本文主要是介绍Hadoop3数据容错技术(纠删码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注公众号:大数据技术派,回复“资料”,领取资料,学习大数据技术。
背景
随着大数据技术的发展,HDFS作为Hadoop的核心模块之一得到了广泛的应用。为了数据的可靠性,HDFS通过多副本机制来保证。在HDFS中的每一份数据都有两个副本,1TB的原始数据需要占用3TB的磁盘空间,存储利用率只有1/3。而且系统中大部分是使用频率非常低的冷数据,却和热数据一样存储3个副本,给存储空间和网络带宽带来了很大的压力。因此,在保证可靠性的前提下如何提高存储利用率已成为当前HDFS面对的主要问题之一。Hadoop 3.0 引入了纠删码技术(Erasure Coding),它可以提高50%以上的存储利用率,并且保证数据的可靠性。纠删码技术(Erasure coding)简称EC,是一种编码容错技术。最早用于通信行业,数据传输中的数据恢复。它通过对数据进行分块,然后计算出校验数据,使得各个部分的数据产生关联性。当一部分数据块丢失时,可以通过剩余的数据块和校验块计算出丢失的数据块。
原理
Reed-Solomon(RS)码是存储系统较为常用的一种纠删码,它有两个参数k和m,记为RS(k,m)。如下图所示,k个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT从而得到一个码字(codeword)向量,该向量由k个数据块和m个校验块构成。如果一个数据块丢失,可以用(GT)-1乘以码字向量来恢复出丢失的数据块。RS(k,m)最多可容忍m个块(包括数据块和校验块)丢失。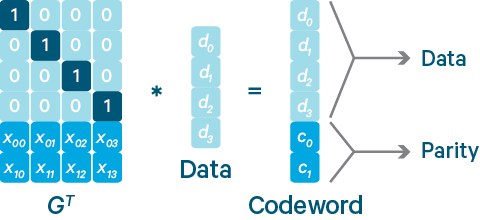 比如:我们有 7、8、9 三个原始数据,通过矩阵乘法,计算出来两个校验数据 50、122。这时原始数据加上校验数据,一共五个数据:7、8、9、50、122,可以任意丢两个,然后通过算法进行恢复。
比如:我们有 7、8、9 三个原始数据,通过矩阵乘法,计算出来两个校验数据 50、122。这时原始数据加上校验数据,一共五个数据:7、8、9、50、122,可以任意丢两个,然后通过算法进行恢复。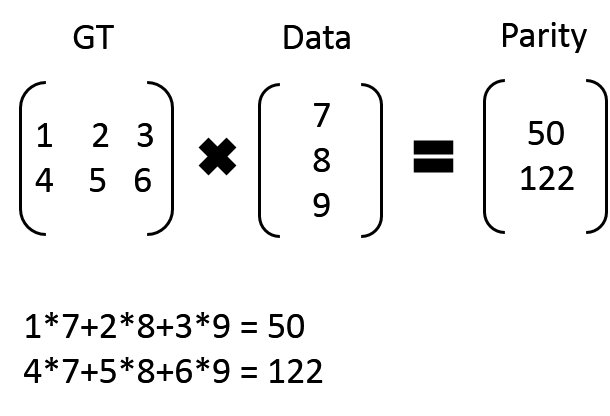
7 x
50 y
x + 2*8 + 3 * 9 = y
4x + 5*8 + 6 * 9 = 122
HDFS EC 方案
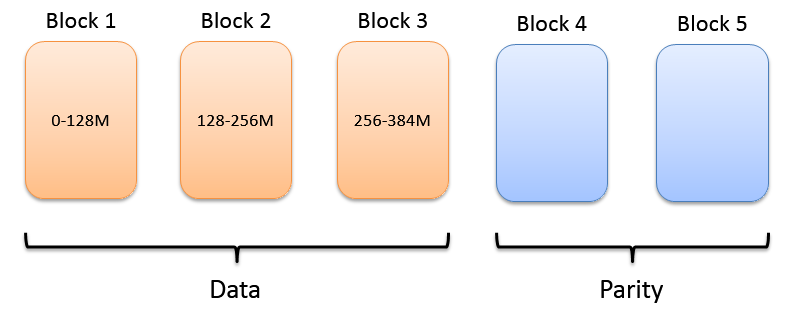
传统模式下HDFS中文件的基本构成单位是block,而EC模式下文件的基本构成单位是block group。以RS(3,2)为例,每个block group包含3个数据块,2个校验块。
连续布局(Contiguous Layout)
文件数据被依次写入块中,一个块写满之后再写入下一个块,这种分布方式称为连续布局。优点:
容易实现
方便和多副本存储策略进行转换
缺点:
需要客户端缓存足够的数据块
不适合存储小文件
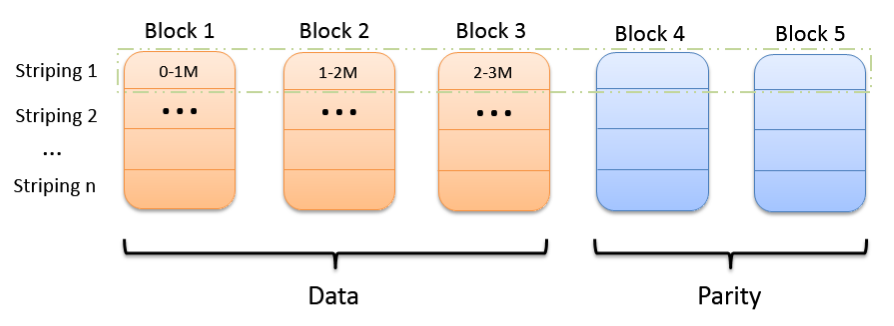
条形布局(Striping Layout)
条(stripe)是由若干个相同大小的单元(cell)构成的序列。文件数据被依次写入条的各个单元中,当一个条写满之后再写入下一个条,一个条的不同单元位于不同的数据块中。这种分布方式称为条形布局。优点:
客户端缓存数据较少
无论文件大小都适用
缺点:
会影响一些位置敏感任务的性能,因为原先在一个节点上的块被分散到了多个不同的节点上
和多副本存储策略转换比较麻烦
HDFS EC 开发计划
整个HDFS EC项目主要分为两个阶段:1、用户可以读和写一个条形布局(Striping Layout)的文件;如果该文件的一个块丢失,后台能够检查出并恢复;如果在读的过程中发现数据丢失,能够立即解码出丢失的数据从而不影响读操作。2、支持将一个多副本模式(HDFS原有模式)的文件转换成连续布局(Contiguous Layout),以及从连续布局转换成多副本模式。第一阶段 HDFS-7285 已经实现,第二阶段 HDFS-8030 正在进行中。
纠删码策略
RS-10-4-1024k:使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576。RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576。RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576。RS-LEGACY-6-3-1024k:策略和上面的RS-6-3-1024k一样,只是编码的算法用的是rs-legacy,应该是之前遗留的rs算法。XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数=2),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576。
以RS-6-3-1024k为例,6个数据单元+3个校验单元,可以容忍任意的3个单元丢失,冗余的数据是50%。而采用副本方式,3个副本,冗余200%,却还不能容忍任意的3个单元丢失。因此,RS编码在相同冗余度的情况下,会大大提升数据的可用性,而在相同可用性的情况下,会大大节省冗余空间。
纠删码基本操作
查看当前支持的纠删码策略命令如下:
[user@nn1 ~]$ hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5, State=DISABLED]
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2, State=DISABLED]
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1, State=DISABLED]
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3, State=DISABLED]
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4, State=DISABLED]
设置纠删码策略
纠删码策略是与具体的路径(path)相关联的。也就是说,如果我们要使用纠删码,则要给一个具体的路径设置纠删码策略,后续,所有往此目录下存储的文件,都会执行此策略。例子如下 首先在/下创建目录rs-6-3,然后查看其是否设置了纠删码策略,结果显示没有指定策略(新建的目录不会指定策略)
hdfs://bigdata/dn1/path
hdfs://bigdata/dn1/path2
[user@nn1 ~]$ hdfs dfs -mkdir /rs-6-3
[user@nn1 ~]$ hdfs ec -getPolicy -path /rs-6-3
The erasure coding policy of /rs-6-3 is unspecified
接下来,给此目录设置纠删码策略RS-6-3-1024k,此策略名是从前面list策略中查到的。可以看到已经设置成功。
[user[@nn1 ](/nn1 ) ~]$ hdfs ec -setPolicy -path /rs-6-3 -policy RS-6-3-1024k
Set erasure coding policy RS-6-3-1024k on /rs-6-3
注意:RS-6-3-1024k可以直接设置成功,其它的策略需要enable后,才能设置:设置RS-3-2-1024k,这个需要先enablePolicy
[user[@nn1 ](/nn1 ) hadoop-3.0.0-beta1]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled
[user[@nn1 ](/nn1 ) hadoop-3.0.0-beta1]$ hdfs ec -setPolicy -path /rs-3-2 -policy RS-3-2-1024k
Set erasure coding policy RS-3-2-1024k on /rs-3-2
验证
[user[@nn1 ](/nn1 ) hadoop-3.0.0-beta1]$ hdfs ec -getPolicy -path /rs-3-2
RS-3-2-1024k
设置RS-10-4-1024k,如果不enablePolicy,会报错
[user[@nn1 ](/nn1 ) hadoop-3.0.0-beta1]$ hdfs dfs -mkdir /rs-10-4
[user[@nn1 ](/nn1 ) hadoop-3.0.0-beta1]$ hdfs ec -setPolicy -path /rs-10-4 -policy RS-10-4-1024k
报错了 RemoteException: Policy 'RS-10-4-1024k' does not match any enabled erasure coding policies: [RS-3-2-1024k, RS-6-3-1024k]. An erasure coding policy can be enabled by enableErasureCodingPolicy API.
上传文件,查看文件编码情况
下面我们上传一个文件看一下,这里提示我们没有使用ISA-L支持的编码器(这个编码器和CPU优化相结合,效率更高,需要重新编译和配置,我们后续再讲)
[user@nn1 ~]$ hdfs dfs -cp /profile /rs-6-3/
2017-11-30 10:24:29,620 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
查看profile编码后的分布
[user@nn1 ~]$ hdfs fsck /rs-6-3/profile -files -blocks -locations
输出
Connecting to namenode via http://nn1:9870/fsck?ugi=user&files=1&blocks=1&locations=1&path=%2Frs-6-3%2Fprofile
FSCK started by user (auth:SIMPLE) from /192.168.182.11 for path /rs-6-3/profile at Thu Nov 30 10:57:12 EST 2017
/rs-6-3/profile 1872 bytes, erasure-coded: policy=RS-6-3-1024k, 1 block(s): OK
0. BP-529485104-192.168.182.11-1511810134643:blk_-9223372036854775792_1065 len=1872 Live_repl=4 [blk_-9223372036854775792:DatanodeInfoWithStorage[192.168.182.11:9866,DS-da58ee3e-adcc-4f6c-8488-c2a0b742d8b9,DISK], blk_-9223372036854775786:DatanodeInfoWithStorage[192.168.182.20:9866,DS-c36de658-0f5a-42de-8898-eab3b04c7016,DISK], blk_-9223372036854775785:DatanodeInfoWithStorage[192.168.182.14:9866,DS-a3569982-de52-42b5-8543-94578f8b452a,DISK], blk_-9223372036854775784:DatanodeInfoWithStorage[192.168.182.19:9866,DS-71be9468-c0c7-437c-8b59-ece27593b4c2,DISK]]
查看block文件的信息,可以看到nn1上block的大小正好是1872。这是因为1872<1024k,因此无法分割,直接整体编码。
[user@nn1 ~]$ ls dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775792 -l
-rw-rw-r--. 1 user user 1872 Nov 30 10:24 dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775792
Live_repl=4的解释,表示此文件共有4个副本,其中1个是原始数据,3个是校验数据,因此,这里的策略是rs_6_3,要保证冗余3个校验单元,原始数据1872<1024k,只能构成1个数据单元,再加上3个校验单元,就是4个副本了。1 block(s)的解释:blocks是指数据单元在datanode的存储而言,1872<1024k,只有1个数据单元,因此只能分配到1个datanode,对于每个datanode,其block默认大小是256MB(hdfs3.0是256MB,hdfs2.x是128MB),1872远小于256MB,当然只有1个block了,如果单个datanode上多个数据单元之和>256MB,这时才会生成新的block。再看一个
hdfs dfs -cp file:///home/user/jdk1.8.0_152/lib/ant-javafx.jar /rs-6-3/
此文件的大小是1224175>1024k,但是<2*1024k,也就是可以构成2个数据单元,加上3个校验单元,推测最终编码出来一共是5个副本。查看下
[user@nn1 ~]$ hdfs fsck /rs-6-3/ant-javafx.jar -files -blocks -locations
果然是
/rs-6-3/ant-javafx.jar 1224175 bytes, erasure-coded: policy=RS-6-3-1024k, 1 block(s): OK
0. BP-529485104-192.168.182.11-1511810134643:blk_-9223372036854775776_1066 len=1224175 Live_repl=5 [blk_-9223372036854775776:DatanodeInfoWithStorage[192.168.182.11:9866,DS-da58ee3e-adcc-4f6c-8488-c2a0b742d8b9,DISK], blk_-9223372036854775775:DatanodeInfoWithStorage[192.168.182.18:9866,DS-2dc5d603-ad42-4558-bfda-c9a597f88f06,DISK], blk_-9223372036854775770:DatanodeInfoWithStorage[192.168.182.14:9866,DS-a3569982-de52-42b5-8543-94578f8b452a,DISK], blk_-9223372036854775769:DatanodeInfoWithStorage[192.168.182.20:9866,DS-c36de658-0f5a-42de-8898-eab3b04c7016,DISK], blk_-9223372036854775768:DatanodeInfoWithStorage[192.168.182.13:9866,DS-118ae8da-f820-447c-9d97-dbe4f33bff39,DISK]]
查看第一个block的大小(nn1),可以看到正好是按照1024k来切分的
[user@nn1 ~]$ ls dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775776 -l
-rw-rw-r--. 1 user user 1048576 Nov 30 10:30 dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775776
查看第二个block的大小(nn7),其大小是175599
[user@dn7 ~]$ ls dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775775 -l
-rw-rw-r--. 1 user user 175599 Nov 30 11:54 dfs/share/datanode/current/BP-529485104-192.168.182.11-1511810134643/current/finalized/subdir0/subdir0/blk_-9223372036854775775
第一个block 1048576 + 第二个block 175599 = 1224175,正好是ant-javafx.jar的大小。为什么第二个block没有补齐1024k呢?因为补齐的话,也是填0,没有必要。第三个block~第五个block是校验数据。
数据恢复验证(datanode dead的时间间隔是10m)
我们以ant-javafx.jar为例,它有5个副本,分布在:
192.168.182.11
192.168.182.18
192.168.182.14
192.168.182.20
192.168.182.13
其中2个原始数据单元、3个校验数据单元,意味着可以容忍任意3个数据单元的丢失。下面,我们关闭后3个节点上的datanode
192.168.182.14
192.168.182.20
192.168.182.13
然后从/rs-6-3目录中复制ant-javafx.jar到本地/tmp目录,并和本地的ant-javafx.jar比较,正确,说明数据没有问题。
[user@nn1 ~]$ hdfs dfs -cp /rs-6-3/ant-javafx.jar file:///tmp/
2017-11-30 13:12:36,493 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
[user@nn1 ~]$ diff jdk1.8.0_152/lib/ant-javafx.jar /tmp/ant-javafx.jar
再关掉一个节点,在下面的节点
192.168.182.18
运行
[user@dn7 ~]$ hdfs --daemon stop datanode
在nn1上再次复制 报错,因为丢失的数据单元个数>3了
cp: 4 missing blocks, the stripe is: Offset=0, length=175599, fetchedChunksNum=0, missingChunksNum=4
在dn3上启动datanode,再次复制 发现还是报错,说192.168.182.18上数据丢失,这是为什么呢?查看HDFS状态,发现刚才关闭的dn3 dn9 dn2 dn7仍然是live的,这是因为datanode的状态有一个刷新的间隔,这个间隔默认是10m(600s),只有10m没有收到datanode的消息,namenode才认为此datanode是dead的。因此,等待10m后,可以看到HDFS的live nodes变成了7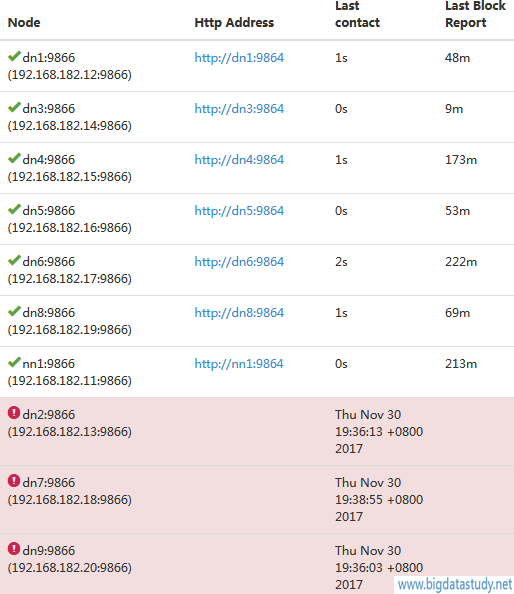 这个时候,再次复制,DFSClient就知道dn7是dead,就不会再选择dn7了,转而选择其它的live节点,因此复制成功。
这个时候,再次复制,DFSClient就知道dn7是dead,就不会再选择dn7了,转而选择其它的live节点,因此复制成功。
[user@nn1 ~]$ hdfs dfs -cp /rs-6-3/ant-javafx.jar file:///tmp/
2017-11-30 13:26:35,241 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
cp: `file:///tmp/ant-javafx.jar': File exists
将dn2、dn7、dn9恢复,启动datanode,再次查看
[user@nn1 ~]$ hdfs fsck /rs-6-3/ant-javafx.jar -files -blocks -locations
Connecting to namenode via http://nn1:9870/fsck?ugi=user&files=1&blocks=1&locations=1&path=%2Frs-6-3%2Fant-javafx.jar
FSCK started by user (auth:SIMPLE) from /192.168.182.11 for path /rs-6-3/ant-javafx.jar at Thu Nov 30 13:29:30 EST 2017
/rs-6-3/ant-javafx.jar 1224175 bytes, erasure-coded: policy=RS-6-3-1024k, 1 block(s): OK
0. BP-529485104-192.168.182.11-1511810134643:blk_-9223372036854775776_1066 len=1224175 Live_repl=5 [blk_-9223372036854775776:DatanodeInfoWithStorage[192.168.182.11:9866,DS-da58ee3e-adcc-4f6c-8488-c2a0b742d8b9,DISK], blk_-9223372036854775770:DatanodeInfoWithStorage[192.168.182.14:9866,DS-a3569982-de52-42b5-8543-94578f8b452a,DISK], blk_-9223372036854775769:DatanodeInfoWithStorage[192.168.182.19:9866,DS-71be9468-c0c7-437c-8b59-ece27593b4c2,DISK], blk_-9223372036854775768:DatanodeInfoWithStorage[192.168.182.16:9866,DS-c32fdd4e-aa34-4b65-b192-643ade06d71b,DISK], blk_-9223372036854775775:DatanodeInfoWithStorage[192.168.182.18:9866,DS-2dc5d603-ad42-4558-bfda-c9a597f88f06,DISK]]
发现数据单元的分布发生了变化
192.168.182.11
192.168.182.14
192.168.182.19
192.168.182.16
192.168.182.18
其中绿色部分,应该是在这些节点关闭后,hdfs重新启动译码和编码,将原来丢失的数据补到了dn8和dn5上。而dn8没有去掉,可能是还没来得及。总之,如果编码后的stripe中,有数据丢失,hdfs会自动启动恢复工作。
猜你喜欢
SparkStreaming实时计算pv和uv
Flink状态管理与状态一致性(长文)
Flink实时计算topN热榜
数仓建模分层理论
数仓建模方法论
大数据组件重点学习这几个
这篇关于Hadoop3数据容错技术(纠删码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






