本文主要是介绍技术积累1:Java容错机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何优雅地重试
原创 赵九文 字节跳动技术团队 2021-01-05 10:01
背景
在微服务架构中,一个大系统被拆分成多个小服务,小服务之间大量 RPC 调用,经常可能因为网络抖动等原因导致 RPC 调用失败,这时候使用重试机制可以提高请求的最终成功率,减少故障影响,让系统运行更稳定。
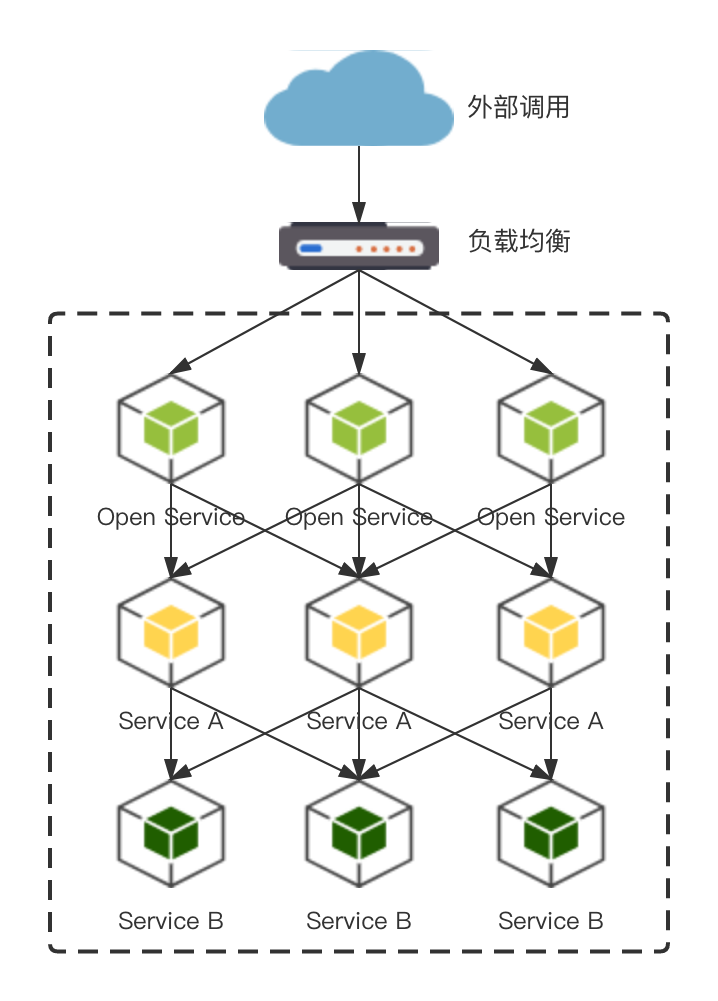
重试的风险
重试能够提高服务稳定性,但是一般情况下大家都不会轻易去重试,或者说不敢重试,主要是因为重试有放大故障的风险。
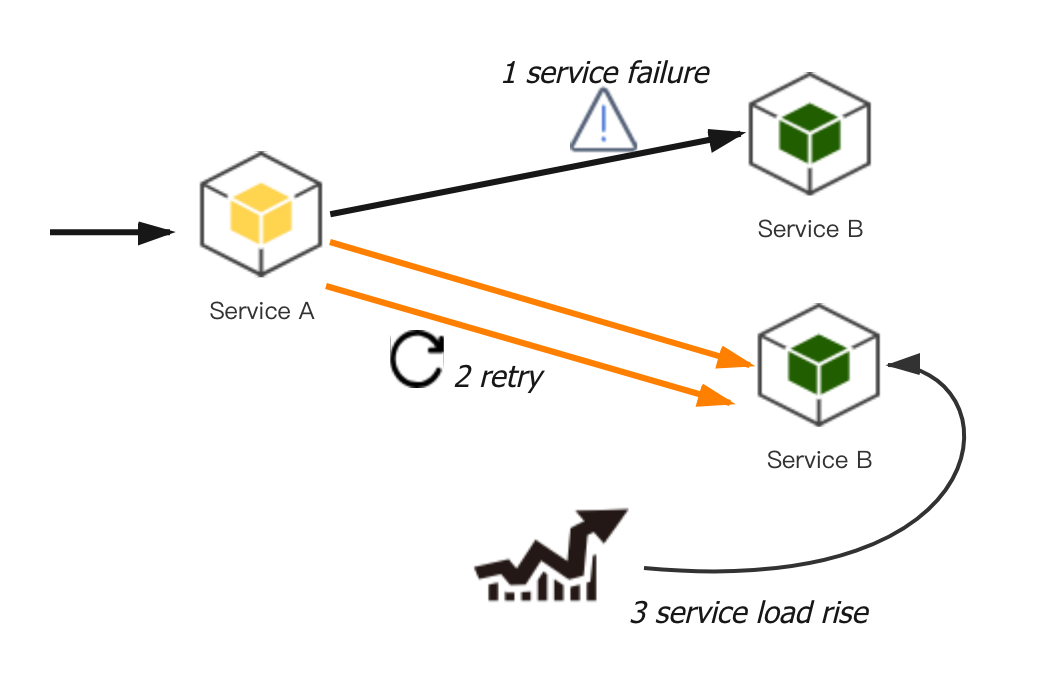
首先,重试会加大直接下游的负载。如下图,假设 A 服务调用 B 服务,重试次数设置为 r(包括首次请求),当 B 高负载时很可能调用不成功,这时 A 调用失败重试 B ,B 服务的被调用量快速增大,最坏情况下可能放大到 r 倍,不仅不能请求成功,还可能导致 B 的负载继续升高,甚至直接打挂。
更可怕的是,重试还会存在链路放大的效应,结合下图说明一下:
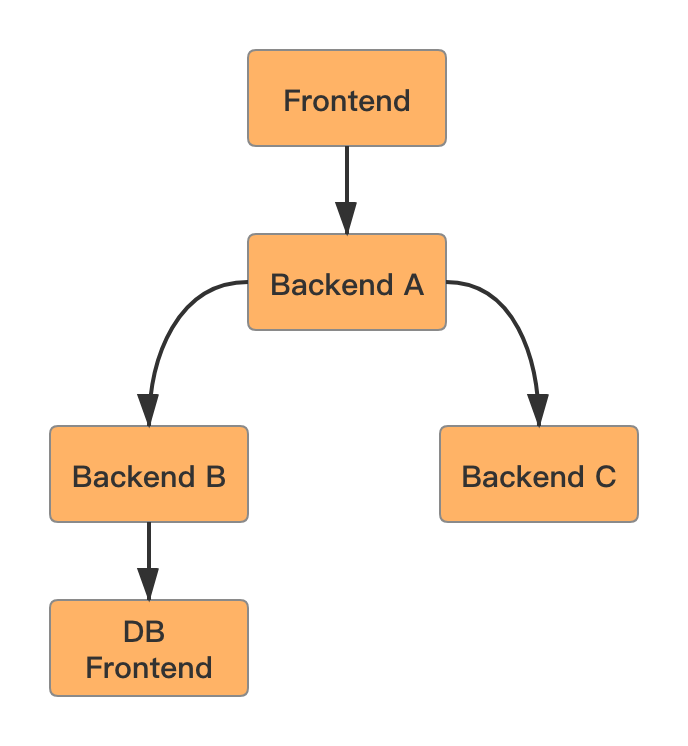
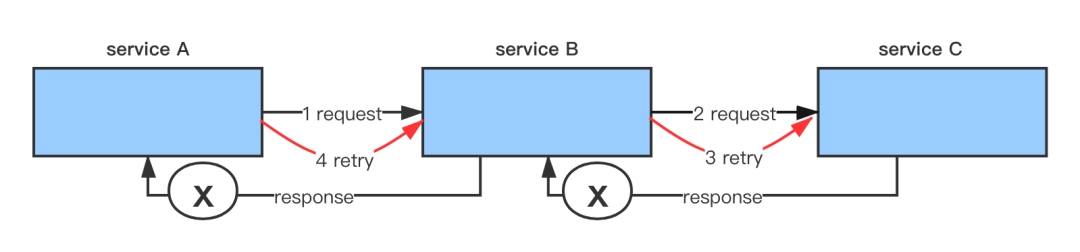
假设现在场景是 Backend A 调用 Backend B,Backend B 调用 DB Frontend,均设置重试次数为 3 。如果 Backend B 调用 DB Frontend,请求 3 次都失败了,这时 Backend B 会给 Backend A 返回失败。但是 Backend A 也有重试的逻辑,Backend A 重试 Backend B 三次,每一次 Backend B 都会请求 DB Frontend 3 次,这样算起来,DB Frontend 就会被请求了 9 次,实际是指数级扩大。假设正常访问量是 n,链路一共有 m 层,每层重试次数为 r,则最后一层受到的访问量最大,为 n * r ^ (m - 1) 。这种指数放大的效应很可怕,可能导致链路上多层都被打挂,整个系统雪崩。
重试的使用成本
另外使用重试的成本也比较高。之前在字节跳动的内部框架和服务治理平台中都没有支持重试,在一些很需要重试的业务场景下(比如调用一些第三方业务经常失败),业务方可能用简单 for 循环来实现,基本不会考虑重试的放大效应,这样很不安全,公司内部出现过多次因为重试而导致的事故,且出事故的时候还需要修改代码上线才能关闭重试,导致事故恢复也不迅速。
另外也有一些业务使用开源的重试组件,这些组件通常会考虑对直接下游的保护,但不会考虑链路级别的重试放大,另外需要业务方修改 RPC 调用代码才能使用,对业务代码入侵较多,而且也是静态配置,需要修改配置时都必须重新上线。
基于以上的背景,为了让业务方能够灵活安全的使用重试,我们字节跳动直播中台团队设计和实现了一个重试治理组件,具有以下优点:
-
能够在链路级别防重试风暴。
-
保证易用性,业务接入成本小。
-
具有灵活性,能够动态调整配置。
下面介绍具体的实现方案。
重试治理
动态配置
如何让业务方简单接入是首先要解决的问题。如果还是普通组件库的方式,依旧免不了要大量入侵用户代码,且很难动态调整。
字节跳动的 Golang 开发框架支持中间件 (Milddleware) 模式,可以注册多个自定义 Middleware 并依次递归调用,通常是用于完成打印日志、上报监控等非业务逻辑,能够有效将业务和非业务代码功能进行解耦。因此我们决定使用 Middleware 的方式来实现重试功能,定义一个 Middleware 并在内部实现对 RPC 的重复调用,把重试的配置信息用字节跳动的分布式配置存储中心存储,这样 Middleware 中能够读取配置中心的配置并进行重试,对用户来说不需要修改调用 RPC 的代码,而只需要在服务中引入一个全局的 Middleware 即可。
如下面的整体架构图所示,我们提供配置的网页和后台,用户能够在专门进行服务治理的页面上很方便的对 RPC 进行配置修改并自动生效,内部的实现逻辑对用户透明,对业务代码无入侵。
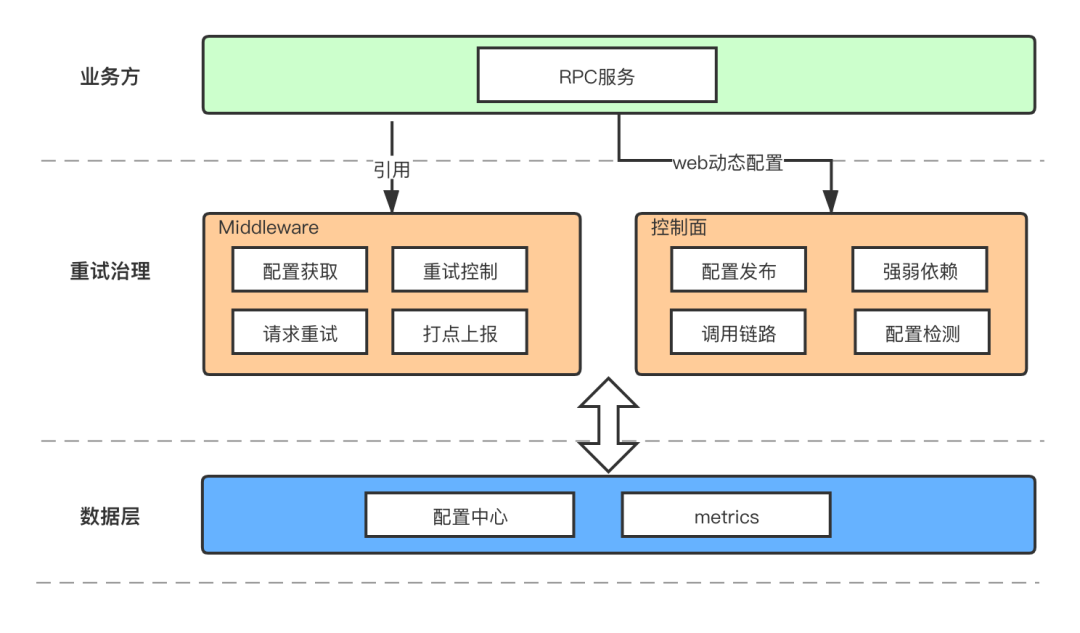
配置的维度按照字节跳动的 RPC 调用特点,选定 [调用方服务,调用方集群,被调用服务, 被调用方法] 为一个元组,按照元组来进行配置。Middleware 中封装了读取配置的方法,在 RPC 调用的时候会自动读取并生效。
这种 Middleware 的方式能够让业务方很容易接入,相对于之前普通组件库的方式要方便很多,并且一次接入以后就具有动态配置的能力,可能很方便地调整或者关闭重试配置。
退避策略
确定了接入方式以后就可以开始实现重试组件的具体功能,一个重试组件所包含的基本功能中,除了重试次数和总延时这样的基础配置外,还需要有退避策略。
对于一些暂时性的错误,如网络抖动等,可能立即重试还是会失败,通常等待一小会儿再重试的话成功率会较高,并且也可能打散上游重试的时间,较少因为同时都重试而导致的下游瞬间流量高峰。决定等待多久之后再重试的方法叫做退避策略,我们实现了常见的退避策略,如:
-
线性退避:每次等待固定时间后重试。
-
随机退避:在一定范围内随机等待一个时间后重试。
-
指数退避:连续重试时,每次等待时间都是前一次的倍数。
防止 retry storm
如何安全重试,防止 retry storm 是我们面临的最大的难题。
限制单点重试
首先要在单点进行限制,一个服务不能不受限制的重试下游,很容易造成下游被打挂。除了限制用户设定的重试次数上限外,更重要的是限制重试请求的成功率。
实现的方案很简单,基于断路器的思想,限制 请求失败/请求成功 的比率,给重试增加熔断功能。我们采用了常见的滑动窗口的方法来实现,如下图,内存中为每一类 RPC 调用维护一个滑动窗口,比如窗口分 10 个 bucket ,每个 bucket 里面记录了 1s 内 RPC 的请求结果数据(成功、失败)。新的一秒到来时,生成新的 bucket ,并淘汰最早的一个 bucket ,只维持 10s 的数据。在新请求这个 RPC 失败时,根据前 10s 内的 失败/成功 是否超过阈值来判断是否可以重试。默认阈值是 0.1 ,即下游最多承受 1.1 倍的 QPS ,用户可以根据需要自行调整熔断开关和阈值。
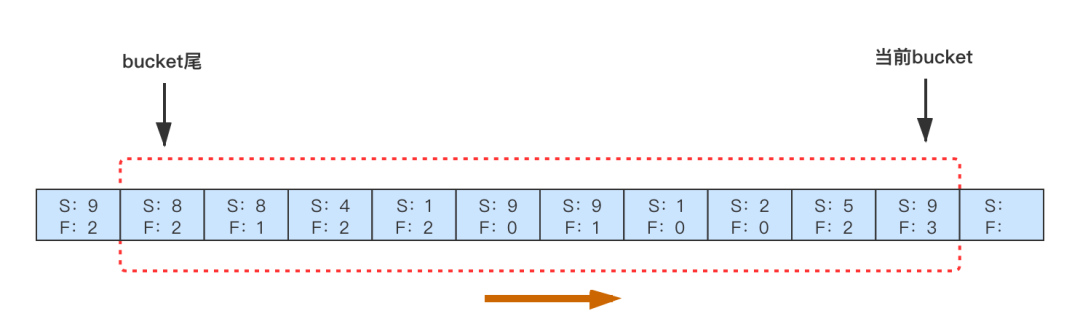
限制链路重试
前面说过在多级链路中如果每层都配置重试可能导致调用量指数级扩大,虽然有了重试熔断之后,重试不再是指数增长(每一单节点重试扩大限制了 1.1 倍),但还是会随着链路的级数增长而扩大调用次数,因此还是需要从链路层面来考虑重试的安全性。
链路层面的防重试风暴的核心是限制每层都发生重试,理想情况下只有最下一层发生重试。Google SRE 中指出了 Google 内部使用特殊错误码的方式来实现:
-
统一约定一个特殊的 status code ,它表示:调用失败,但别重试。
-
任何一级重试失败后,生成该 status code 并返回给上层。
-
上层收到该 status code 后停止对这个下游的重试,并将错误码再传给自己的上层。
这种方式理想情况下只有最下一层发生重试,它的上游收到错误码后都不会重试,链路整体放大倍数也就是 r 倍(单层的重试次数)。但是这种策略依赖于业务方传递错误码,对业务代码有一定入侵,而且通常业务方的代码差异很大,调用 RPC 的方式和场景也各不相同,需要业务方配合进行大量改造,很可能因为漏改等原因导致没有把从下游拿到的错误码传递给上游。
好在字节跳动内部用的 RPC 协议中有扩展字段,我们在 Middleware 中做了很多尝试,封装了错误码处理和传递的逻辑,在 RPC 的 Response 扩展字段中传递错误码标识 nomore_retry ,它告诉上游不要再重试了。Middleware 完成错误码的生成、识别、传递等整个生命周期的管理,不需要业务方修改本身的 RPC 逻辑,错误码的方案对业务来说是透明的。
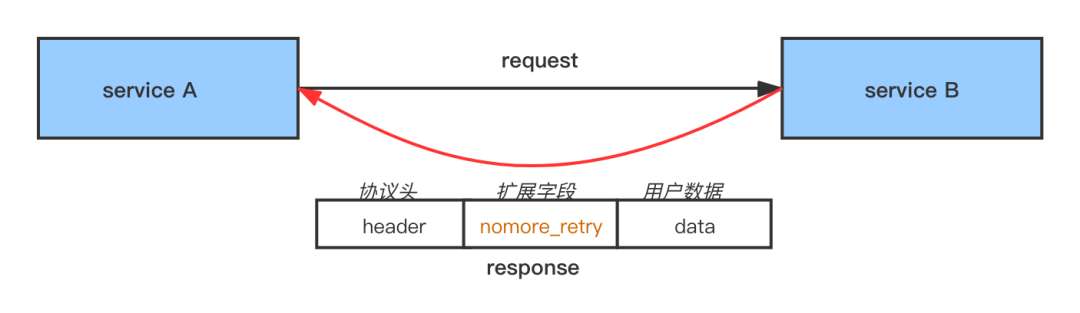
在链路中,推进每层都接入重试组件,这样每一层都可以通过识别这个标志位来停止重试,并逐层往上传递,上层也都停止重试,做到链路层面的防护,达到“只有最靠近错误发生的那一层才重试”的效果。
超时处理
在测试错误码上传的方案时,我们发现超时的情况可能导致传递错误码的方案失效。
对于 A -> B -> C 的场景,假设 B -> C 超时,B 重试请求 C ,这时候很可能 A -> B 也超时了,所以 A 没有拿到 B 返回的错误码,而是也会重试 B , 这个时候虽然 B 重试 C 且生成了重试失败的错误码,但是却不能再传递给 A 。这种情况下,A 还是会重试 B ,如果链路中每一层都超时,那么还是会出现链路指数扩大的效应。
因此为了处理这种情况,除了下游传递重试错误标志以外,我们还实现了“对重试请求不重试”的方案。
对于重试的请求,我们在 Request 中打上一个特殊的 retry flag ,在上面 A -> B -> C 的链路,当 B 收到 A 的请求时会先读取这个 flag 判断这个请求是不是重试请求,如果是,那它调用 C 即使失败也不会重试;否则调用 C 失败后会重试 C 。同时 B 也会把这个 retry flag 下传,它发出的请求也会有这个标志,它的下游也不会再对这个请求重试。
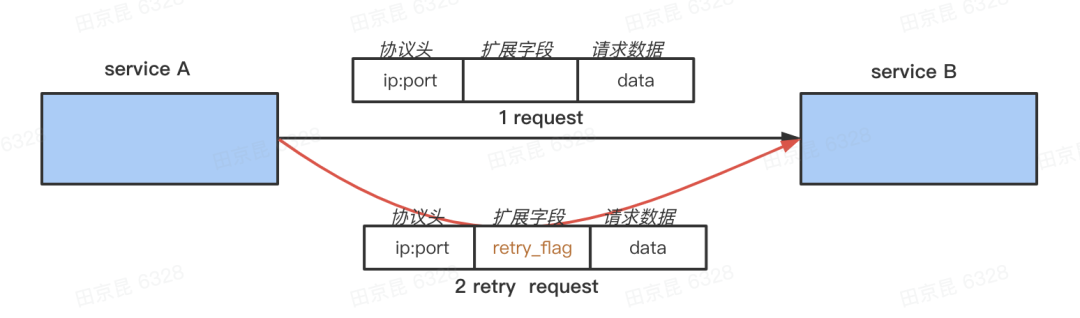
这样即使 A 因为超时而拿不到 B 的返回,对 B 发出重试请求后,B 能感知到并且不会对 C 重试,这样 A 最多请求 r 次,B 最多请求 r + r - 1,如果后面还有更下层次的话,C 最多请求 r + r + r - 2 次, 第 i 层最多请求 i * r - (i-1) 次,最坏情况下是倍数增长,不是指数增长了。加上实际还有重试熔断的限制,增长的幅度要小很多。
通过重试熔断来限制单点的放大倍数,通过重试错误标志链路回传的方式来保证只有最下层发生重试,又通过重试请求 flag 链路下传的方式来保证对重试请求不重试,多种控制策略结合,可以有效地较少重试放大效应。
超时场景优化
分布式系统中,RPC 请求的结果有三种状态:成功、失败、超时,其中最难处理的就是超时的情况。但是超时往往又是最经常发生的那一个,我们统计了字节跳动直播业务线上一些重要服务的 RPC 错误分布,发现占比最高的就是超时错误,怕什么偏来什么。
在超时重试的场景中,虽然给重试请求添加 retry flag 能防止指数扩大,但是却不能提高请求成功率。如下图,假如 A 和 B 的超时时间都是 1000ms ,当 C 负载很高导致 B 访问 C 超时,这时 B 会重试 C ,但是时间已经超过了 1000ms ,时间 A 这里也超时了并且断开了和 B 的连接,所以 B 这次重试 C 不管是否成功都是无用功,从 A 的视角看,本次请求已经失败了。
这种情况的本质原因是因为链路上的超时时间设置得不合理,上游和下游的超时时间设置的一样,甚至上游的超时时间比下游还要短。在实际情况中业务一般都没有专门配置过 RPC 的超时时间,所以可能上下游都是默认的超时,时长是一样的。为了应对这种情况,我们需要有一个机制来优化超时情况下的稳定性,并减少无用的重试。
如下图,正常重试的场景是等拿到 Resp1 (或者拿到超时结果) 后再发起第二次请求,整体耗时是 t1 + t2 。我们分析下,service A 在发出去 Req1 之后可能等待很长的时间,比如 1s ,但是这个请求的 pct99 或者 pct999 可能通常只有 100ms 以内,如果超过了 100ms ,有很大概率是这次访问最终会超时,能不能不要傻等,而是提前重试呢?
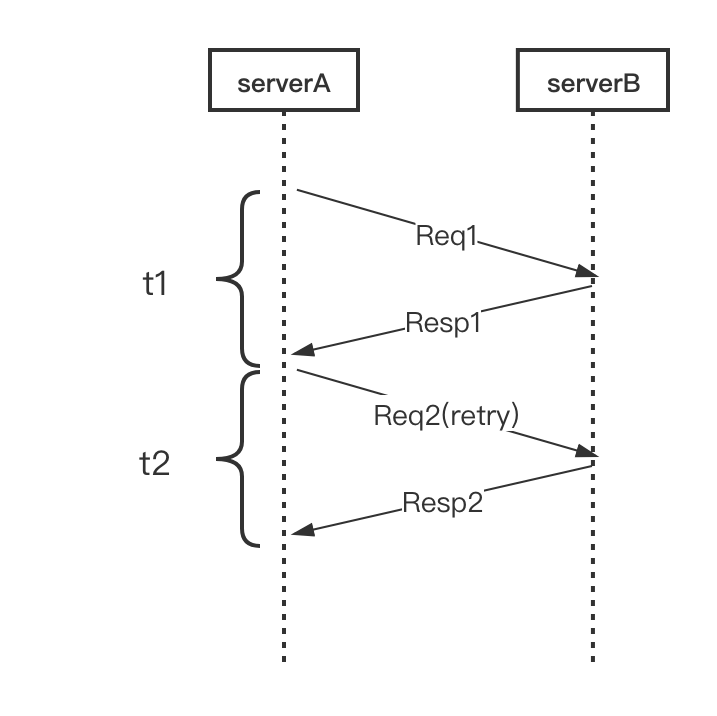
基于这种思想,我们引入并实现了 Backup Requests 的方案。如下图,我们预先设定一个阈值 t3(比超时时间小,通常建议是 RPC 请求延时的 pct99 ),当 Req1 发出去后超过 t3 时间都没有返回,那我们直接发起重试请求 Req2 ,这样相当于同时有两个请求运行。然后等待请求返回,只要 Resp1 或者 Resp2 任意一个返回成功的结果,就可以立即结束这次请求,这样整体的耗时就是 t4 ,它表示从第一个请求发出到第一个成功结果返回之间的时间,相比于等待超时后再发出请求,这种机制能大大减少整体延时。
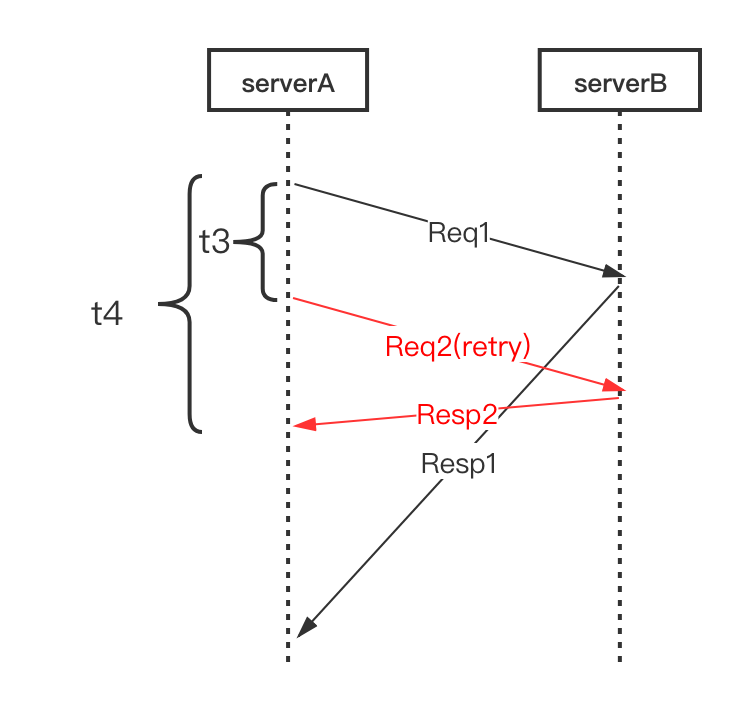
实际上 Backup Requests 是一种用访问量来换成功率 (或者说低延时) 的思想,当然我们会控制它的访问量增大比率,在发起重试之前,会为第一次的请求记录一次失败,并检查当前失败率是否超过了熔断阈值,这样整体的访问比率还是会在控制之内。
结合 DDL
Backup Requests 的思路能在缩短整体请求延时的同时减少一部分的无效请求,但不是所有业务场景下都适合配置 Backup Requests ,因此我们又结合了 DDL 来控制无效重试。
DDL 是“ Deadline Request 调用链超时”的简称,我们知道 TCP/IP 协议中的 TTL 用于判断数据包在网络中的时间是否太长而应被丢弃,DDL 与之类似,它是一种全链路式的调用超时,可以用来判断当前的 RPC 请求是否还需要继续下去。如下图,字节跳动的基础团队已经实现了 DDL 功能,在 RPC 请求调用链中会带上超时时间,并且每经过一层就减去该层处理的时间,如果剩下的时间已经小于等于 0 ,则可以不需要再请求下游,直接返回失败即可。
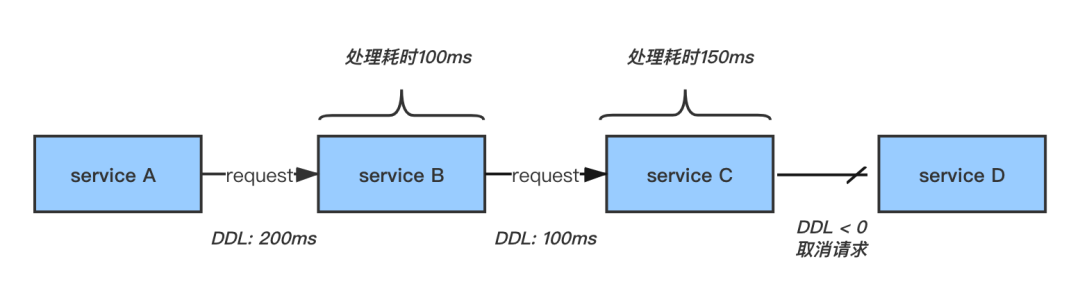
DDL 的方式能有效减少对下游的无效调用,我们在重试治理中也结合了 DDL 的数据,在每一次发起重试前都会判断 DDL 的剩余值是否还大于 0 ,如果已经不满足条件了,那也就没必要对下游重试,这样能做到最大限度的减少无用的重试。
实际的链路放大效应
之前说的链路指数放大是理想情况下的分析,实际的情况要复杂很多,因为有很多影响因素:
| 策略 | 说明 |
|---|---|
| 重试熔断 | 请求失败 / 成功 > 0.1 时停止重试 |
| 链路上传错误标志 | 下层重试失败后上传错误标志,上层不再重试 |
| 链路下传重试标志 | 重试请求特殊标记,下层对重试请求不会重试 |
| DDL | 当剩余时间不够时不再发起重试请求 |
| 框架熔断 | 微服务框架本身熔断、过载保护等机制也会影响重试效果 |
各种因素综合下来,最终实际方法情况不是一个简单的计算公式能说明,我们构造了多层调用链路,在线上实际测试和记录了在不同错误类型、不同错误率的情况下使用重试治理组件的效果,发现接入重试治理组件后能够在链路层面有效的控制重试放大倍数,大幅减少重试导致系统雪崩的概率。
总结
如上所述,基于服务治理的思想我们开发了重试治理的功能,支持动态配置,接入方式基本无需入侵业务代码,并使用多种策略结合的方式在链路层面控制重试放大效应,兼顾易用性、灵活性、安全性,在字节跳动内部已经有包括直播在内的很多服务接入使用并上线验证,对提高服务本身稳定性有良好的效果。目前方案已经被验证并在字节跳动直播等业务推广,后续将为更多的字节跳动业务服务。
容错编程是一种重要的编程思想,它能够提高应用程序的可靠性和稳定性,同时提高代码的健壮性。本文总结了一些作者在面对服务失败时如何进行优雅重试,比如aop、cglib等同时对重试工具\组件的源码和注意事项进行总结分析。
容错编程是一种旨在确保应用程序的可靠性和稳定性的编程思想,它采取以下措施:
1.异常处理:通过捕获和处理异常来避免应用程序崩溃。
2.错误处理:通过检查错误代码并采取适当的措施,如重试或回滚,来处理错误。
3.重试机制:在出现错误时,尝试重新执行代码块,直到成功或达到最大尝试次数。
4.备份机制:在主要系统出现故障时,切换到备用系统以保持应用程序的正常运行。
5.日志记录:记录错误和异常信息以便后续排查问题。
容错编程是一种重要的编程思想,它能够提高应用程序的可靠性和稳定性,同时提高代码的健壮性。
一、为什么需要重试
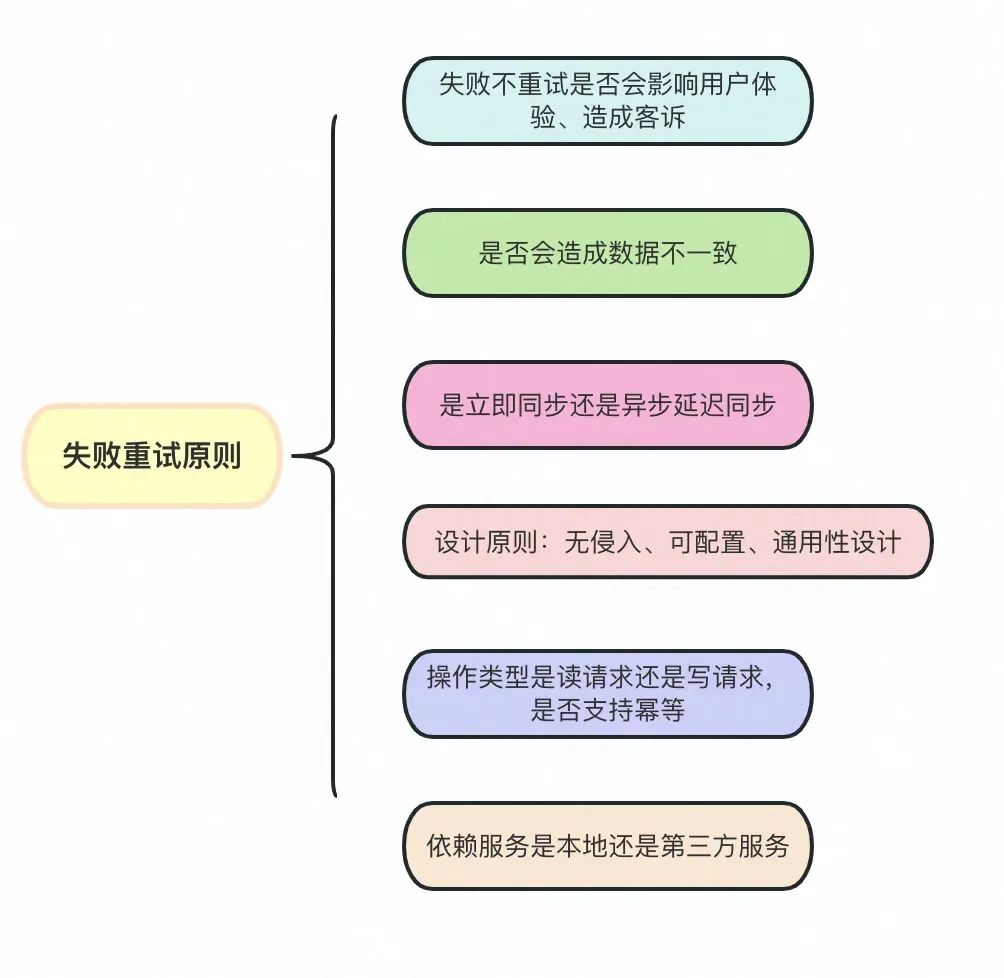
在做业务技术时,设计具备可复用、可扩展、可编排的系统架构至关重要,它直接决定着业务需求迭代的效率。但同时业务技术人员也应具备悲观思维:在分布式环境下因单点问题导致的HSF服务瞬时抖动并不少见,比如系统瞬时抖动、单点故障、服务超时、服务异常、中间件抖动、网络超时、配置错误等等各种软硬件问题。如果直接忽略掉这些异常则会降低服务的健壮性,严重时会影响用户体验、引起用户投诉,甚至导致系统故障。因此在做方案设计和技术实现时要充分考虑各种失败场景,针对性地做防御性编程。
我们在调用第三方接口时,经常会遇到失败的情况,针对这些情况,我们通常会处理失败重试和失败落库逻辑。然而,重试并不是适用于所有场景的,例如参数校验不合法、读写操作是否适合重试,数据是否幂等。远程调用超时或网络突然中断则可以进行重试。我们可以设置多次重试来提高调用成功的概率。为了方便后续排查问题和统计失败率,我们也可以将失败次数和是否成功记录落库,便于统计和定时任务兜底重试。
培训研发组在大本营、培训业务、本地e站等多业务对各种失败场景做了充分演练,并对其中一些核心流程做了各种形式的失败重试处理,比如骑手考试提交、同步数据到洞察平台、获取量子平台圈人标签等。本文总结了一些我们在面对服务失败时如何进行优雅重试,比如aop、cglib等同时对重试工具\组件的源码和注意事项进行总结分析。
二、如何重试
2.1 简单重试方法
测试demo
@Test
public Integer sampleRetry(int code) {
System.out.println(“sampleRetry,时间:” + LocalTime.now());
int times = 0;
while (times < MAX_TIMES) {
try {
postCommentsService.retryableTest(code);
} catch (Exception e) {
times++;
System.out.println(“重试次数” + times);
if (times >= MAX_TIMES) {
//记录落库,后续定时任务兜底重试
//do something record…
throw new RuntimeException(e);
}
}
}
System.out.println(“sampleRetry,返回!”);
return null;
}
2.2 动态代理模式版本
在某些情况下,一个对象不适合或不能直接引用另一个对象,这时我们可以使用代理对象来起到中介作用,它可以在客户端和目标对象之间进行通信。使用代理对象的好处在于,它兼容性比较好,每个重试方法都可以调用。
使用方式
public class DynamicProxyTest implements InvocationHandler {
private final Object subject;
public DynamicProxy(Object subject) {
this.subject = subject;
}
/*** 获取动态代理** @param realSubject 代理对象*/
public static Object getProxy(Object realSubject) {// 我们要代理哪个真实对象,就将该对象传进去,最后是通过该真实对象来调用其方法的InvocationHandler handler = new DynamicProxy(realSubject);return Proxy.newProxyInstance(handler.getClass().getClassLoader(),realSubject.getClass().getInterfaces(), handler);
}@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {int times = 0;while (times < MAX_TIMES) {try {// 当代理对象调用真实对象的方法时,其会自动的跳转到代理对象关联的handler对象的invoke方法来进行调用return method.invoke(subject, args);} catch (Exception e) {times++;System.out.println("重试次数" + times);if (times >= MAX_TIMES) {//记录落库,后续定时任务兜底重试//do something record... throw new RuntimeException(e);}}}return null;
}
}
测试demo
@Test
public Integer V2Retry(int code) {
RetryableTestServiceImpl realService = new RetryableTestServiceImpl();
RetryableTesterviceImpl proxyService = (RetryableTestServiceImpl) DynamicProxyTest.getProxy(realService);
proxyService.retryableTest(code);
}
2.3 字节码技术 生成代理重试
CGLIB 是一种代码生成库,它能够扩展 Java 类并在运行时实现接口。它具有功能强大、高性能和高质量的特点。使用 CGLIB 可以生成子类来代理目标对象,从而在不改变原始类的情况下,实现对其进行扩展和增强。这种技术被广泛应用于 AOP 框架、ORM 框架、缓存框架以及其他许多 Java 应用程序中。CGLIB 通过生成字节码来创建代理类,具有较高的性能。
public class CglibProxyTest implements MethodInterceptor {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {int times = 0;while (times < MAX_TIMES) {try {//通过代理子类调用父类的方法return methodProxy.invokeSuper(o, objects);} catch (Exception e) {times++;if (times >= MAX_TIMES) {throw new RuntimeException(e);}}}return null;
}/*** 获取代理类* @param clazz 类信息* @return 代理类结果*/
public Object getProxy(Class clazz){Enhancer enhancer = new Enhancer();//目标对象类enhancer.setSuperclass(clazz);enhancer.setCallback(this);//通过字节码技术创建目标对象类的子类实例作为代理return enhancer.create();
}
}
测试demo
@Test
public Integer CglibRetry(int code) {
RetryableTestServiceImpl proxyService = (RetryableTestServiceImpl) new CglibProxyTest().getProxy(RetryableTestServiceImpl.class);
proxyService.retryableTest(code);
}
2.4 HSF调用超时重试
在我们日常开发中,调用第三方 HSF服务时出现瞬时抖动是很常见的。为了降低调用超时对业务造成的影响,我们可以根据业务特性和下游服务特性,使用 HSF 同步重试的方式。如果使用的框架没有特别设置,HSF 接口超时默认不会进行自动重试。在注解 @HSFConsumer 中,有一个参数 retries,通过它可以设置失败重试的次数。默认情况下,这个参数的值默认是0。
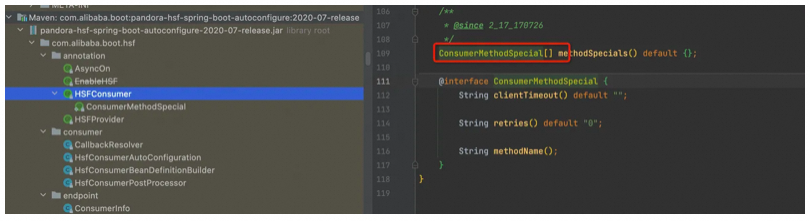
@HSFConsumer(serviceVersion = “1.0.0”, serviceGroup = “hsf”,clientTimeout = 2000, methodSpecials = {
@ConsumerMethodSpecial(methodName = “methodA”, clientTimeout = “100”, retries = “2”),
@ConsumerMethodSpecial(methodName = “methodB”, clientTimeout = “200”, retries = “1”)})
private XxxHSFService xxxHSFServiceConsumer;
HSFConsumer超时重试原理
一次HSF的服务调用过程示意图:
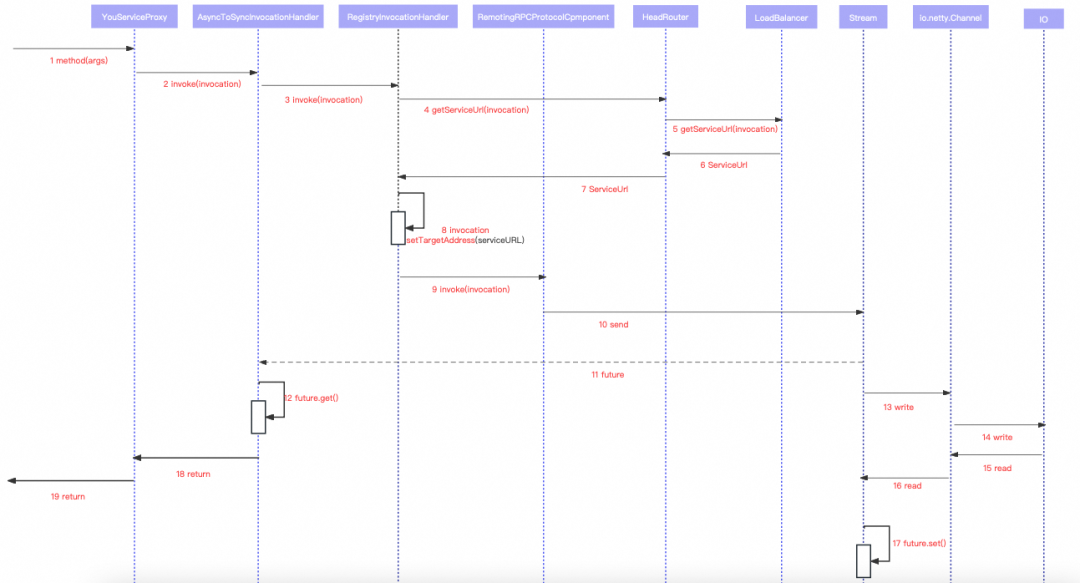
HSF 超时重试发生在AsyncToSyncInvocationHandler # invokeType(.): 如果配置的retries参数大于0则使用retry()方法进行重试,且重试只发生在TimeoutException异常的情况下。
源码分析
private RPCResult invokeType(Invocation invocation, InvocationHandler invocationHandler) throws Throwable {
final ConsumerMethodModel consumerMethodModel = invocation.getClientInvocationContext().getMethodModel();
String methodName = consumerMethodModel.getMethodName(invocation.getHsfRequest());
final InvokeMode invokeType = getInvokeType(consumerMethodModel.getMetadata(), methodName);invocation.setInvokeType(invokeType);ListenableFuture<RPCResult> future = invocationHandler.invoke(invocation);if (InvokeMode.SYNC == invokeType) {if (invocation.getBroadcastFutures() != null && invocation.getBroadcastFutures().size() > 1) {//broadcastreturn broadcast(invocation, future);} else if (consumerMethodModel.getExecuteTimes() > 1) {//retryreturn retry(invocation, invocationHandler, future, consumerMethodModel.getExecuteTimes());} else {//normalreturn getRPCResult(invocation, future);}} else {// pseudo response, should be ignoredHSFRequest request = invocation.getHsfRequest();Object appResponse = null;if (request.getReturnClass() != null) {appResponse = ReflectUtils.defaultReturn(request.getReturnClass());}HSFResponse hsfResponse = new HSFResponse();hsfResponse.setAppResponse(appResponse);RPCResult rpcResult = new RPCResult();rpcResult.setHsfResponse(hsfResponse);return rpcResult;}
}
从上面这段代码可以看出,retry 重试只有发生在同步调用当中。消费者方法的元数据的执行次数大于1(consumerMethodModel.getExecuteTimes() > 1)时会走到retry方法去尝试重试:
private RPCResult retry(Invocation invocation, InvocationHandler invocationHandler,
ListenableFuture future, int executeTimes) throws Throwable {
int retryTime = 0;while (true) {retryTime++;if (retryTime > 1) {future = invocationHandler.invoke(invocation);}int timeout = -1;try {timeout = (int) invocation.getInvokerContext().getTimeout();RPCResult rpcResult = future.get(timeout, TimeUnit.MILLISECONDS);return rpcResult;} catch (ExecutionException e) {throw new HSFTimeOutException(getErrorLog(e.getMessage()), e);} catch (TimeoutException e) {//retry only when timeoutif (retryTime < executeTimes) {continue;} else {throw new HSFTimeOutException(getErrorLog(e.getMessage()), timeout + "", e);}} catch (Throwable e) {throw new HSFException("", e);}}
}
HSFConsumer超时重试原理利用的是简单的while循环+ try-catch
缺陷:
1、只有方法被同步调用时候才会发生重试。
2、只有hsf接口出现TimeoutException才会调用重试方法。
3、如果为某个 HSFConsumer 中的 method 设置了 retries 参数,当方法返回时出现超时异常,HSF SDK 会自动重试。重试实现的方式是一个 while+ try-catch循环。所以,如果自动重试的接口变得缓慢,而且重试次数设置得过大,会导致 RT 变长,极端情况下还可能导致 HSF 线程池被打满。因此,HSF 的自动重试特性是一个基础、简单的能力,不推荐大面积使用。
2.5 Spring Retry
Spring Retry 是 Spring 系列中的一个子项目,它提供了声明式的重试支持,可以帮助我们以标准化的方式处理任何特定操作的重试。这个框架非常适合于需要进行重试的业务场景,比如网络请求、数据库访问等。使用 Spring Retry,我们可以使用注解来设置重试策略,而不需要编写冗长的代码。所有的配置都是基于注解的,这使得使用 Spring Retry 变得非常简单和直观。
POM依赖
<dependency>
启用@Retryable
引入spring-retry jar包后在spring boot的启动类上打上@EnableRetry注解。
@EnableRetry
service实现类添加@Retryable注解
@Override
可以看到代码里面,实现方法上面加上了注解 @Retryable,@Retryable有以下参数可以配置:
| value | 抛出指定异常才会重试; |
| include | 和value一样,默认为空,当exclude也为空时,默认所有异常; |
| exclude | 指定不处理的异常; |
| maxAttempts | 最大重试次数,默认3次; |
| backoff | 重试等待策略,默认使用@Backoff,@Backoff的value默认为1000(单位毫秒); |
| multiplier | 指定延迟倍数)默认为0,表示固定暂停1秒后进行重试,如果把multiplier设置为1.5,则第一次重试为2秒,第二次为3秒,第三次为4.5秒; |
Spring-Retry还提供了@Recover注解,用于@Retryable重试失败后处理方法。如果不需要回调方法,可以直接不写回调方法,那么实现的效果是,重试次数完了后,如果还是没成功没符合业务判断,就抛出异常。可以看到传参里面写的是 BizException e,这个是作为回调的接头暗号(重试次数用完了,还是失败,我们抛出这个BizException e通知触发这个回调方法)。
注意事项:
-
@Recover注解来开启重试失败后调用的方法,此注解注释的方法参数一定要是@Retryable抛出的异常,否则无法识别。
-
@Recover标注的方法的返回值必须与@Retryable标注的方法一致。
-
该回调方法与重试方法写在同一个实现类里面。
-
由于是基于AOP实现,所以不支持类里自调用方法。
-
方法内不能使用try catch,只能往外抛异常,而且异常必须是Throwable类型的。
原理
Spring-retyr调用时序图 :
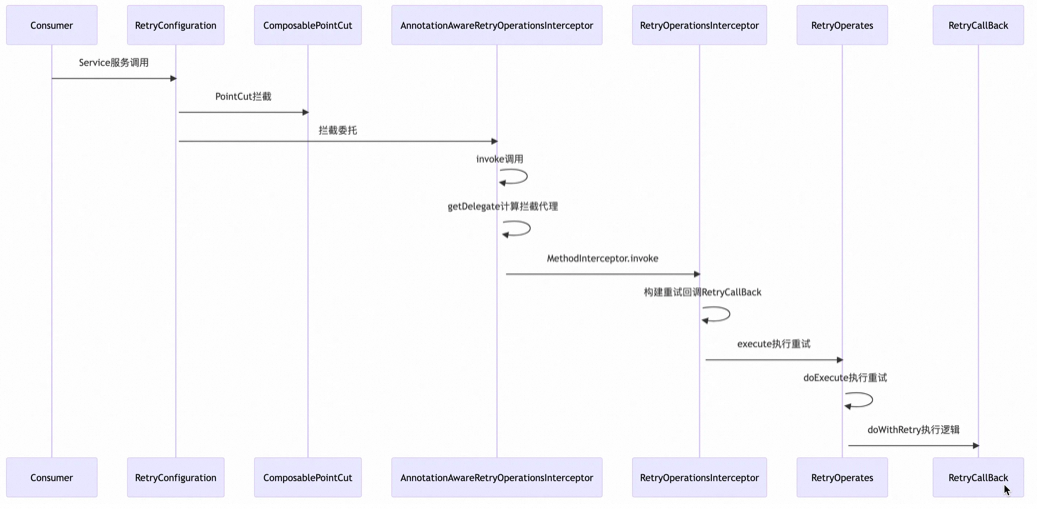
Spring Retry 的基本原理是通过 @EnableRetry 注解引入 AOP 能力。在 Spring 容器启动时,会扫描所有带有 @Retryable 和 @CircuitBreaker(熔断器)注解的方法,并为其生成 PointCut 和 Advice。当发生方法调用时,Spring 会委托拦截器 RetryOperationsInterceptor 进行调用,拦截器内部实现了失败退避重试和降级恢复方法。这种设计模式使得重试逻辑的实现非常简单易懂,并且能够充分利用 Spring 框架提供的 AOP 能力,从而实现高效而优雅的重试机制。
缺陷
尽管 Spring Retry 工具能够优雅地实现重试,但它仍然存在两个不太友好的设计:
首先,重试实体被限定为 Throwable 子类,这意味着重试针对的是可捕获的功能异常,但实际上我们可能希望依赖某个数据对象实体作为重试实体,但是 Spring Retry 框架必须强制将其转换为 Throwable 子类。
其次,重试根源的断言对象使用的是 doWithRetry 的 Exception 异常实例,这不符合正常内部断言的返回设计。
Spring Retry 建议使用注解来对方法进行重试,重试逻辑是同步执行的。重试的“失败”是指 Throwable 异常,如果你要通过返回值的某个状态来判断是否需要重试,则可能需要自己判断返回值并手动抛出异常。
2.6 Guava Retrying
Guava Retrying 是基于 Google 的核心类库 Guava 的重试机制实现的一个库,它提供了一种通用方法,可以使用 Guava 谓词匹配增强的特定停止、重试和异常处理功能来重试任意 Java 代码。这个库支持多种重试策略,比如指定重试次数、指定重试时间间隔等。此外,它还支持谓词匹配来确定是否应该重试,以及在重试时应该做些什么。Guava Retrying 的最大特点是它能够灵活地与其他 Guava 类库集成,这使得它非常易于使用。
POM依赖
<dependency>
测试demo
public static void main(String[] args) {
当发生重试之后,假如我们需要做一些额外的处理动作,比如发个告警邮件啥的,那么可以使用RetryListener。每次重试之后,guava-retrying会自动回调我们注册的监听。可以注册多个RetryListener,会按照注册顺序依次调用。
public class MyRetryListener implements RetryListener {
RetryerBuilder是一个factory创建者,可以定制设置重试源且可以支持多个重试源,可以配置重试次数或重试超时时间,以及可以配置等待时间间隔,创建重试者Retryer实例。
RetryerBuilder的重试源支持Exception异常对象 和自定义断言对象,通过retryIfException 和retryIfResult设置,同时支持多个且能兼容。
-
retryIfException,抛出runtime异常、checked异常时都会重试,但是抛出error不会重试。
-
retryIfRuntimeException只会在抛runtime异常的时候才重试,checked异常和error都不重试。
-
retryIfExceptionOfType允许我们只在发生特定异常的时候才重试,比如NullPointerException和IllegalStateException都属于runtime异常,也包括自定义的error。
-
retryIfResult可以指定你的Callable方法在返回值的时候进行重试。
StopStrategy:停止重试策略,提供以下方式:
| StopAfterDelayStrategy | 设定一个最长允许的执行时间;比如设定最长执行10s,无论任务执行次数,只要重试的时候超出了最长时间,则任务终止,并返回重试异常 |
| NeverStopStrategy | 用于需要一直轮训知道返回期望结果的情况。 |
| StopAfterAttemptStrategy | 设定最大重试次数,如果超出最大重试次数则停止重试,并返回重试异常。 |
| WaitStrategy | 等待时长策略(控制时间间隔) |
| FixedWaitStrategy | 固定等待时长策略。 |
| RandomWaitStrategy | 随机等待时长策略(可以提供一个最小和最大时长,等待时长为其区间随机值)。 |
| IncrementingWaitStrategy | 递增等待时长策略(提供一个初始值和步长,等待时间随重试次数增加而增加)。 |
| ExponentialWaitStrategy | 指数等待时长策略 |
| FibonacciWaitStrategy | 等待时长策略 |
| ExceptionWaitStrategy | 异常时长等待策略 |
| CompositeWaitStrategy | 复合时长等待策略 |
优势
Guava Retryer 工具与 Spring Retry 类似,都是通过定义重试者角色来包装正常逻辑重试。然而,Guava Retryer 在策略定义方面更优秀。它不仅支持设置重试次数和重试频度控制,还能够兼容多个异常或自定义实体对象的重试源定义,从而提供更多的灵活性。这使得 Guava Retryer 能够适用于更多的业务场景,比如网络请求、数据库访问等。此外,Guava Retryer 还具有很好的可扩展性,可以很方便地与其他 Guava 类库集成使用。
三、优雅重试共性和原理
Spring Retry 和 Guava Retryer 工具都是线程安全的重试工具,它们能够支持并发业务场景下的重试逻辑,并保证重试的正确性。这些工具可以设置重试间隔时间、差异化的重试策略和重试超时时间,进一步提高了重试的有效性和流程的稳定性。
同时,Spring Retry 和 Guava Retryer 都使用了命令设计模式,通过委托重试对象来完成相应的逻辑操作,并在内部实现了重试逻辑的封装。这种设计模式使得重试逻辑的扩展和修改变得非常容易,同时也增强了代码的可重用性。
四、总结
在某些功能逻辑中,存在不稳定依赖的场景,这时我们需要使用重试机制来获取预期结果或尝试重新执行逻辑而不立即结束。比如在远程接口访问、数据加载访问、数据上传校验等场景中,都可能需要使用重试机制。
不同的异常场景需要采用不同的重试方式,同时,我们应该尽可能将正常逻辑和重试逻辑解耦。在设置重试策略时,我们需要根据实际情况考虑一些问题。比如,我们需要考虑什么时机进行重试比较合适?是否应该同步阻塞重试还是异步延迟请重试?是否具备一键快速失败的能力?另外,我们需要考虑失败不重试会不会严重影响用户体验。在设置超时时间、重试策略、重试场景和重试次数时,我们也需要慎重考虑以上问题。
本文只讲解了重试机制的一小部分,我们在实际应用时要根据实际情况采用合适的失败重试方案。
参考文档:
Guava-Retrying实现重试机制:https://blog.csdn.net/dxh0823/article/details/80850367
面向失败编程之重试:https://ata.alibaba-inc.com/articles/225831?spm=ata.23639746.0.0.5b38767334nFCk
Springboot-Retry组件@Recover失效问题解决:https://blog.csdn.net/zhiweihongyan1/article/details/121630529
Spring Boot 一个注解,优雅的实现重试机制:https://mp.weixin.qq.com/s/hDRUh0KBV9mA0Nd33qJo7g
图文并茂:一文带你探索HSF的实现原理:https://ata.alibaba-inc.com/articles/181123
自动重试:HSF/Spring-retry/Resilience4j/自研小工具:https://ata.alibaba-inc.com/articles/257389?spm=ata.23639746.0.0.5b38767334nFCk#eqscrU0J
Spring Retry 是 Spring 系列中的一个子项目,它提供了声明式的重试支持,可以帮助我们以标准化的方式处理任何特定操作的重试。这个框架非常适合于需要进行重试的业务场景,比如网络请求、数据库访问等。使用 Spring Retry,我们可以使用注解来设置重试策略,而不需要编写冗长的代码。所有的配置都是基于注解的,这使得使用 Spring Retry 变得非常简单和直观。
POM依赖
org.springframework.retry
spring-retry
org.springframework
spring-aspects
启用@Retryable
引入spring-retry jar包后在spring boot的启动类上打上@EnableRetry注解。
@EnableRetry
@SpringBootApplication(scanBasePackages = {“me.ele.camp”},excludeName = {“me.ele.oc.orm.OcOrmAutoConfiguraion”})
@ImportResource({“classpath*:sentinel-tracer.xml”})
public class Application {
public static void main(String[] args) {System.setProperty("APPID","alsc-info-local-camp");System.setProperty("project.name","alsc-info-local-camp");
}
service实现类添加@Retryable注解
@Override
@Retryable(value = BizException.class, maxAttempts = 6)
public Integer retryableTest(Integer code) {
System.out.println(“retryableTest,时间:” + LocalTime.now());
if (code == 0) {
throw new BizException(“异常”, “异常”);
}
BaseResponse objectBaseResponse = ResponseHandler.serviceFailure(ResponseErrorEnum.UPDATE_COMMENT_FAILURE);
System.out.println("retryableTest,正确!");return 200;}@Recover
public Integer recover(BizException e) {System.out.println("回调方法执行!!!!");//记日志到数据库 或者调用其余的方法return 404;};
可以看到代码里面,实现方法上面加上了注解 @Retryable,@Retryable有以下参数可以配置:
value
抛出指定异常才会重试;
include
和value一样,默认为空,当exclude也为空时,默认所有异常;
exclude
指定不处理的异常;
maxAttempts
最大重试次数,默认3次;
backoff
重试等待策略,默认使用@Backoff,@Backoff的value默认为1000(单位毫秒);
multiplier
指定延迟倍数)默认为0,表示固定暂停1秒后进行重试,如果把multiplier设置为1.5,则第一次重试为2秒,第二次为3秒,第三次为4.5秒;
Spring-Retry还提供了@Recover注解,用于@Retryable重试失败后处理方法。如果不需要回调方法,可以直接不写回调方法,那么实现的效果是,重试次数完了后,如果还是没成功没符合业务判断,就抛出异常。可以看到传参里面写的是 BizException e,这个是作为回调的接头暗号(重试次数用完了,还是失败,我们抛出这个BizException e通知触发这个回调方法)。
注意事项:
@Recover注解来开启重试失败后调用的方法,此注解注释的方法参数一定要是@Retryable抛出的异常,否则无法识别。
@Recover标注的方法的返回值必须与@Retryable标注的方法一致。
该回调方法与重试方法写在同一个实现类里面。
由于是基于AOP实现,所以不支持类里自调用方法。
方法内不能使用try catch,只能往外抛异常,而且异常必须是Throwable类型的。
原理
Spring-retyr调用时序图 :
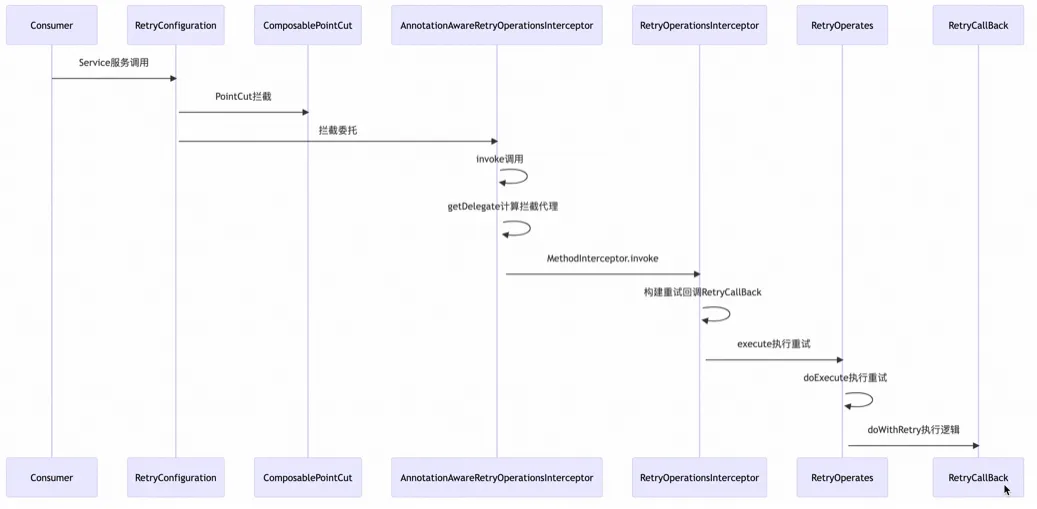
图片
Spring Retry 的基本原理是通过 @EnableRetry 注解引入 AOP 能力。在 Spring 容器启动时,会扫描所有带有 @Retryable 和 @CircuitBreaker(熔断器)注解的方法,并为其生成 PointCut 和 Advice。当发生方法调用时,Spring 会委托拦截器 RetryOperationsInterceptor 进行调用,拦截器内部实现了失败退避重试和降级恢复方法。这种设计模式使得重试逻辑的实现非常简单易懂,并且能够充分利用 Spring 框架提供的 AOP 能力,从而实现高效而优雅的重试机制。
缺陷
尽管 Spring Retry 工具能够优雅地实现重试,但它仍然存在两个不太友好的设计:
首先,重试实体被限定为 Throwable 子类,这意味着重试针对的是可捕获的功能异常,但实际上我们可能希望依赖某个数据对象实体作为重试实体,但是 Spring Retry 框架必须强制将其转换为 Throwable 子类。
其次,重试根源的断言对象使用的是 doWithRetry 的 Exception 异常实例,这不符合正常内部断言的返回设计。
Spring Retry 建议使用注解来对方法进行重试,重试逻辑是同步执行的。重试的“失败”是指 Throwable 异常,如果你要通过返回值的某个状态来判断是否需要重试,则可能需要自己判断返回值并手动抛出异常。
2.6 Guava Retrying
Guava Retrying 是基于 Google 的核心类库 Guava 的重试机制实现的一个库,它提供了一种通用方法,可以使用 Guava 谓词匹配增强的特定停止、重试和异常处理功能来重试任意 Java 代码。这个库支持多种重试策略,比如指定重试次数、指定重试时间间隔等。此外,它还支持谓词匹配来确定是否应该重试,以及在重试时应该做些什么。Guava Retrying 的最大特点是它能够灵活地与其他 Guava 类库集成,这使得它非常易于使用。
POM依赖
com.github.rholder
guava-retrying
2.0.0
测试demo
public static void main(String[] args) {
Callable callable = new Callable() {
@Override
public Boolean call() throws Exception {
// do something useful here
log.info(“call…”);
throw new RuntimeException();
}
};
Retryer<Boolean> retryer = RetryerBuilder.<Boolean>newBuilder()//retryIf 重试条件.retryIfException().retryIfRuntimeException().retryIfExceptionOfType(Exception.class).retryIfException(Predicates.equalTo(new Exception())).retryIfResult(Predicates.equalTo(false))//等待策略:每次请求间隔1s.withWaitStrategy(WaitStrategies.fixedWait(1, TimeUnit.SECONDS))//停止策略 : 尝试请求6次.withStopStrategy(StopStrategies.stopAfterAttempt(6))//时间限制 : 某次请求不得超过2s .withAttemptTimeLimiter(AttemptTimeLimiters.fixedTimeLimit(2, TimeUnit.SECONDS))//注册一个自定义监听器(可以实现失败后的兜底方法).withRetryListener(new MyRetryListener()).build();try {retryer.call(callable);} catch (Exception ee) {ee.printStackTrace();}
}
当发生重试之后,假如我们需要做一些额外的处理动作,比如发个告警邮件啥的,那么可以使用RetryListener。每次重试之后,guava-retrying会自动回调我们注册的监听。可以注册多个RetryListener,会按照注册顺序依次调用。
public class MyRetryListener implements RetryListener {
@Override
public void onRetry(Attempt attempt) {
// 第几次重试
System.out.print(“[retry]time=” + attempt.getAttemptNumber());
// 距离第一次重试的延迟
System.out.print(“,delay=” + attempt.getDelaySinceFirstAttempt());
// 重试结果: 是异常终止, 还是正常返回System.out.print(",hasException=" + attempt.hasException());System.out.print(",hasResult=" + attempt.hasResult());// 是什么原因导致异常if (attempt.hasException()) {System.out.print(",causeBy=" + attempt.getExceptionCause().toString());// do something useful here} else {// 正常返回时的结果System.out.print(",result=" + attempt.getResult());}System.out.println();
}
}
RetryerBuilder是一个factory创建者,可以定制设置重试源且可以支持多个重试源,可以配置重试次数或重试超时时间,以及可以配置等待时间间隔,创建重试者Retryer实例。
RetryerBuilder的重试源支持Exception异常对象 和自定义断言对象,通过retryIfException 和retryIfResult设置,同时支持多个且能兼容。
retryIfException,抛出runtime异常、checked异常时都会重试,但是抛出error不会重试。
retryIfRuntimeException只会在抛runtime异常的时候才重试,checked异常和error都不重试。
retryIfExceptionOfType允许我们只在发生特定异常的时候才重试,比如NullPointerException和IllegalStateException都属于runtime异常,也包括自定义的error。
retryIfResult可以指定你的Callable方法在返回值的时候进行重试。
StopStrategy:停止重试策略,提供以下方式:
StopAfterDelayStrategy
设定一个最长允许的执行时间;比如设定最长执行10s,无论任务执行次数,只要重试的时候超出了最长时间,则任务终止,并返回重试异常
NeverStopStrategy
用于需要一直轮训知道返回期望结果的情况。
StopAfterAttemptStrategy
设定最大重试次数,如果超出最大重试次数则停止重试,并返回重试异常。
WaitStrategy
等待时长策略(控制时间间隔)
FixedWaitStrategy
固定等待时长策略。
RandomWaitStrategy
随机等待时长策略(可以提供一个最小和最大时长,等待时长为其区间随机值)。
IncrementingWaitStrategy
递增等待时长策略(提供一个初始值和步长,等待时间随重试次数增加而增加)。
ExponentialWaitStrategy
指数等待时长策略
FibonacciWaitStrategy
等待时长策略
ExceptionWaitStrategy
异常时长等待策略
CompositeWaitStrategy
复合时长等待策略
优势
Guava Retryer 工具与 Spring Retry 类似,都是通过定义重试者角色来包装正常逻辑重试。然而,Guava Retryer 在策略定义方面更优秀。它不仅支持设置重试次数和重试频度控制,还能够兼容多个异常或自定义实体对象的重试源定义,从而提供更多的灵活性。这使得 Guava Retryer 能够适用于更多的业务场景,比如网络请求、数据库访问等。此外,Guava Retryer 还具有很好的可扩展性,可以很方便地与其他 Guava 类库集成使用。
三、优雅重试共性和原理
Spring Retry 和 Guava Retryer 工具都是线程安全的重试工具,它们能够支持并发业务场景下的重试逻辑,并保证重试的正确性。这些工具可以设置重试间隔时间、差异化的重试策略和重试超时时间,进一步提高了重试的有效性和流程的稳定性。
同时,Spring Retry 和 Guava Retryer 都使用了命令设计模式,通过委托重试对象来完成相应的逻辑操作,并在内部实现了重试逻辑的封装。这种设计模式使得重试逻辑的扩展和修改变得非常容易,同时也增强了代码的可重用性。
四、总结
在某些功能逻辑中,存在不稳定依赖的场景,这时我们需要使用重试机制来获取预期结果或尝试重新执行逻辑而不立即结束。比如在远程接口访问、数据加载访问、数据上传校验等场景中,都可能需要使用重试机制。
不同的异常场景需要采用不同的重试方式,同时,我们应该尽可能将正常逻辑和重试逻辑解耦。在设置重试策略时,我们需要根据实际情况考虑一些问题。比如,我们需要考虑什么时机进行重试比较合适?是否应该同步阻塞重试还是异步延迟请重试?是否具备一键快速失败的能力?另外,我们需要考虑失败不重试会不会严重影响用户体验。在设置超时时间、重试策略、重试场景和重试次数时,我们也需要慎重考虑以上问题。
本文只讲解了重试机制的一小部分,我们在实际应用时要根据实际情况采用合适的失败重试方案。
参考文档:
Guava-Retrying实现重试机制:https://blog.csdn.net/dxh0823/article/details/80850367
面向失败编程之重试:https://ata.alibaba-inc.com/articles/225831?spm=ata.23639746.0.0.5b38767334nFCk
Springboot-Retry组件@Recover失效问题解决:https://blog.csdn.net/zhiweihongyan1/article/details/121630529
Spring Boot 一个注解,优雅的实现重试机制:https://mp.weixin.qq.com/s/hDRUh0KBV9mA0Nd33qJo7g
图文并茂:一文带你探索HSF的实现原理:https://ata.alibaba-inc.com/articles/181123
自动重试:HSF/Spring-retry/Resilience4j/自研小工具:https://ata.alibaba-inc.com/articles/257389?spm=ata.23639746.0.0.5b38767334nFCk#eqscrU0J
参与话题讨论赢礼品
这篇关于技术积累1:Java容错机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







