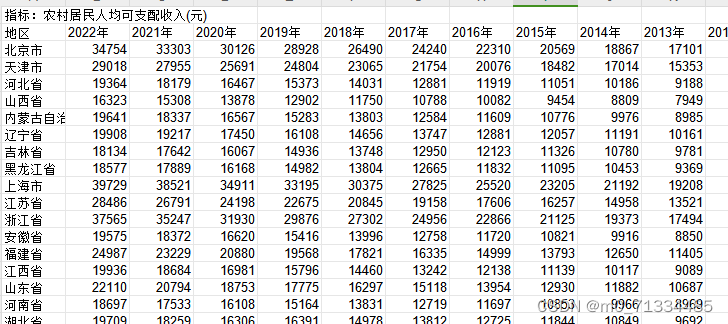
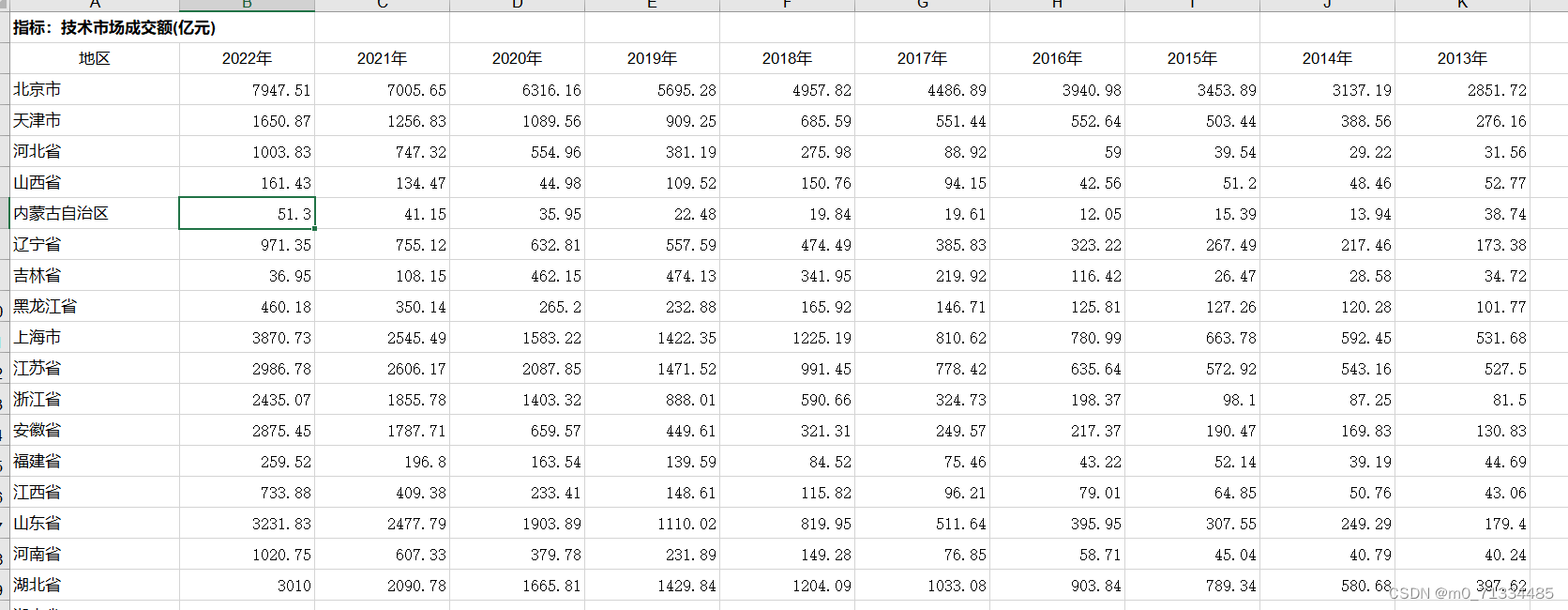
本文主要是介绍The Agree Predictor(1997),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
旨在减少分支干扰/别名/混叠。
以前减少干扰的三种方法:(1)增大预测器大小;(2)选取一种更有效利用PHT项的索引方法(如gshare);(3)分离不同类别的分支,对其使用不同的预测方案,从而避免发生干扰。
上述三种方法都侧重于减少整体干扰以减少负面干扰,agree预测器不同于上述方法,而是试图将负面干扰转换为其他干扰。
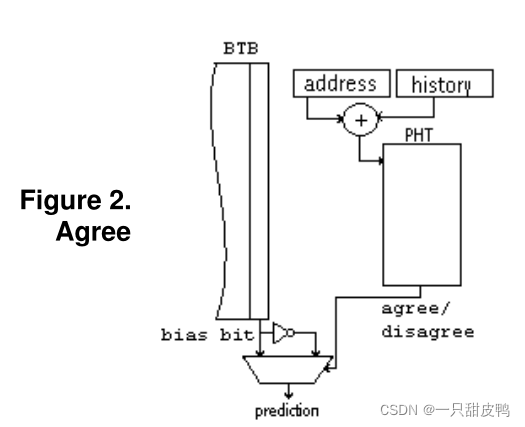
在agree预测器中,我们向每个分支(例如,在指令缓存或BTB中)附加一个偏置位,以预测分支最可能的结果。对于每个分支,在首次执行写入BTB时,在BTB中设置偏置位为分支执行方向。相应的,PHT表项信息由“跳转/不跳转”更改为“同意/不同意”偏置位的预测。2位计数器不是预测给定分支的方向,而是预测分支是否会朝偏置位指示的方向移动。实际上,该方案预测分支的方向是否与偏置位一致。在agree方案中,如果分支方向与偏置位一致,计数器将增加。如果分支与偏置位不一致,计数器将递减。
在这种策略下,如果偏置位选择得当,理想情况下当两个分支映射到同一PHT表项时,这两个分支在PHT表项中的状态也很可能是相同的:同意偏置方向。从而将破坏性别名转换为中性别名,即仍然产生了别名效应但不会造成错误预测。
缺点:但实际上并非所有分支首次执行方向就是其偏向方向,而在这种情况下,偏置位会保持不变直到BTB中的分支被替换,该分支的“不同意”信息会污染PHT。
这篇关于The Agree Predictor(1997)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!