本文主要是介绍MFA-Conformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

基于多尺度特征聚合Conformer说话人识别模型的创新与应用
论文:https://arxiv.org/abs/2203.15249
代码:GitHub - zyzisyz/mfa_conformer
收录于 INTERSPEECH 2022
1. 简介
本文由清华大学与腾讯科技(北京)有限公司、台湾大学及香港中文大学合作。提出了一种基于Conformer的多尺度特征融合的说话人识别模型(MFA-Conformer),通过融合各层不同尺度的特征,增强说话人特征的表征能力。实验表明,与目前主流的声纹识别网络ECAPA-TDNN相比,本文所提出的MFA-Conformer在识别性能和推理速度上都有大幅提升。该工作在腾讯科技有限公司的合作业务部门落地上线,新模型上线后实现了业务准确率20-40个点的巨大提升,节省线上服务资源30%。论文投稿半年收到12点谷歌学术引用。在工业和学术领域均产生了一定的影响力。
2. 背景动机
当前业内主流的说话人模型,如x-vector、r-vector、ECAPA-TDNN等,主要基于卷积神经网络构建。卷积神经网络可以很好地建模语音信号中局部特征(如pronunciation pattern),但很难有效建模语音的长程时序关系。与此相反,RNN/LSTM或者Transformer等时序模型可以有效捕捉到上下文信息,但较难学习到丰富的局部信息。因此,如何更好地实现局部特征和全局上下文信息统一建模,是当前声纹识别领域的研究热点之一。
3. 贡献
本文探索了端到端语音识别领域最主流的网络结构Conformer在声纹识别任务中的应用,提出了一种基于Conformer的多尺度特征融合的说话人识别模型(Multi-scale Feature Aggregation Conformer, MFA-Conformer)。
MFA-Conformer的设计受端到端语音识别网络Conformer和说话人识别网络ECAPA-TDNN的启发:其首先使用一个卷积降采样模块对输入的声学特征进行降采样,从而降低模型运算量;随后使用多个不同的Conformer块进行局部特征和全局特征的学习;最后将不同Conformer块的输出进行拼接,并通过一个注意力统计池化层(Attentive Statistics Pooling)提取说话人表征。
所提出的模型在Voxceleb1-O、SITW.Dev、SITW.Eval三个主流的声纹测评集上分别取得0.64%、1.29%、1.63%的等错误率(Equal Error Rate, EER)。实验揭示,通过对音频信号进行局部建模和全局建模统一,可有效提取更鲁棒的说话人表征;与主流声纹识别网络ECAPA-TDNN相比,MFA-Conformer在识别性能和推理速度上都有大幅提升。
MFA-Conformer主要具有4点显著优势:
1. 代码迁移成本低。MFA-Conformer主要是在Conformer的基础上进行简单修改,可复用已有成熟的端到端语音识别代码。只需进行简单适配,就可以实现快速迁移和部署,从而降低企业的研发成本。
2. 识别性能更好。在参数量接近的情况下,MFA-Conformer相比ECAPA-TDNN性能有明显优势,在短时测试场景下性能相对提升22%、在长时测试场景下性能相对提升32%。
3. 推理速度更快。与ECAPA-TDNN相比,MFA-Conformer的实时率(Real Time Factor,RTF)相对提升32.7%。并且可根据降采样率大小的不同进一步提升推理速度。
4. 后续可拓展性高。基于Conformer结构可以相对容易地快速实现联合语音识别、声纹识别、语种识别、情绪识别的多任务模型,从而可以更好地用于短视频、直播、在线会议等场景下的音频内容理解相关任务。
4. 解决方法
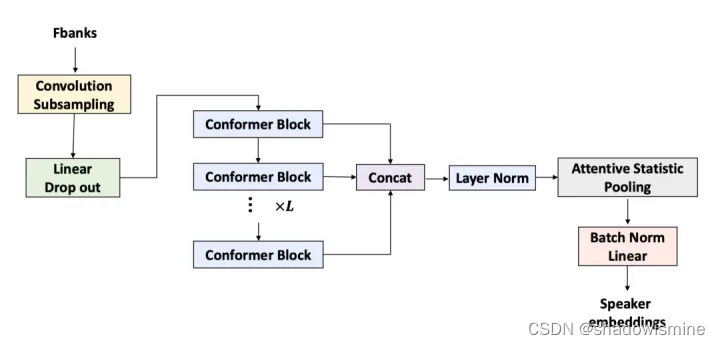
MFA-Conformer模型结构如上图所示,主要包括:(1)卷积将采样层 (Convolution Subsampling):由2维卷积组成,主要功能是对输入音频进行降采样,加速模型推理速度;(2)Conformer Block:进行局部特征和全局特征的学习;(3)注意力统计池化层(Attentive Statistics Pooling):将不同Conformer块之间的输出进行拼接,并通过通过注意力池化层为不同块的输出提供不同的权重,从而提取说话人表征。
4.1 Conformer
音频信号的局部特征和全局上下文信息在提取鲁棒的说话人表征中都起着至关重要的作用。为了更好地对局部特征和全局上下文信息进行统一建模,从而有效地提取更鲁棒的说话人表征,本文使用Conformer Block来达到该目的。
Conformer是谷歌提出的用于端到端语音识别任务的网络结构,其将卷积网络和Transformer模型进行结合,在Transformer的多头注意力(Multi-headed Self-attention, MHSA)层之后引入卷积模块,通过MHSA层捕捉全局上下文信息,通过卷积模块提取局部特征,从而更好地实现全局和局部特征的统一建模。相比于经典的Transformer,Conformer主要存在3点不同:(1)Conformer Block引入了卷积模块;(2)Conformer采用相对位置编码,Transformer采用绝对位置编码;(3)Conformer Block采用马卡龙(Macaron)结构,比Transformer多一个FFN(Feed Forward Network)模块。
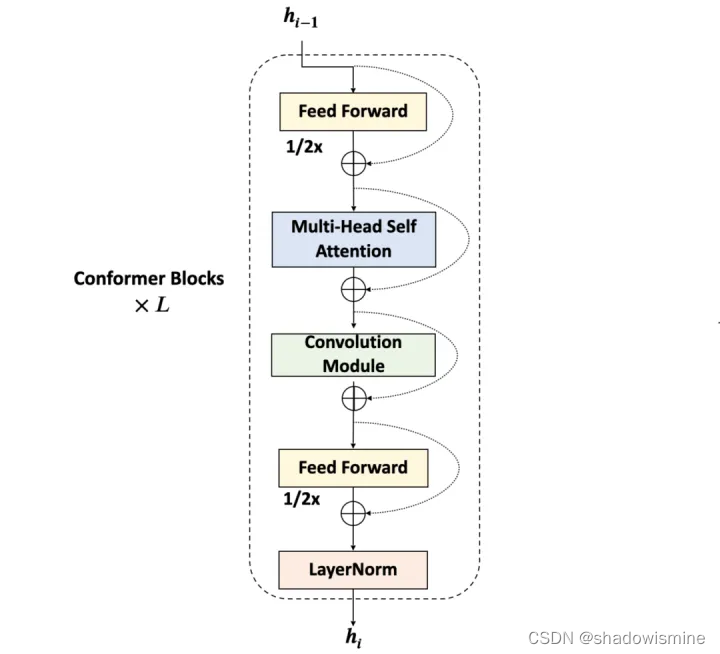
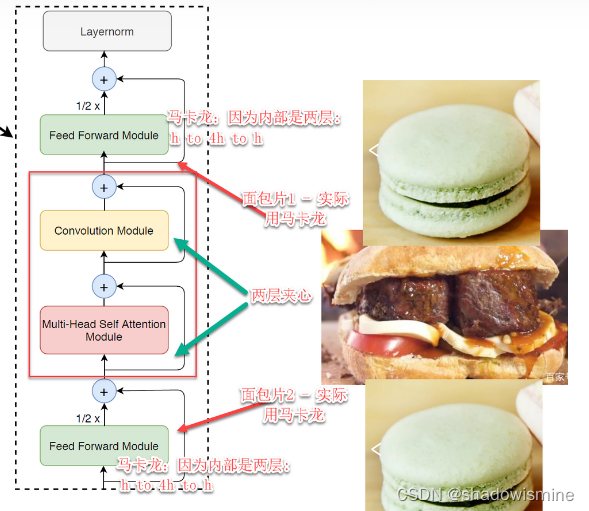
一个conformer block = conformer块,包括四个部分:
- feed-forward module,前向网络
- self-attention module,自注意力模块;
- 卷积模块
- 第二个feed-forward module。
4.1.1 multi-head self-attention module 多头自注意力模块
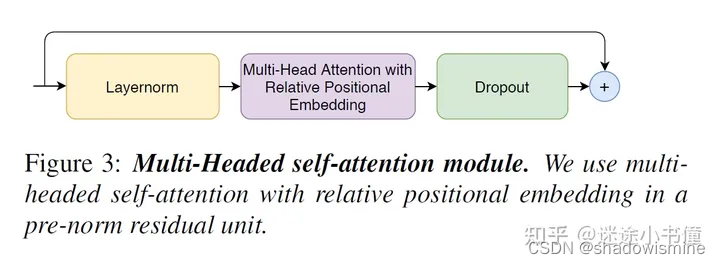
这里的模块,采用了relative sinusoidal positional encoding scheme,即相对位置的正弦编码方案。这个相对位置编码,可以让自注意力模块更好地对输入序列的长度进行泛化,从而让整个模块可以更好地应对输入wav的五花八门的长度。
vanilla Transformer中的绝对位置编码
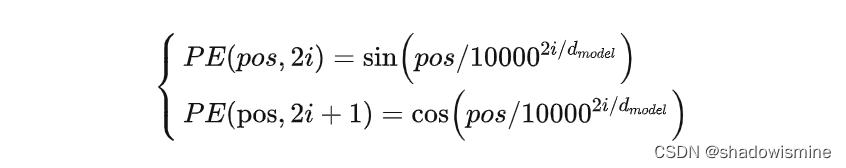
pos对应输入的位置,i这里在翻译上是维度。我在很多讨论该论文的帖子上看到,i有很多人有疑问,到底是指什么维度。在Vaswani的Attention is what you need论文中,是用上面的公式。举个例子,如pos=3,d(model)=128,那么3对应的位置向量如下
![]()
相对位置编码(NOT CLEAR)
相对位置由向量e(ij)表达,ij是指j相对于i的位置,当j与k的绝对值差大于k的时候,都用k代替(这样做的目的是保证效率,作者后来也发现k>2之后并没有明显的收益)。类似自注意力,相对位置向量e(ij)亦由ak(ij)和av(ij)两个向量经过对齐模型计算出。
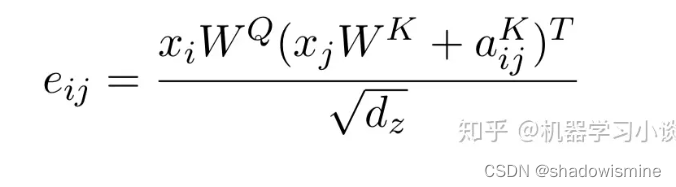
4.1.2 卷积模块

上图2给出的是卷积模块的细节。
一共包括了八个部分,和一个残差求和操作:
- layernorm
- pointwise conv
- glue activation
- 1d depthwise conv
- batchnorm
- swish activation
- pointwise conv
- dropout
- 残差residual 操作
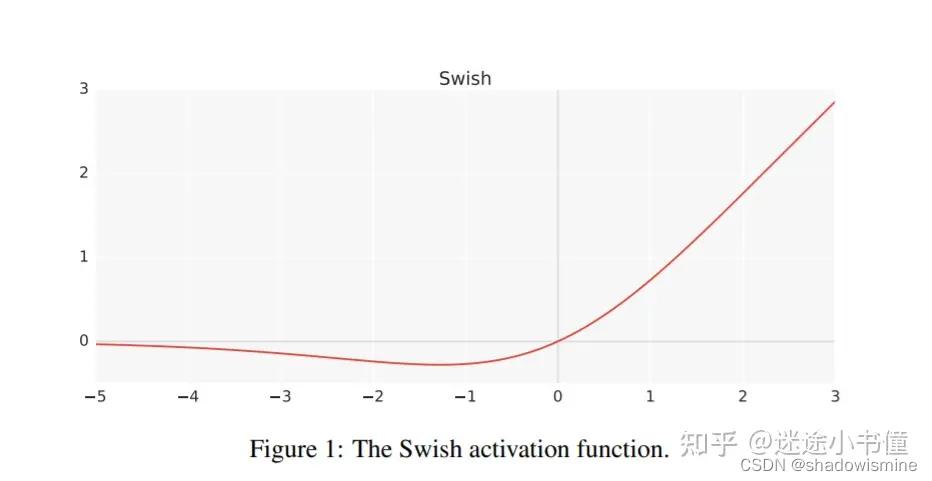
swish激活函数:

4.1.3 feed-forward模块

按照图中所示,其包括:
- layernorm
- linear layer,第一个线性层
- swish activation,非线性激活函数,
- dropout
- linear layer,第二个线性层
- dropout
- 残差求和操作
4.2 多尺度特征聚合 & 注意力统计池化层
现有说话人识别网络在做池化(Pooling)提取最终说话人表征时,大多数网络只将最后一层输出的特征(Feature Map)送给池化层。已有不少研究表明,低层网络输出的特征(Feature Map)对说话人表征的学习也是有帮助的。比如,目前主流的说话人识别模型ECAPA-TDNN,即利用了这一特点,将每个Res2Block的输出进行拼接后再送到池化层。
借鉴了这一思想,本文将所有Conformer Block输出的特征(Feature Map)进行拼接,随后使用注意力统计池化层(Attentive Statistics Pooling)为不同块的输出提供不同的权重,从而聚合形成最终的说话人表征。
5. 实验验证
所有模型均在Voxceleb1&2 dev上训练,在VoxCeleb1-O、SITW.Dev和SITW.Eval测试集上进行性能测试:其中SITW可以看作是长时场景,平均测试语音时长为35秒;VoxCeleb1-O可以看作是短时场景,平均测试语音时长为5秒。
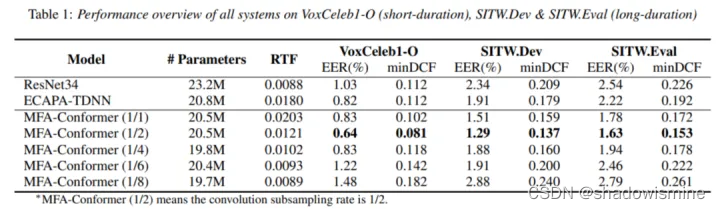
表格中MFA-Conformer(1/2)的意思表示输入的声学特征进行1/2的卷积降采样。从实验结果可以看出,MFA-Conformer(1/2)在实时率(RTF)和识别性能这两个上维度上均大幅好于ECAPA-TDNN,特别是在SITW的长时场景下,性能提升效果更加明显。
把SITW测试集切分为 {<5s, <10s, <30s, <50s} 四组进行测试,通过比较3个模型在不同时长测试集下的性能表现
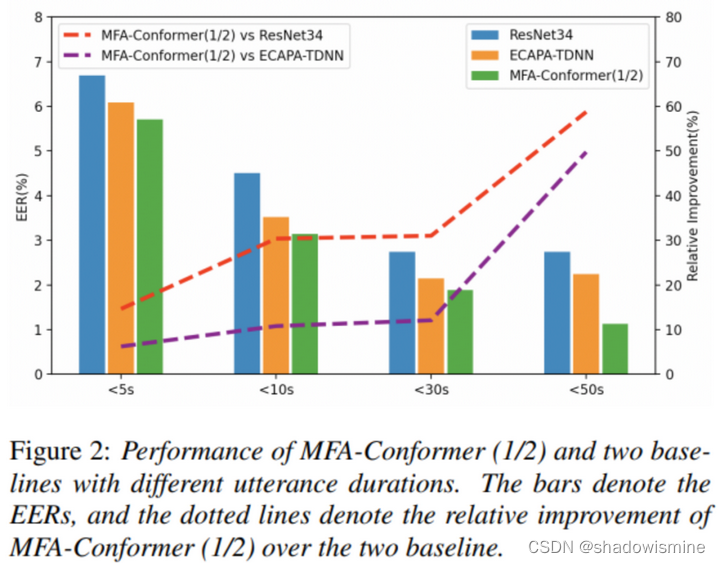
从图中可以看出,随着测试音频时长的提高,所提出的MFA-Conformer的性能提升效果越发明显。这进一步表明,MFA-Conformer通过使用多头注意力层进行全局建模,可以有效地在长时测试场景下提取更鲁棒的说话人表征。
局部建模对声纹识别性能的影响
Conformer与经典Transformer网络结构相比,通过引入卷积模块以更好地挖掘局部信息。为了探究局部建模对声纹识别性能的影响,本文继续通过实验对比Conformer Block与Transformer Block以及各Block个数不同所引起的性能差异,实验结果如下图所示:
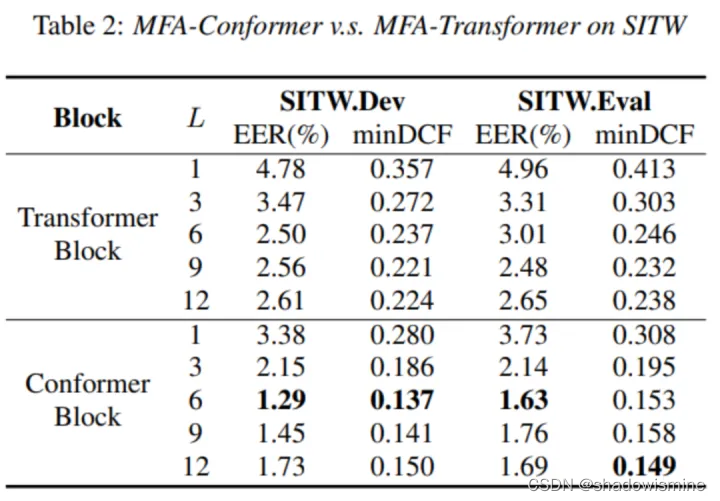
从实验结果可以看出,Conformer Block在识别性能上相比于Transformer有着碾压性的优势;当Block数量设置为6的时候,MFA-Transformer和MFA-Conformer的性能都可以达到最好,Block数量过多或过少都可能导致识别性能的降低。
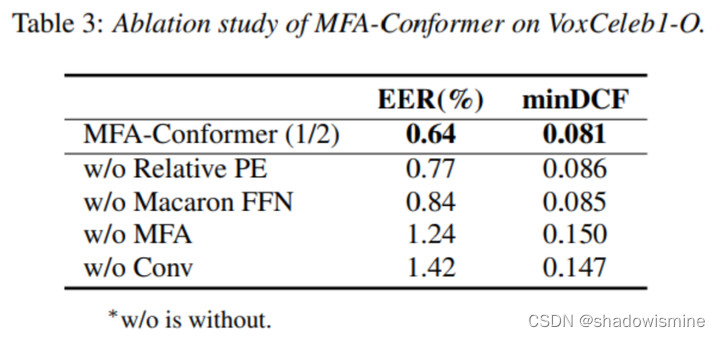
消融实验
为了验证本文所提的MFA-Conformer不同组件所带来的性能提升,本文进行了一系列消融实验,在Voxceleb1-O上的实验结果如下表所示。可以看出,MFA-Conformer具有出色性能的关键主要在于:(1)Confomer Block中的卷积模块(Conv),该模块的引入使得性能相对提升54.9%;(2)多尺度特征拼接(Multi-scale Feature Aggregation, MFA),该模块的引入使得性能相对提升48.3%。
参考文献:
基于多尺度特征聚合Conformer说话人识别模型的创新与应用 - 知乎
这篇关于MFA-Conformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!