本文主要是介绍分布式共识算法(故障容错算法)系列整理(三):Paxos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
五篇分布式共识系列文章合集:
分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos
分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR
分布式共识算法(故障容错算法)系列整理(三):Paxos
分布式共识算法(故障容错算法)系列整理(四):Raft
分布式共识算法(故障容错算法)系列整理(五):ZAB
Basic Paxos
Baxos 解决的问题
- 在多个并发节点中,保证三个节点存储的日志顺序一样
复制状态机的原理是什么
- 状态机的原理是:一样的初始状态+一样的输入事件=一样的最终状态。因此,要保证多个Node的状态完全一致,只要保证多个Node的日志流是一样的即可。即使这个Node宕机,只需重启和重放日志流,就能恢复之前的状态
三种角色
- 提议者(Proposer):提议一个值用于投票表决,可把客户端当成提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才是提议者。好处是对业务代码没有入侵性,即不需要再业务代码中实现算法逻辑,可像使用数据库一样访问后端数据。代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商
- 接受者(Acceptor):对每个提议的值进行投票,并存储接受的值。一般集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储保存
- 学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。通常学习者是数据备份节点,如「Master-Slave」模型中的Slave,被动地接受数据,容灾备份。代表存储数据,不参与共识协商,只接受达成共识的值,存储保存
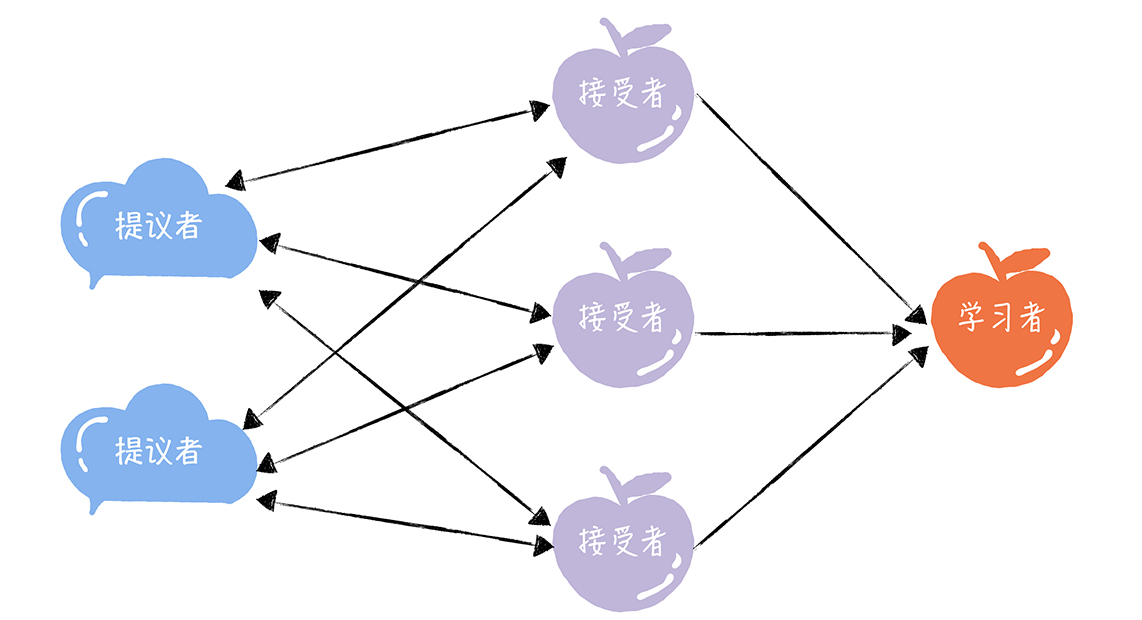
算法过程
- 每个接受者(Acceptor)需持久化三个变量
- minProposalId:接受的最小 minProposalId
- acceptProposalId:上一个接受的 ProposalId
- acceptValue:上一个接受的值
- 在初始阶段:minProposalId = acceptProposalId = 0, acceptValue = null
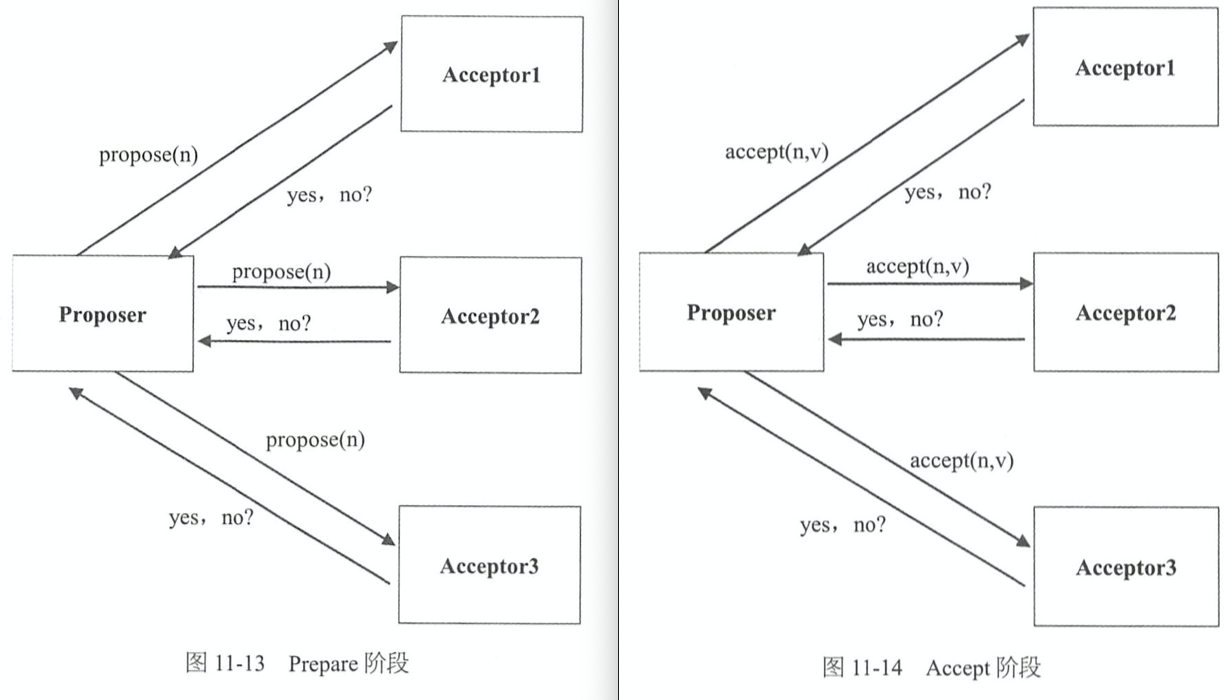
- P1:准备(Prepare)阶段
- P1a:提议者广播 prepare(n),其中 n 是本机生成的一个自增 ID,不需要全局有序,如可用时间戳+IP
- P1b:接受者收到 prepare(n),做决策
if n > minProposalId, 回复 yes。同时 minProposalId = n(持久化)返回(acceptProposalId, acceptValue) else回复 no- P1c
- 提议者如果收到半数以上的 yes,则取 acceptorProposalId 最大的acceptValue 作为 v,进入第二阶段,广播 accept(n, v)
- 如果 acceptor 返回的都是 null,则取自己的值作为 v,进入第二阶段
- 否则,n 自增,重复 P1a
- P2:接受(Accept)阶段
- P2a:提议者广播 accept(n, v)。这里的 n 就是 P1 阶段的 n,v 可能是自己的值,也可能是第 1 阶段的 acceptValue
- P2b:接受者收到 accept(n, v),做如下决策
if n >= minProposalId, 回复 yes。同时 minProposalId = acceptProposalId = n(持久化)acceptValue = value返回 minProposalId else回复 no- P2c:提议者如果收到半数以上的 yes,并且 minProposalId == n,则算法结束。否则,n 自增,重复 P1a
达成共识的过程举例
- 假设客户端 1 的提案编号为 1,客户端 2 的提案编号为 5,并假设节点 A、B 先收到来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求
- 准备(Prepare)阶段
- 客户端1、2作为提议者,分别向所有接受者发送包含提案编号的准备请求
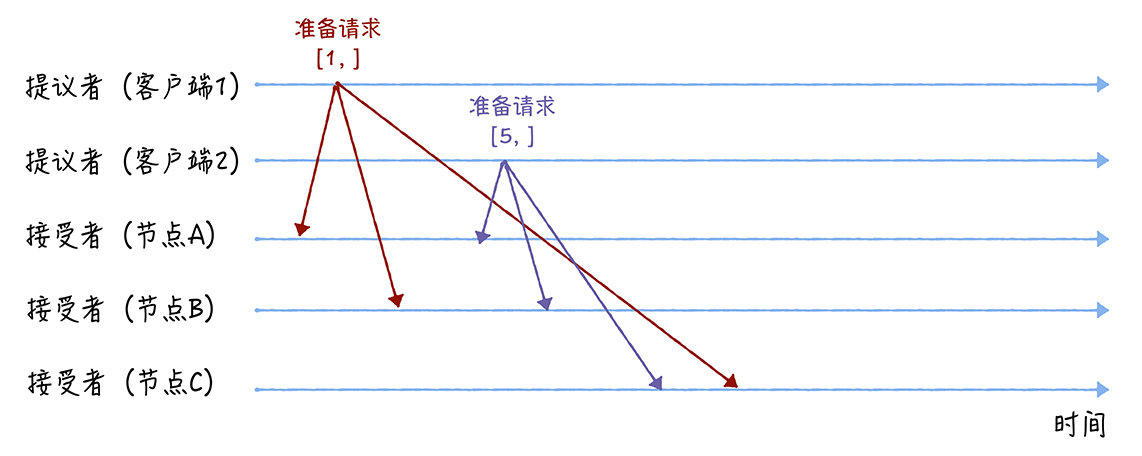
- 在准备请求中是不需要指定提议的值的,只需要携带提案编号即可
- 当节点A、B收到提案编号为1的准备请求,节点C收到提案编号为5的准备请求后,将这样处理:
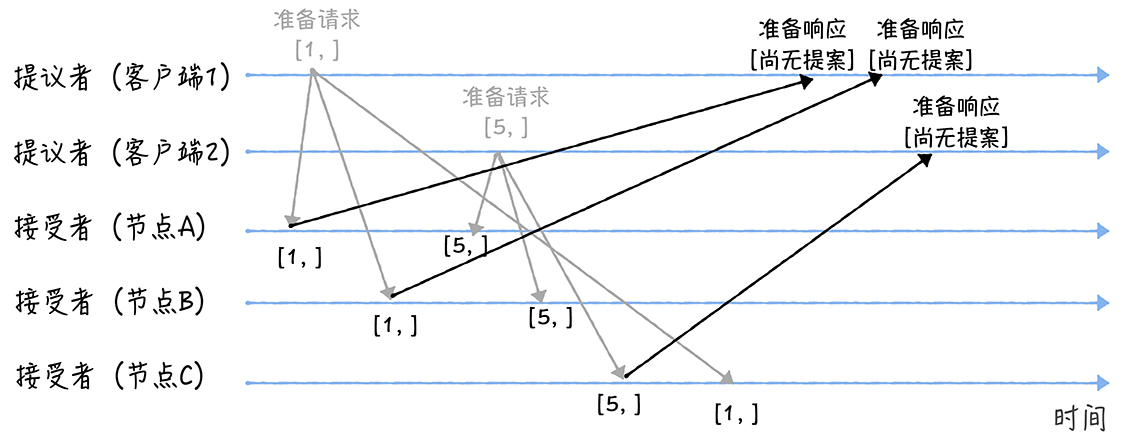
- 由于之前没有通过任何提案,所以结点A、B将返回一个「尚无提案」的相应,并以后不再响应提案编号小于等于1的准备请求,不会通过编号小于1的提案
- 结点C则返回「尚无提案」的响应并以后不再响应提案编号小于等于5的准备请求,不会通过编号小于5的提案
- 另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请求的时候,将这样处理:
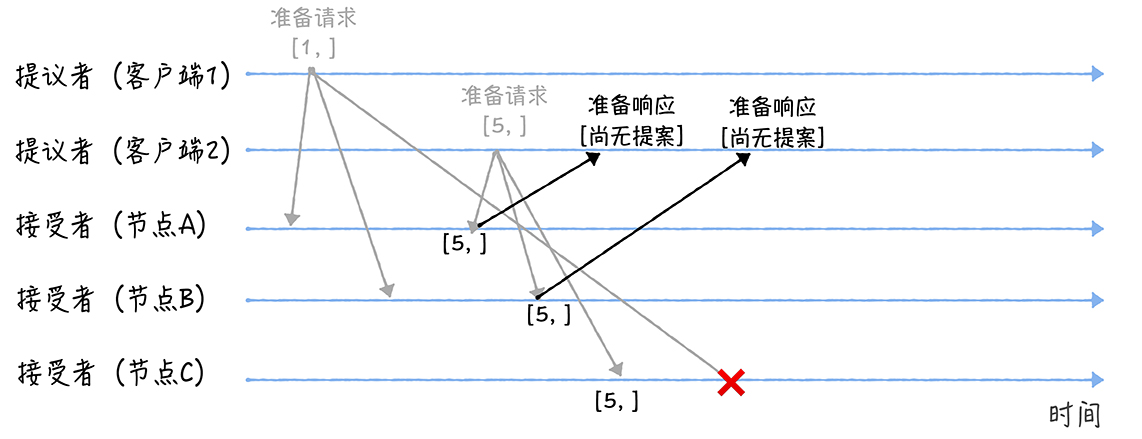
- 当节点A、B收到提案编号为5的准备请求的时候,因为提案编号5大于它们之前响应的准备请求的提案编号1,而且两个节点都没有通过诺任何提案,所以它将返回一个「尚无提案」的响应,并承诺以后不再响应提案编号小于等于5的准备请求,不会通过编号小于5的提案
- 当节点C收到提案编号为1的准备请求的时候,由于提案编号1小于它之前响应的准备请求的提案编号5,所以丢弃该准备请求,不做响应
- 接受(Accept)阶段
- 首先客户端1、2在收到大多数节点的准备响应之后,会分别发送接受请求:
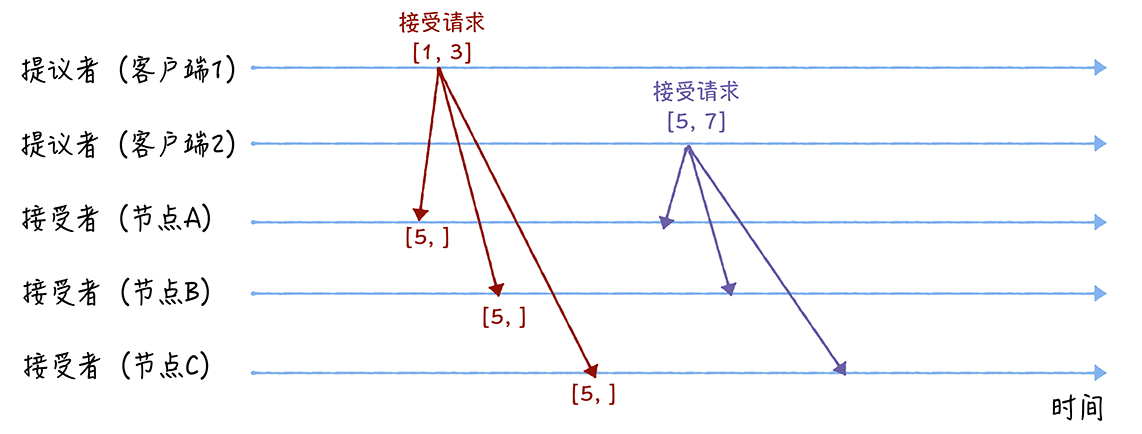
- 当客户端1收到大多数的接受者(节点A、B)的准备响应后,根据响应中提案编号最大的提案的值,设置接受请求中的值。因为该值在来自节点A、B的准备响应中都为空,所以就把自己的提议值3作为提案的值,发送接受请求[1, 3]
- 当客户端2收到大多数的接受者的准备响应后(节点A、B和节点C),根据响应中提案编号最大的提案的值,来设置接受请求中的值。因为该值来自节点A、B、C的准备响应中都为空,所以就把自己的提议值7作为提案的值,发送请求[5, 7]
- 当三个节点收到2 个客户端的接受请求时,会这样处理:
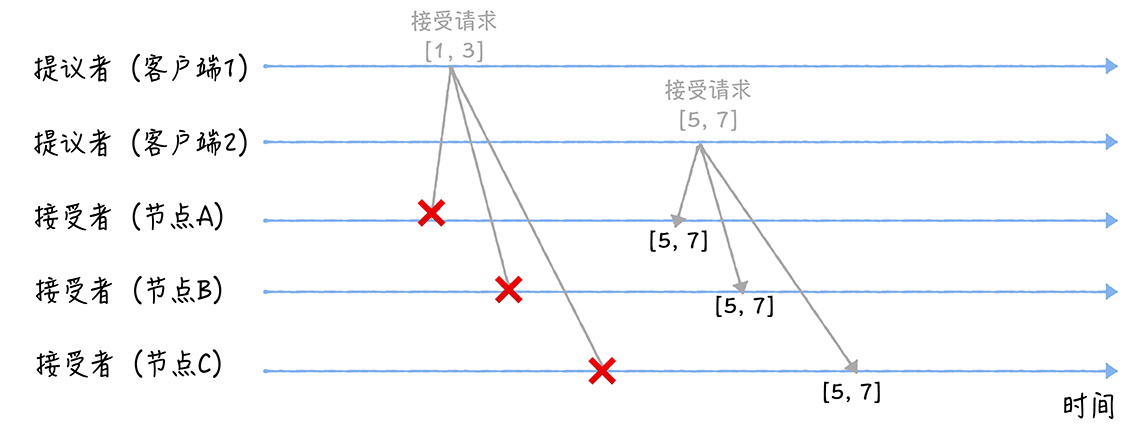
- 当节点A、B、C收到接受请求[1, 3]时,由于提案的提案编号1小于三个节点承诺能通过的提案的最小提案编号5,所以提案[1, 3]将被拒绝
- 当节点A、B、C收到接受请求[5, 7]的时候,由于提案的提案编号 5 不小于三个节点承诺能通过的提案的最小提案编号 5,所以就通过提案[5, 7],也就是接受了值 7,三个节点就 X 值为 7 达成了共识
- 如果集群中有学习者,当接受者通过了一个提案时,就通知给所有的学习者。当学习者发现大多数的接受者都通过了某个提案,那么它也通过该提案,接受该提案的值
- Basic Paxos的容错能力,源自「大多数」的约定,即当少于一半的节点出现故障的时候,共识协商仍然在正常工作
- 本质上而言,提案编号的大小代表着优先级,根据提案编号的大小, 接受者保证三个承诺
- 如果准备请求的提案编号,小于等于接受者已经响应的准备请求的提案编号,那么接受者将承诺不响应这个准备请求
- 如果接受请求中的提案的提案编号,小于接受者已经响应的准备请求的提案编号,那么接受者将承诺不通过这个提案
- 如果接受者之前有通过提案,那么接受者将承诺,会在准备请求的响应中,包含已经通过的最大编号的提案信息
Basic Paxos 的两个问题
- 活锁问题:Paxos 是一个「不断循环」的 2PC。在 P1C 或者 P2C 阶段,算法都可能失败,重新进行 P1a。如果多个客户端写多个机器,每个机器都是 Proposer,会导致并发冲突很高,极端情况是每个节点都在无限循环地执行 2PC
- 性能问题:每确定一个值,至少需要两次 RTT(两个阶段,两个网络来回)+两次写盘,性能也是个问题
Multi Paxos
Basic Paxos 活锁问题的解决
- 变多写为单写,选出一个 Leader,只让 Leader 充当 Proposer。其它机器收到写请求,都把写请求转发给 Leader,或者让客户端把写请求都发给 Leader
Leader 的两种选举方法
- 方案 1:无租约的Leader选举
- 1.每个节点都有一个编号,选取编号最大的节点为 Leader
- 2.每个节点周期性地向其它节点发送心跳,假设周期为 T ms
- 3.如果一个节点在最近的 2 T ms 内还没有收到比自己编号更大的节点发来的心跳,则自己变为 Leader
- 4.如果一个节点不是 Leader,则收到请求之后转发给 Leader
- 可以看出,这个算法很简单,但因为网络超时原因,很可能出现多个Leader,但这并不影响MultiPaxos协议的正确性,只是增大并发写冲突的概率。我们的算法并不需要强制保证,任意时刻只能有一个Leader
- 方案 2:有租约的Leader选举
- 严格保证任意时刻只能有一个 Leader,即「租约」,意思是在一个限定的期限内,某台机器一直是 Leader。 即使这个机器宕机,Leader 也不能切换。必须等到租期到期之后,才能开始选举新的Leader。这种方式会带来短暂的不可用,但保证了任意时刻只会有一个Leader。具体实现方式可以参见PaxosLease
Basic Paxos 的性能问题解决
- 原理
- Multi Paxos 选出 Leader 之后,可以把 2PC 优化成 1PC,即一个 RTT+一次落盘了
- 思路
- 当一个节点被确认为 Leader 之后,先广播一次 Prepare,一旦超过半数同意,之后对于收到的每条日志直接执行 Accept 操作。这里的 Prepare 不再是对一条日志的控制了,而是相当于拿到了整个日志的控制权。一旦这个 Leader 拿到了整个日志的控制权后,后面就直接略过 Prepare,直接执行 Accept
- 新的 Leader 出现怎么办?
- 新的 Leader 肯定会发起 Prepare,导致 minProposalId 变大,这时旧的 Leader 的广播 Accept 肯定会失败,旧的 Leader 会自己转变成普通的接受者,新 Leader 就把旧 Leader 顶替掉了
- 代码实现
- 所以 Multi Paxos 中,增加一个日志的 index 参数,代表当前传的是第 index 个日志
prepare(n, index)accept(n, v, index)
被 choose 的日志,状态如何同步给其它机器
- 问题描述
- 对于一条日志,当提议者 (也就是Leader)接收到多数派对Accept请求的同意后,就知道这条日志被“choose” 了,也就是被确认了,不能再更改!
- 但只有Proposer 知道这条日志被确认了,其他的Acceptor并不知道这条日志被确认了。如何把这个信息传递给其他Accepotor呢?
- 方案 1:提议者主动通知
- 给 accept 再增加一个参数:
accept(n, v, index, firstUnchoosenIndex) - Proposer 在广播 accept 的时候,额外带来一个参数 firstUnchosenIndex = 7。意思是 7 之前的日志都已经 “choose” 了
- 给 accept 再增加一个参数:
- 方案 2:接受者被动查询
- 当一个Aceptor被选为Leader后,对于所有未确认的日志,可以逐个再执行一遍Paxos,来判断该条日志被多数派确认的值是多少。
- 因为Basic Paxos有一个核心特性: 一旦一个值被确定后,无论再执行多少遍Paxos,该值都不会改变!因此,再执行1遍Paxos,相当于向集群发起了一次查询!
参考
- 分布式协议与算法实战-极客时间
- 分布式技术原理与算法解析-极客时间
- 软件架构设计 大型网站技术架构与业务架构融合之道
这篇关于分布式共识算法(故障容错算法)系列整理(三):Paxos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






