本文主要是介绍NLP 漫谈:从 BERT 说开去,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在做 NLP 的课堂作业,花了两天时间着重看了 2018-2021 期间 BERT 这一系列比较有名的模型,顺便做了点笔记。GPT 系列模型我之前做过总结,引路:GPT系列登神之路
ps: 由于文献和资料大多都是英文的,笔记也就顺便用英文写了。
non-contextual and contextual embeddings
non-contextual embeddings: Word2vec, Glove, FastText.
They are (static) non-contextual embeddings: you get the exact same embedding for one token no matter how you use it in your sentence.
FastText uses the same technique of Skipgram and CBOW, but instead of working on a whole word (as in word2vec), it parts the word into n-grams, and then does the same process as Word2Vec, but on these character n-grams. A word is represented as the sum of vectors of character n-grams.
contextual embeddings: ELMo, BERT
They learn contextual embeddings, providing different embeddings for the same token in different context. More semantic informations.
Attention: when people say contextual embeddings, they don’t mean the vectors from the look-up table (the output of embedding layer), they mean the hidden states of the pre-trained model. Thus, all word embeddings are fundamentally non-contextual but can be made contextual by incorporating hidden layers. Word2vec and GloVe embeddings can also incorporate with hidden layers to derive contextual embeddings.
c.f. The discussions: difference-between-non-contextual-and-contextual-word-embeddings
Generally, the hidden layers are LSTM (in ELMo) or Transformer (BERT) to capture contextual information
ELMo uses bidirectional LSTM, but it is not really BIdirectional model. A simple concatenation of forward and backward hidden state in LSTM does not introduce the interactions between tokens. In this sence, BERT is indeed a BIdirectional model.
BERT
Three parts of embeddings in BERT :
- Token Embeddings
Nothing special. A trainable lookup table of size (30522, 768)
- Segment Embeddings
The Segment Embeddings layer only has 2 vector representations, which is a trainable lookup table of size (2, 768). The first vector (index 0) is assigned to all tokens that belong to input 1 while the last vector (index 1) is assigned to all tokens that belong to input 2.
- Position Embeddings
Different to positional encodings in Transformer, BERT learns the position embeddings which is a lookup table of size (512, 768). [BERT handles input sequences up to 512 characters long and the embedding vector of each position is 768-dimension]. That is to say, the first row representing the vector representation of any word in the first position, the second row representing any word in the second position, and so on.
cf: How the Embedding Layers in BERT Were Implemented
Attention: The Position Embeddings in BERT is traiable; while the positional encodings in Transformer is fixed, computed by the formula. One default of the former is non-extendable (cannot treat sequences longer than 512).
Sentence level embedding
BERT uses two pre-training tasks: MLM and NSP (next sentence prediction). The latter is designed to capture sentence relationship. NSP: to predict whether sentence2 is the next sentence of sentence1. Binary classification
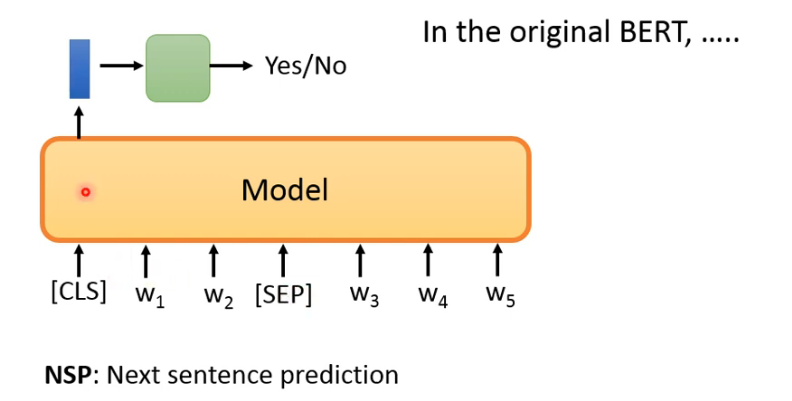
Two aspects to reveal the sentence level information:
- Segment Embeddings
- Adding special tokens and . is inserted in the head of sentence, and is supposed to represent the whole sentence information.
However, RoBERTa (Robustly Optimized BERT approach) shows NSP is in fact not useful: removing the NSP loss matches or slightly improves downstream task performance. This may due to the fact that NSP is a too simple task.
ALBERT (A Lite BERT) proposes a new pre-training task to replace NSP: SOP (sentence order prediction) which predicts whether two sentences are in order. If the correct sentence order is reversed, the model should predict “No”.
BART
https://arxiv.org/pdf/1910.13461.pdf
From Facebook, 2019
BERT cannot talk: Nowadays, the text generation is still in an autoregressive manner. The pre-training task of BERT differs from it. Thus, the generation ability of BERT is weak. [maybe BERT is good at non-autoregressive generation manner]
BART: Bidirectional and auto-regressive transformer. (a typical seq2seq structure).
pre-training tasks for BART (ways to corrupt the input): Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation

Comparison of pre-training tasks: using TextInfilling tasks to pre-train obtains the best performance; Sentence Permutation, Document Rotation results in an obvious drop of performance.
BART can be used for downstream tasks: Sequence Classification Tasks, Token Classification Tasks, Sequence Generation Tasks, Machine Translation.
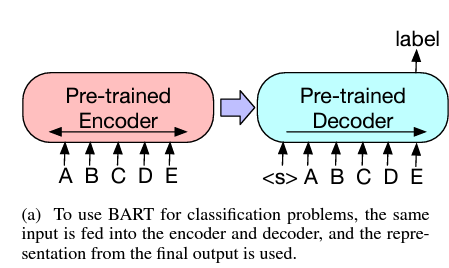
RoBERTa
https://arxiv.org/pdf/1907.11692.pdf
From Facebook, 2019
Optimize BERT: Bigger batch size, more training data, longer input sequence.
Several updates compared to BERT :
-
dynamic mask
The original BERT: performed masking once during data preprocessing, resulting in a static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training.
RoBERTa introduces dynamic mask: generate the masking pattern every time we feed a sequence to the model. But it seems that dynamic mask does not have an absolute advantage.
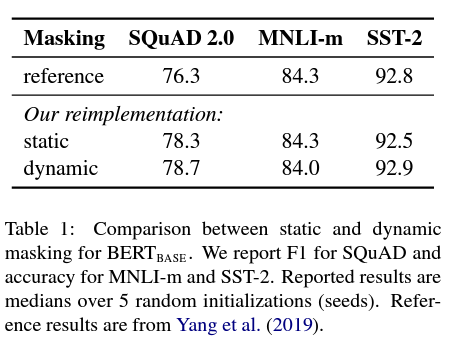
- No NSP pre-training task
RoBERTa romoves NSP pre-training task, which matches or slightly improves downstream task performance.
- byte-level BPE
The original BERT: uses a character-level BPE vocabulary of size 30K, which is learned after preprocessing the input with heuristic tokenization rules. Following Radford et al. (2019)
RoBERTa: consider training BERT with a larger byte-level BPE vocabulary containing 50K subword units, without any additional preprocessing or tokenization of the input.
ELECTRA
https://arxiv.org/pdf/2003.10555.pdf
From Google and Stanford, 2020
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
Predict the masked token is computational costly. ELECTRA proposes a new pre-training task: replaced token detection (RTD), aiming to predict whether one token is replaced by the another one. It is a binary classification.
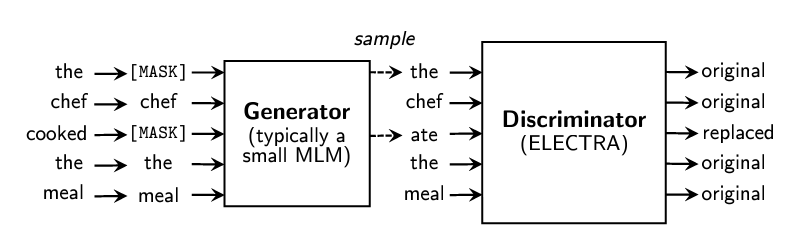
Typically, it uses a tiny BERT as generator, in order to predict the masked tokens. Then use these predicted tokens, let ELECTRA tell us whether one token has been replaced.
Generator and Discriminator are jointly trained: the former minimizes loss MLM and the latter minimizes loss MLM+RTD (we could not back propogate RTD loss to generator).
Note: The author found that, if the discriminator and the generator share the same token embeddings, the performance would be better. In this case, the token embeddings are trained on loss MLM+RTD. Later, DeBERTa v3 proposes an optimization: Gradient-Disentangled Embedding Sharing.
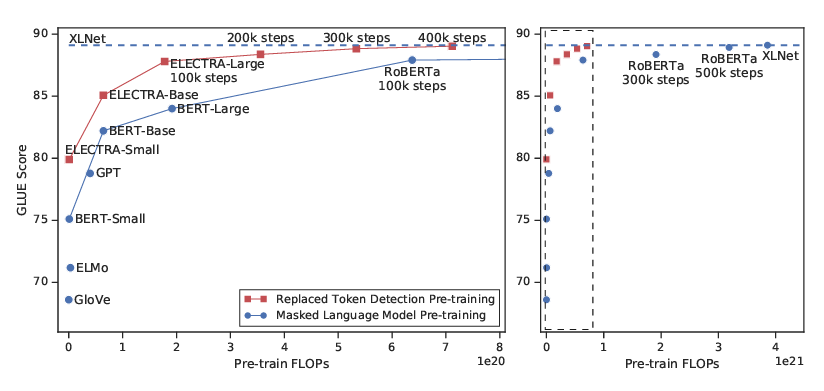
ELECTRA achieves a competitively performance on GLUE, while with a much lower TFlops, nearly 1/4.
ALBERT
https://arxiv.org/pdf/1909.11942.pdf
From Google, 2020
present two parameter reduction techniques to lower memory consumption and increase the training speed of BERT:
- factorization of the embedding matrix: Instead of projecting the one-hot vectors directly into the hidden space of size H, we first project them into a lower dimensional embedding space of size E, and then project it to the hidden space. By using this decomposition, we reduce the embedding parameters from O(V ×H) to O(V ×E +E ×H).
- Cross-layer parameter sharing: The default decision for ALBERT is to share all parameters across layers.

The transitions from layer to layer are much smoother for ALBERT than for BERT. Even if there is a drop of performance compared to BERT, the parameters become 3-4 times less than BERT.
Another contribution:
- SOP (sentence order prediction) pre-training task. To focus on modeling inter-sentence coherence. Positive examples: two consecutive segments from the same document; Negative examples: the same two consecutive segments but with their order swapped.
T5: Transfer Text-to-Text Transformer
From Google, 2020
https://arxiv.org/pdf/1910.10683.pdf
c.f. https://zhuanlan.zhihu.com/p/88438851
No brilliant ideas, but surprising computation ressources! It introduces a unified framework that converts all text-based language problems into a text-to-text format. It compares pre-training objectives, architectures, unlabeled data sets, transfer approaches, and other factors on dozens of language understanding tasks.

Compare architecture
- Encoder-decoder (Full-visible): a typical seq2seq model using transformer. E.g. BART
- language model (Causal): decoder part. E.g. GPT
- prefix language model (Causal with prefix): combines encoder and decoder. E.g. UniLM
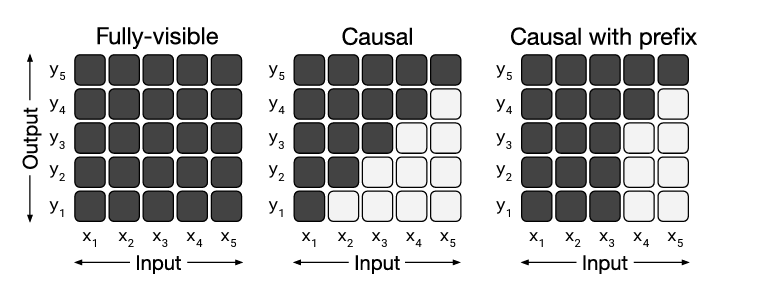
It turns out that Encoder-decoder architecture with a denoising pre-training objective (MLM, as in BERT) achieves best performance. Surprisingly, sharing parameters across the encoder and decoder performed nearly as well, while halving the total parameter count.
Compare Unsupervised Objectives

- Prefix LM objective: predict from left to right
- BERT-style denoising objective: predict masked tokens
- Deshuffling: convert the shuffled text to the original
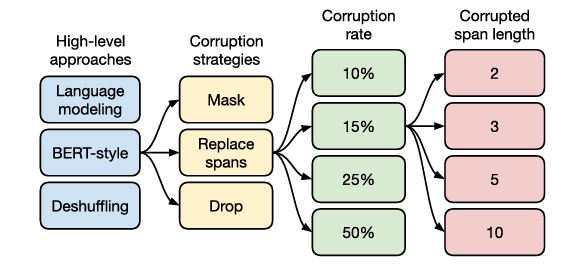
BERT-style denoising objective performs best. Moreover, The best corruption strategies is Replace spans (All consecutive spans of dropped-out tokens are replaced by a single sentinel token. Each sentinel token is assigned a token ID that is unique to the sequence).
Corruption rate 15% wins (which is the rate in original BERT). The best corrupted span length is 3.
Other takeaway
The basic approach of updating all of a pre-trained model’s parameters during fine-tuning outperformed methods that are designed to update fewer parameters, although updating all parameters is most expensive.
DeBERTa
From Microsoft, 2021
https://arxiv.org/pdf/2006.03654.pdf
cf. https://blog.csdn.net/weixin_42437114/article/details/127017933
From Microsoft DeBERTa: Decoding-enhanced bert with disentangled attention. Compared to RoBERTa-Large, a DeBERTa model trained on half of the training data performs consistently better.
Contributions:
- disentangled attention mechanism: each word is represented using two vectors that encode its content and position, respectively (As comparison, BERT just sums them up). And the attention weights among words are computed using disentangled matrices on their contents and relative positions, respectively.
- an enhanced mask decoder: incorporate absolute positions with contextual embeddings before softmax (which is to predict the masked tokens in model pre-training MLM).
- Scale-invariant-Fine-Tuning (SiFT): a new virtual adversarial training method for fine-tuning. It aims at improving a model’s robustness to adversarial examples (created by making small perturbations to the input).
For NLP tasks, the perturbation is applied to the word embedding instead of the original word sequence. But the norm of the embedding vectors vary among different words and models. SiFT: applys the perturbations to the normalized word embeddings.
DeBERTa v3
From Microsoft, 2021
https://arxiv.org/pdf/2111.09543.pdf
-
replacing mask language modeling (MLM) with replaced token detection (RTD)
-
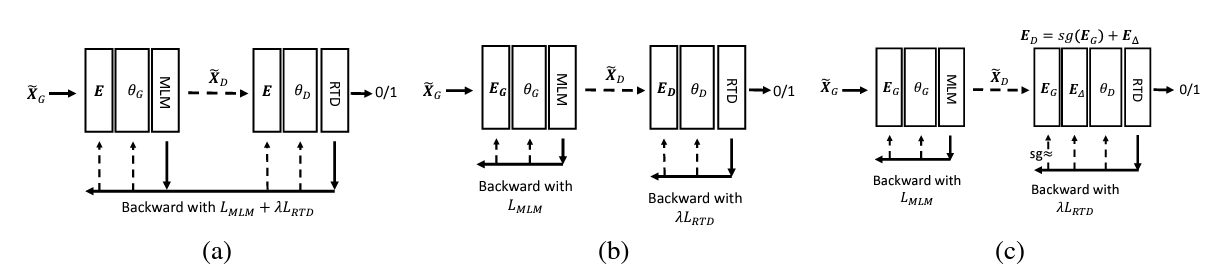
gradient-disentangled embedding sharing method (GDES) ©
The author argues that Embedding sharing in ELECTRA pull token embeddings into very different directions, which causes “tug-of-war” (a). MLM tries to map the tokens that are semantically similar to the embedding vectors that are close to each other. RTD, on the other hand, tries to discriminate semantically similar tokens, pulling their embeddings as far as possible to optimize the classification accuracy.
But if use totally different token embeddings for G & D, the performance drops (b).
GDES: MLM loss to train embedding for G & D; RTD loss to train delta embedding E Δ E_{\Delta} EΔ, which is stored separately during training, to keep E G E_G EG and E D E_D ED same. After training, sum up to get final E D E_D ED. In fact, the gradient of RTD loss is disentangled during training, hence the name.

Network compression
-
network Pruning:
- Removes unnecessary parts of the network after training. This includes weight magnitude pruning, attention head pruning, layers, and others.
-
Weight Factorization
-
Approximates parameter matrices by factorizing them into a multiplication of two smaller matrices. This imposes a low-rank constraint on the matrix. Weight factorization can be applied to both token embeddings (which saves a lot of memory on disk) or parameters in feed-forward / self-attention layers (for some speed improvements).
-
Knowledge Distillation
-
Aka “Student Teacher.” Trains a much smaller Transformer from scratch on the pre-training / downstream-data. Normally this would fail, but utilizing soft labels (pseudo labels) from a fully-sized model improves optimization for unknown reasons.
-
Weight Sharing
-
Some weights in the model share the same value as other parameters in the model. For example, ALBERT uses the same weight matrices for every single layer of self-attention in BERT.
-
parameter Quantization
-
Truncates floating point numbers to only use a few bits (which causes round-off error). The quantization values can also be learned either during or after training.
c.f. All The Ways You Can Compress BERT
Examples: Distill BERT, Tiny BERT, ALBERT…
Ways of fine-tuning
How to fine-tune models:
- Fix the whole pre-trained model (use it as a feature extractor), only train several added layers
- Fine tune the pre-trained model and several added layers
- Add some layers into pre-trained models (called adaptors). Only train these adaptors and added layers
- Instead of using output of last layer of pre-trained model, compute a weighted sum of output for different layers or blocks (typically useful for transformer blocks, because output of each block has same shape). The weights can be learned during fine tuning.
Generally speaking, method 1 is most performant (cf takeaways in T5), but it is the most expensive.
Method 2 is the next performant, but it has to store a new model for each downstream task.
Method 3 tries to solve this pbm, but where to add the adaptors remains a open problem.
这篇关于NLP 漫谈:从 BERT 说开去的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![漫谈设计模式 [12]:模板方法模式](/front/images/it_default.gif)
