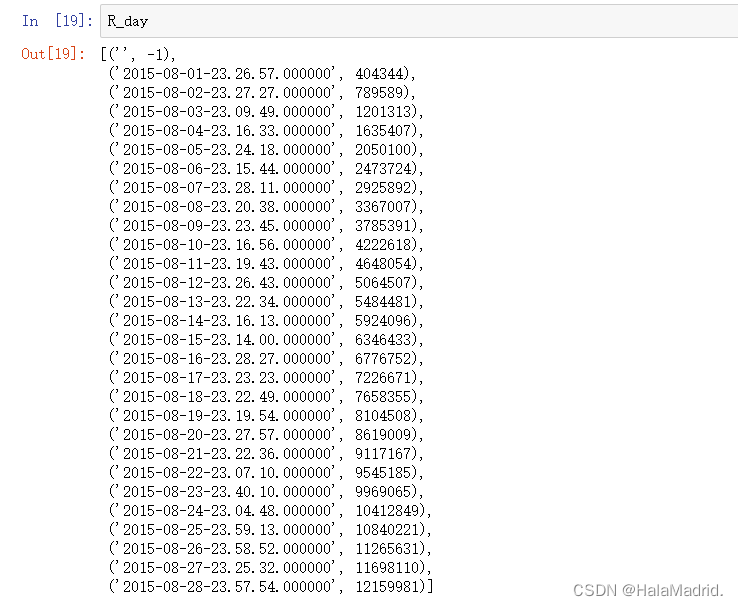
date_all = pd.read_csv('#数据.csv',sep=',',usecols=[6])
R_hour = []
for day in range(len(R_day)-1):left = R_day[day][1] + 1# 每天起始坐标right = R_day[day+1][1] + 1# 每天结束坐标的下一位
# print(left, right)print(time.perf_counter())for idx in range(left, right):
# print(idx, idx+1)if idx==right-1:R_hour.append((date_all.iloc[idx,0],idx))elif date_all.iloc[idx,0][11:13]!= date_all.iloc[idx+1,0][11:13]:R_hour.append((date_all.iloc[idx,0],idx)) 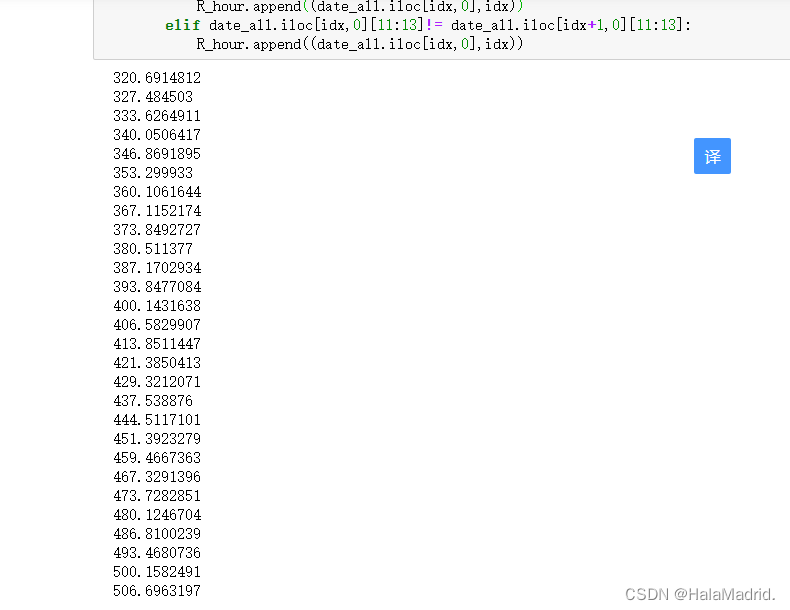

start = time.perf_counter()
A=pd.read_csv('acc_08_final.csv',sep=',',usecols=[4,5]) #指定列交易类型和站点
A=A.values
Ad_values=[] #站点
day_values=[] #日期
C1_values=[] #进站数
C2_values=[] #出站数
C_values=[]
for Z in range(len(Ad)): ##站点循坏for t in range(len(R_hour)): ##时间循环if t==0:data=A[:R_hour[t][1]+1,:]I1=data[:,1]==Ad[Z] #站点I2=data[:,0]==21 #进站还是出站I3=data[:,0]==22
# 指定站点 进站的数量C1_values.append(len(data[I1&I2,:]))
# 指定站点 出站的数量C2_values.append(len(data[I1&I3,:]))day_values.append(R_hour[t][0])
# 指定站点Ad_values.append(Ad[Z])if t>0 and t<len(R_hour):data=A[R_hour[t-1][1]+1:R_hour[t][1]+1,:]I1=data[:,1]==Ad[Z]I2=data[:,0]==21I3=data[:,0]==22C1_values.append(len(data[I1&I2,:]))C2_values.append(len(data[I1&I3,:]))day_values.append(R_hour[t][0])Ad_values.append(Ad[Z])
# 计算总客流量
for i in range(0,len(C1_values)):summm=C1_values[i]+C2_values[i]C_values.append(summm)
#print(C_values)
D={'Ad':Ad_values,'day':day_values,'C1':C1_values,'C2':C2_values,
'C':C_values}
Data=pd.DataFrame(D)
end = time.perf_counter()
print("耗时: ",end-start)
Data.to_excel('前23天每小时地铁客流量数据.xlsx',index=False)#耗时:33.0005056data = pd.read_excel('前23天每小时地铁客流量数据.xlsx')
data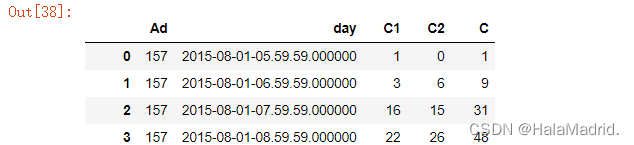

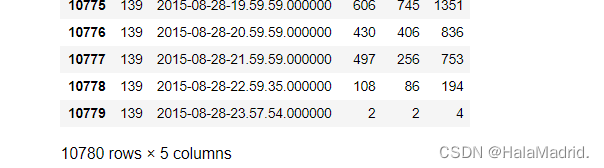
Day = data['day'].apply(lambda s:int(s[8:10]))
Hour = data['day'].apply(lambda s:int(s[11:13]))
x1 = Day[Day<=23] # 前23天
x2 = Day[Day>23] # 后7天
x_Hour = Hour[Hour>=6] # 时间段6.00-23.59
data1 = pd.concat([data,x1,x_Hour],axis=1)
data2 = pd.concat([data,x2,x_Hour],axis=1)data1.dropna(inplace=True)#删除后7天的数据
data2.dropna(inplace=True)#删除前23天的数据data1.to_excel('8月前23天时间6-23点的数据.xlsx',index=False) # 前23天数据
data2.to_excel('8月后7天时间6-23点的数据.xlsx',index=False) # 后7天数据#重置列名
cols = ["Ad","Date","C1","C2","C","Day","Hour"]
data1.columns = cols
data2.columns = cols
data2.head() 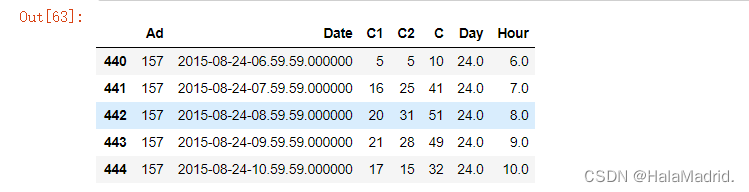
x_test,y_test = data1.iloc[:,[0,2,3,5,6]], data1['C']
x_train,y_train = data2.iloc[:,[0,2,3,5,6]], data2['C']from sklearn.neural_network import MLPRegressor
clf=MLPRegressor(solver='lbfgs',alpha=1e-5,hidden_layer_sizes=8,random_state=1)
clf.fit(x_test,y_test)
rv=clf.score(x_test,y_test)
print(rv)
#0.9999y_pred = clf.predict(x_train)
y_pred.shape
#(1800,)from sklearn.metrics import mean_squared_error
print("均方误差:",mean_squared_error(y_train.values, y_pred))
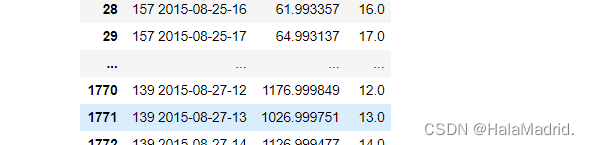
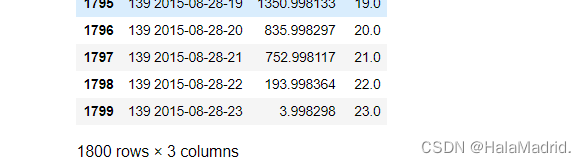
#均方误差:0.00058232data2["info"] = list(map(lambda x,y:str(x)+" "+y[0:13],data2["Ad"],data2["Date"]))
data2


data2["target"] = y_predans = data2.iloc[:,7:]
ans["Hour"] = data2["Hour"]
ans = ans.reset_index(drop=True)
ans 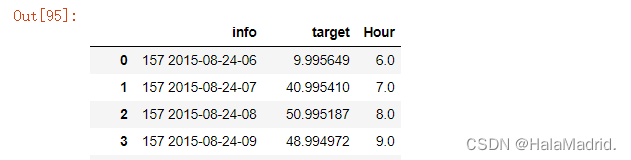
over
这篇关于Jupyter地铁数据分析预测地铁后7天小时客流量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








