本文主要是介绍神策数据 CJO 系列丨解密 CJO:连接体验的下一个前沿趋势,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

10 余年前,市场营销的焦点聚集在增长黑客如何利用 AARRR 模型(获取 Acquisition、激活 Activation、留存 Retention、收入 Revenue、传播 Referral)来推动并加速企业的生长发展。我们曾相信,在 AARRR 漏斗中,只要我们吸引了足够的目光,就能实现令人满意的转化。
然而,如今我们身处一个触点爆炸的时代。2023 年 8 月,神策发布客户旅程编排相关调研,调研数据显示,约 92% 以上的企业都在近一年内观察到数字渠道的客户数量增加,同时有超过 86% 的企业发现一直在面对新的和不断变化的客户旅程。但当被问到企业客户体验战略的实际实施情况时,有将近一半的企业认为自己的战略实施效果是一般的。
这些反馈凸显了企业解决用户体验问题已经迫在眉睫,并提醒我们,传统的营销活动、优惠和广告已经不再足够。这些策略是孤立存在的,而客户的旅程则不是如此,它可以往后、向前,并跨越数字和线下渠道。
因此,在这个不断变化的营销环境中,企业正在重新审视与目标受众的互动方式。我们迎来了一个全新的概念——客户旅程编排(Customer Journey Orchestration,简称 CJO)。
一、什么是 CJO
国际知名机构 Gartner 将 CJO 定义为在整个客户生命周期中组织一组推荐的交互来响应或创建客户信号。其本质是客户全生命周期交互体验管理,强调个性化、全渠道一致的体验。
二、CJO 的发展历史
CJO 的演变可以分为三个阶段,每个阶段都紧随着时代的变化,针对企业当前的核心难题提供了解决方案。
在 1.0 阶段,即前数字化时代,主流的触点集中在线下门店和分支机构,企业主要通过电视、海报等传统媒体作为营销渠道,和消费者的互动更偏向于面对面或者电话交流。在这个时期,客户旅程相对简单,客户在认知、购买和服务之间涉及的步骤相对有限。因此,企业对客户旅程编排的需求也相对有限,一对一的互动已经可以满足交互的质量和效率。
进入 2.0 数字化时代,交易型业务开始向线上迁移,企业通过 banner、电子邮件、在线客服等渠道与消费者互动,客户旅程的跨渠道特性使得连接客户交互的各个阶段更具有挑战性。在这个阶段,手工流程开始被活动管理平台所取代,但这更多地用于促销活动,而非促进客户旅程体验。
随后, 3.0 全域时代的来临,流量红利触顶,App、智能电视、社交媒体等各个触点中都已嵌入交易功能,渠道爆炸式的增长使得跨渠道和设备交互迎来了全新的机遇和挑战,企业对全渠道客户旅程管理需求增加,开始实施部署客户旅程编排平台,以深入了解客户旅程,并基于智能优化来实现互动,为客户提供一致化的体验。

图 客户旅程编排的发展历程
在大约 10 年前,Responsys 公司(该公司于 2013 年被 Oracle 收购)最早在《营销编排的崛起》中提到 CJO,其理念试图将旅程构建技术和营销自动化技术的发展区分开来。在北美市场,很多营销人员已经有至少 10 年的事件触发营销技术经验,他们面临的挑战实际上是如何从中获取更多收益。
我们认为应该向一个主要由实时行动触发或推动的营销世界过渡,而这就主要需要依靠在营销领域相对年轻的部分——CJO。在某种程度上,我们可以从一端的活动开始,通过中间的多步骤旅程,再到由预测算法协调的个体交互,这就是所谓的“下一个最佳行动”(next best action)。
三、CJO 与营销自动化/活动管理的不同
活动管理被定义为计划、设计、执行和分析营销活动的过程,其关键特征在于以公司的内部视角作为出发点,通过向尽可能多的受众传达信息来实现企业目标,通常在预定的时间段内,通过进行一系列有组织的任务或活动来实现某个特定的业务目标或结果,依赖于预先筛选定义的客户分群。这种方式更加注重效率、成本控制和一致性。
通过营销自动化,活动管理可以简化并加强企业与客户互动的过程,从而帮助企业减少重复性任务,提升营销团队的产出。
而相比之下,CJO 则更具全面性和先进性,它关注客户的需求、感受和满意度,将客户体验置于核心位置。CJO 贯穿企业与客户互动的各个阶段,实时触发并为个体提供互动。
旅程编排在整个过程中持续运行,根据客户行为实时触发。与预先安排的批量互动不同,CJO 更关注个体的需求和目标,它详尽地描述了客户从了解品牌、产品或服务,到最终购买和使用,乃至反馈和推荐的完整体验过程。
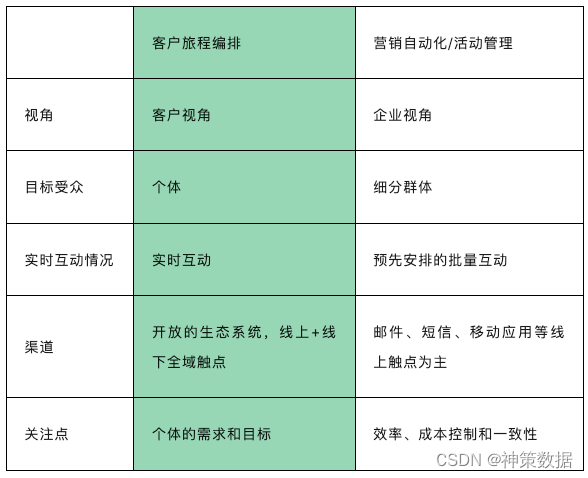
表 客户旅程编排与营销自动化/活动管理的区别
四、CJO 的价值
CJO 为企业和受众带来一种全新的且至关重要的交互模式,它旨在实时响应不断变化的客户行为,助力品牌提供灵活适应性。将 CJO 纳入业务战略对企业带来诸多益处,麦肯锡的研究表明,“如果一个企业能尽力优化客户旅程,不仅可将企业的客户满意度平均提高 15%,更可能降低 20% 的客户服务成本,同时可以提高 15% 的收入”。
神策今年 8 月进行的问卷调研结果也显示,企业认为 CJO 能带给企业最大的三个价值分别是提升用户体验、帮助企业将产品/服务/体验个性化、以及构建以客户为中心的企业文化。
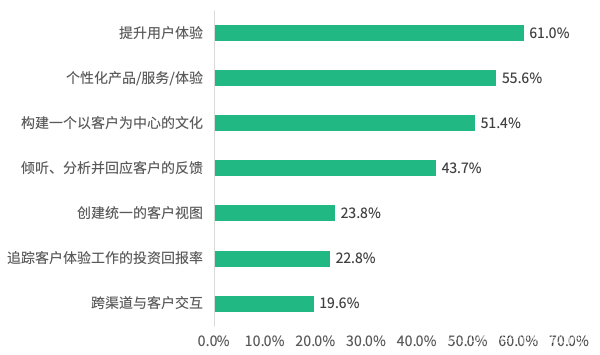
图 客户旅程编排带给企业最大的三个价值(N=403)
由此可见,优化客户旅程是企业提升业绩、提升用户体验并取得成功的关键,企业需运用 CJO 串联各触点业务流程,从而打造全渠道一致的客户体验。罗兰贝格也预测,未来客户体验部门在企业中的重要性和引领地位将不断提升,从而帮助企业在满足个性化客户体验中脱颖而出。
目前,市场正在逐渐接受 CJO 的理念,至少在北美市场,Gartner 的调研数据表明,94% 的营销科技领导者在未来两年都在计划或已经在实施旅程编排,其中 55% 的领导者认为这是他们 2023 年最迫切需要解决的关键任务。
然而,仍有很多企业在苦苦挣扎,因为构建这些旅程并不容易。很多营销人员认为他们需要构建复杂且庞大的多步骤旅程,而实际上,更重要的是创造更多的内容,让算法来找出在这些内容和互动的空间中的路径,通过多触点归因来确定哪些互动真正有价值。
那么,旅程编排能够帮助企业解决哪些关键问题?企业如何构建一个擅长编排的组织?企业如何从投资于支持编排的技术中获得竞争优势?请继续关注神策数据 CJO 系列文章,敬请期待!
参考来源:
1. 麦肯锡《客户体验:中国市场中的增长神器》
2. 罗兰贝格《预见 2023 | 数字化领域重点趋势分享:客户体验和精益运营引领数字化未来》
这篇关于神策数据 CJO 系列丨解密 CJO:连接体验的下一个前沿趋势的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






