容错专题

Executor 端长时容错详解
福利部分: 《大数据成神之路》大纲 大数据成神之路 《几百TJava和大数据资源下载》 资源下载 本系列内容适用范围:* 2018.11.02 update, Spark 2.4 全系列 √ (已发布:2.4.0)* 2018.02.28 update, Spark 2.3 全系列 √ (已发布:2.3.0 ~ 2.3.2)* 2017.07.11 update, Spark 2.

Flink重点难点:状态(Checkpoint和Savepoint)容错与两阶段提交
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》《Flink重点难点:网络流控和反压》《Flink重点难点:维表关联理论和Join实战》《Flink重点难点:内存模型与内存结构》《Flink重点难点:Flink Table&SQL必知必会(一)》Flink重点难点:Flink Table&SQL必

干货!高容错微服务架构设计思路
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 微服务架构可以通过明确定义的服务边界来隔离故障。但是像在每个分布式系统中一样,发生网络、硬件、应用级别的错误都是很常见的。由于服务依赖关系,任何组件可能暂时无法提供服务。为了尽量减少部分中断的影响,我们需要构建容错服务,来优雅地处理这些中断的响应结果。 本文介绍了基于RisingStack 的

RocketMQ源码分析----Producer队列选择与容错策略
队列选择 在HA的文章里大概讲了一下Producer如何为高可用贡献出一份力量的,当时只是说了遍历列表选择队列,然后选择一个,没有深入分析,这篇文章深入分析一下其源码,首先从发送消息选择队列的代码开始: String lastBrokerName = null == mq ? null : mq.getBrokerName();MessageQueue tmpmq = this.sel

Nginx: 负载均衡场景下上游服务器异常时的容错机制
容错机制 当负载均衡网络上的应用程序服务器,由于内部的某一些原因或者是网络原因导致的请求迟迟没有处理完,那这个时候我们是否可以做一些容错措施比如说可以将这个失败的请求继续由Nginx转发给另外一台服务器如果说有了这样一些容错机制的话,也是大大提高了我们整个系统的一个健壮性在反向代理场景中也有一些指令,用来定义这样一些功能的 1 )proxy_next_upstream 指令 语法:prox

dubbo:dubbo服务负载均衡、集群容错、服务降级、服务直连配置详解(五)
文章目录 0. 引言1. dubbo负载均衡1.1 负载均衡算法1.2. dubbo负载均衡使用1.3 自定义负载均衡策略 2. dubbo服务容错2.1 8种服务容错策略2.2 自定义容错策略 3. dubbo服务降级(mock)4. dubbo服务直连5. 总结 0. 引言 之前我们讲解了dubbo的基本使用,但在dubbo服务调用过程中,为了保证高可用dubbo提供者一般不
(十七)Flink 容错机制
目录 分布式快照 Checkpoint Checkpoint 模式 Checkpoint 配置 非对齐 Checkpointing 状态存储 Savepoint 分配算子 ID Savepoint 操作 Checkpoint 与 Savepoint 区别 作业重启与故障恢复策略 重启策略 恢复策略 对于不间断 24 小时运行的程序来说,容错至关重要。Flink 定期
服务容错(Service Fault Tolerance)
服务容错(Service Fault Tolerance)是微服务架构中确保系统在部分服务出现故障时仍能继续运行的能力。容错机制的目标是提升系统的鲁棒性和可用性,防止单点故障扩散影响整个系统。以下是一些常见的服务容错机制和最佳实践。 1. 熔断器模式(Circuit Breaker Pattern) 熔断器模式是一种保护系统免受部分服务故障影响的技术。当某个服务出现故障或响应缓慢时,熔断器会快

【吊打面试官系列-Memcached面试题】memcached 如何处理容错的?
大家好,我是锋哥。今天分享关于 【memcached 如何实现冗余机制? 】面试题,希望对大家有帮助; memcached 如何实现冗余机制? 不处理! 在 memcached 节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择: 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网
阿里笔试题第二题之-------容错技术
阿里笔试题第二题之——-容错技术 定义:容错就是当由于种种原因在系统中出现了数据、文件损坏或丢失时,系统能够自动将这些损坏或丢失的文件和数据恢复到发生事故以前的状态,使系统能够连续正常运行一种技术。 容错FT(Fault Tolerant)技术一般利用冗余硬件交叉检测操作结果。随着处理器速度的加快和价格的下跌而越来越多地转移到软件中。未来容错技术将完全在软件环境下完成,那时它和高可用性技术之间

分布式,容错:10台电脑坏了2台
由10台电脑组成的分布式系统,随机、任意坏了2台,剩下的8台电脑仍然储存着全部信息,可以继续服务。这是怎么做到的? 设N台电脑,坏了H台,要保证上述性质,需要有冗余,总的存储量降低为1/(H+1)。例如: H=1,随机坏1台,总容量变为1/2; H=2,随机坏2台,总容量变为1/3; 特别地,H=0,总容量不变; H=N-1,总容量变为1/N,这时,每台电脑都储存着全部信息,保证任意坏了N-1台
分布式共识算法(故障容错算法)系列整理(五):ZAB
五篇分布式共识系列文章合集: 分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos 分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR 分布式共识算法(故障容错算法)系列整理(三):Paxos 分布式共识算法(故障容错算法)系列整理(四):Raft 分布式共识算法(故障容错算法)系列整理(五):ZAB Replicated State Ma
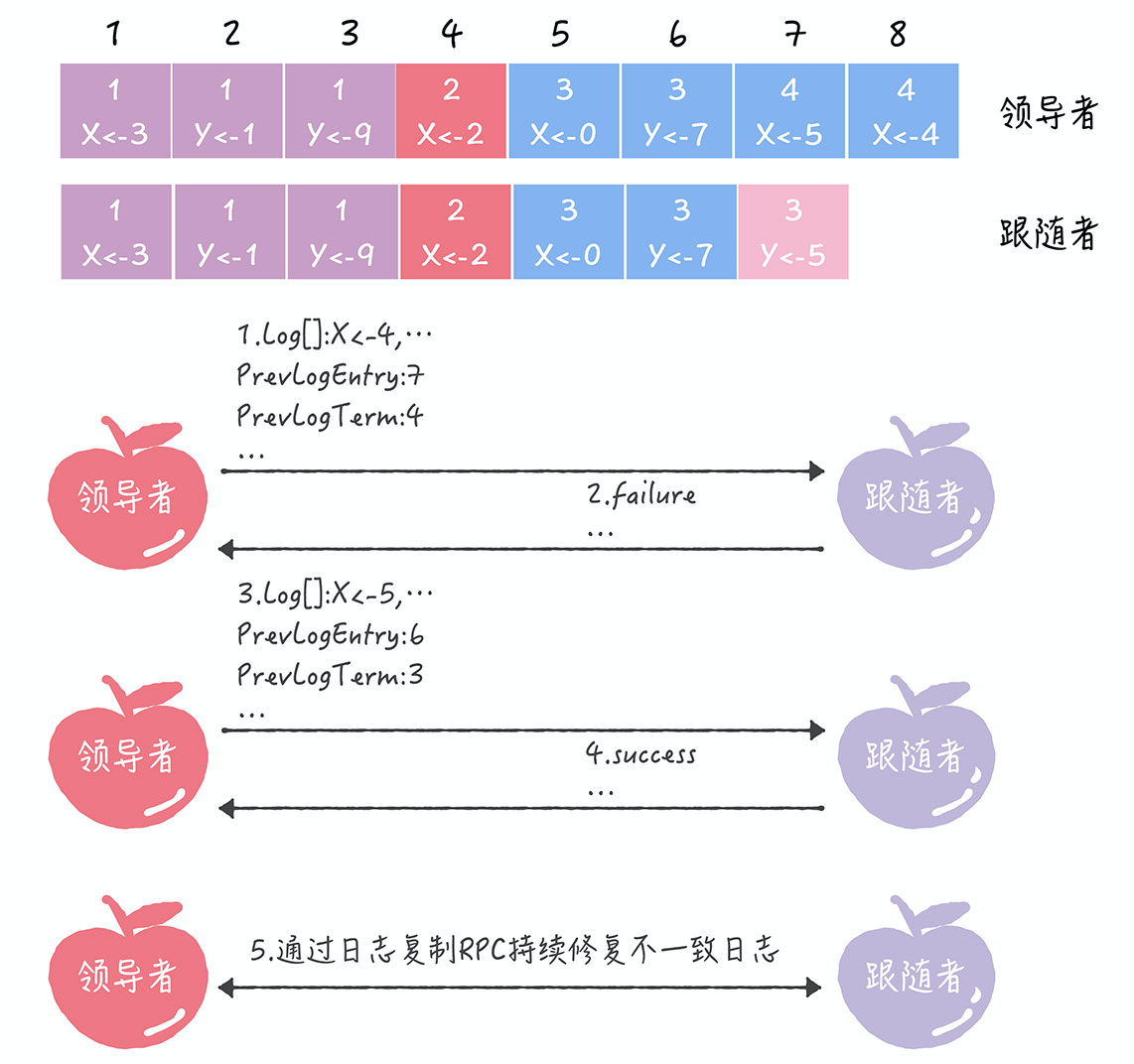
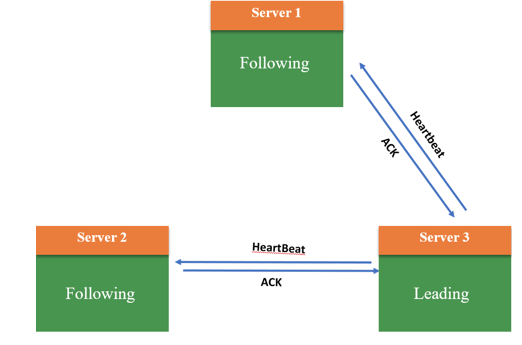
分布式共识算法(故障容错算法)系列整理(四):Raft
五篇分布式共识系列文章合集: 分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos 分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR 分布式共识算法(故障容错算法)系列整理(三):Paxos 分布式共识算法(故障容错算法)系列整理(四):Raft 分布式共识算法(故障容错算法)系列整理(五):ZAB Raft算法的成员身份(服务器节点状态
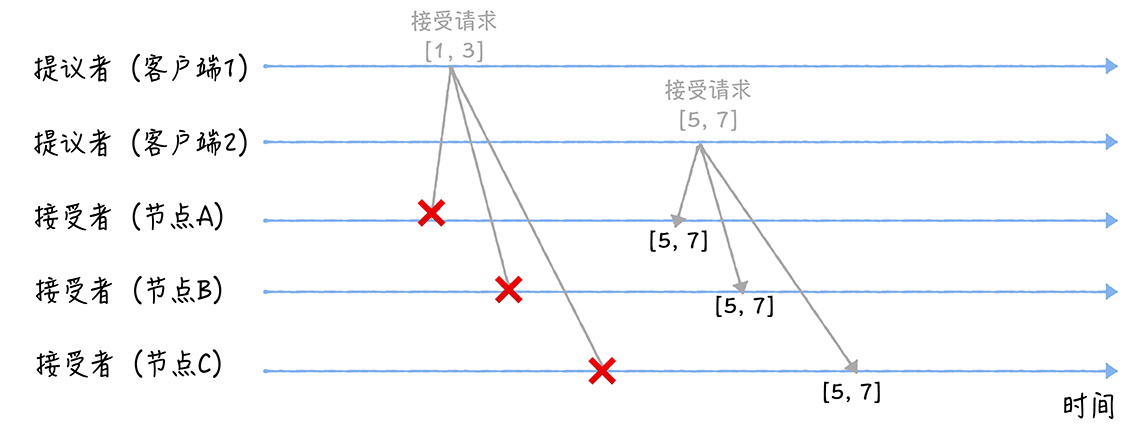
分布式共识算法(故障容错算法)系列整理(三):Paxos
五篇分布式共识系列文章合集: 分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos 分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR 分布式共识算法(故障容错算法)系列整理(三):Paxos 分布式共识算法(故障容错算法)系列整理(四):Raft 分布式共识算法(故障容错算法)系列整理(五):ZAB Basic Paxos Baxos

分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR
五篇分布式共识系列文章合集: 分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos 分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR 分布式共识算法(故障容错算法)系列整理(三):Paxos 分布式共识算法(故障容错算法)系列整理(四):Raft 分布式共识算法(故障容错算法)系列整理(五):ZAB 导语 为什么要有分布式选举? 主节

Dubbo 的集群容错模式:Forking Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa
Dubbo 的集群容错模式:Failback Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa
Dubbo 的集群容错模式:Failsafe Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa

Dubbo 的集群容错模式:Failfast Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa
Dubbo 的集群容错模式:Failover Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa

Spring Boot集成 Spring Retry 实现容错重试机制并附源码
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》专栏主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识
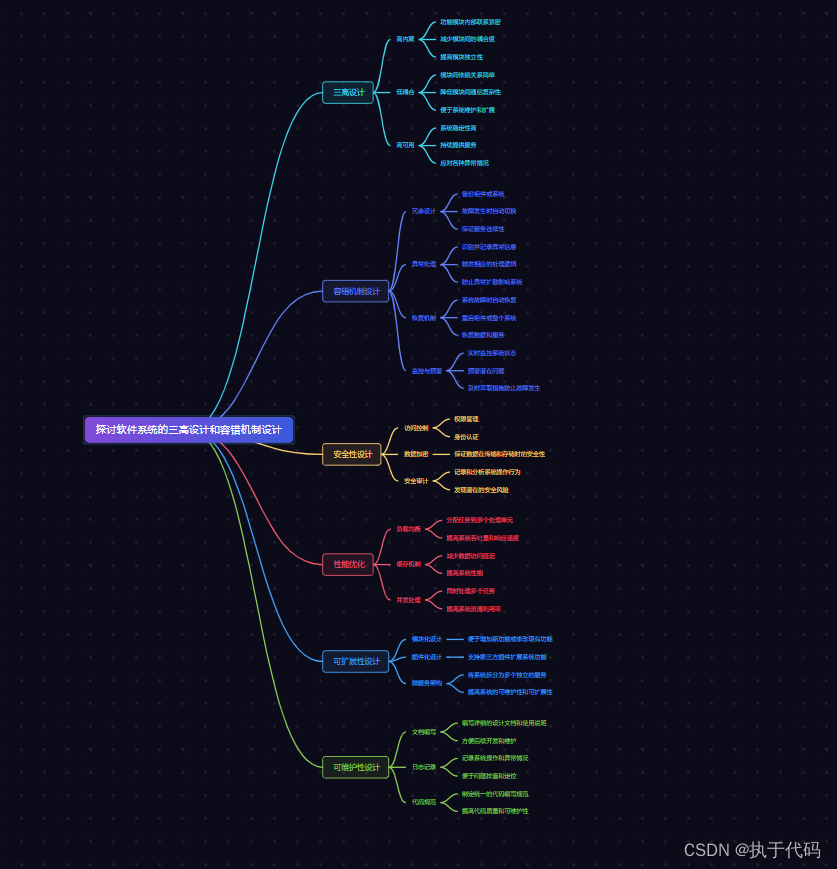
5.6 探讨软件系统的三高设计和容错机制设计
一、引言 1. 软件系统的重要性 软件系统的三高性能设计和容错性设计是非常重要的,因为它们直接影响着系统的可用性、可靠性和效率。以下是它们的重要性: 1. 高性能设计:高性能设计意味着系统能够在高负载和大并发情况下仍能保持良好的响应速度和吞吐量。这对于处理大量的数据和请求非常关键,尤其是在现代互联网应用和分布式系统中。高性能设计可以提高用户体验,减少等待时间,提升系统的效率和生产力。
12、架构-流量治理之服务容错
概述 容错性设计(Design for Failure)是微服务的另一个核心原 则,也是笔者书中反复强调的开发观念转变。不过,即使已经有一定 的心理准备,大多数首次将微服务架构引入实际生产系统的开发者, 在服务发现、网关路由等支持下,踏出了服务化的第一步以后,很可 能仍会经历一段阵痛期,随着拆分出的服务越来越多,随之而来会面 临以下两个问题的困扰。 由于某一个服
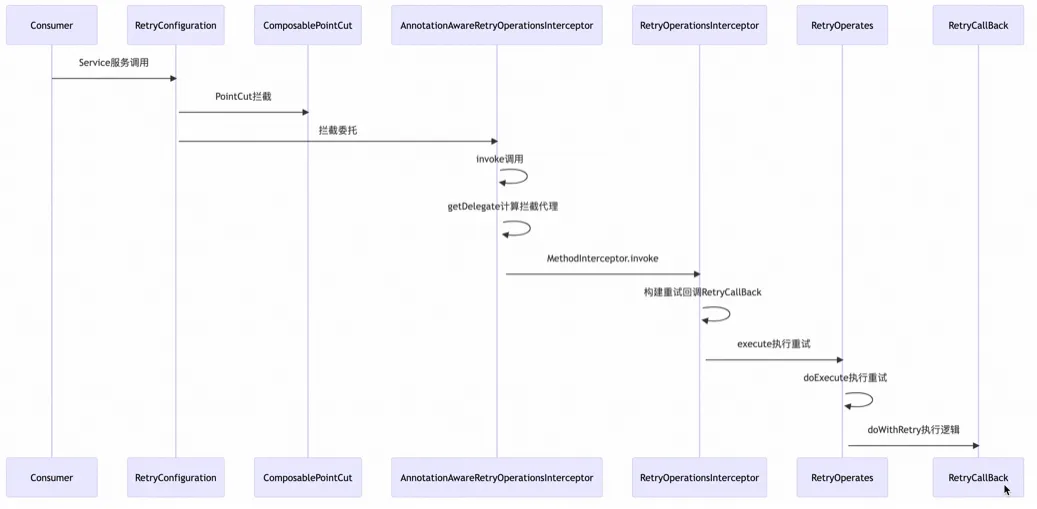
技术积累1:Java容错机制
如何优雅地重试 原创 赵九文 字节跳动技术团队 2021-01-05 10:01 背景 在微服务架构中,一个大系统被拆分成多个小服务,小服务之间大量 RPC 调用,经常可能因为网络抖动等原因导致 RPC 调用失败,这时候使用重试机制可以提高请求的最终成功率,减少故障影响,让系统运行更稳定。 重试的风险 重试能够提高服务稳定性,但是一般情况下大家都不会轻易去重试,或者说不敢重试,主要是
Python怎么容错:深度探索错误处理与异常机制
Python怎么容错:深度探索错误处理与异常机制 在Python编程中,容错机制是确保程序稳健运行的关键。当代码执行过程中遇到异常情况时,良好的容错机制能够捕获并处理这些异常,防止程序崩溃或产生不可预测的行为。那么,Python究竟如何容错呢?接下来,我们将从四个方面、五个方面、六个方面和七个方面进行深入探讨。 四个方面:Python异常处理基础 首先,我们需要了解Python异常处理的基本
Resilience4j——轻量级容错库
1. resilience4j是什么? Resilience4j是一个轻量级的容错库,受Netflix Hystrix的启发,但专为Java 8和函数式编程而设计。轻量级,因为库只使用Vavr,它没有任何其他外部库依赖项。相比之下,Netflix Hystrix对Archaius具有编译依赖性,Archaius具有更多的外部库依赖性,例如Guava和Apache Commons Configur