本文主要是介绍神策数据《2023 中国客户旅程编排(CJO)应用指南》预领取通知,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


基于对数字化转型时代触点红利与企业发展的深入洞察,神策数据围绕客户旅程编排(Customer Journey Orchestration,简称 CJO)进行全面研究,旨在为更多企业数字化转型过程中重塑客户体验、挖掘增量机会、节省长期投入等提供科学有效的方法论指导。
今日,神策数据《2023 中国客户旅程编排(CJO)应用指南》预领取通道正式开启!您可以识别下方海报二维码,或点击文末“阅读原文”,预约领取完整版报告。

以下为报告节选:
>> 客户体验管理发展阶段
报告显示,客户体验对未来购物决策有显著影响,已经与产品、价格同等重要。优质的客户体验可以直接带来业绩增长。
目前,客户体验管理经过了单渠道/触点优化、场景式打造、全旅程运营三个阶段的发展。
>> 客户旅程编排及其价值
客户旅程编排是指在客户生命周期中编排一系列最佳互动,以响应或激发客户反馈。
触点红利时代,企业与客户的触点数量、单一触点的功能、客户自主创建的旅程增加,企业可以基于客户旅程,实时洞察客户与企业的每一次互动,向客户规模化地提供个性化体验,帮助客户完成旅程目标。
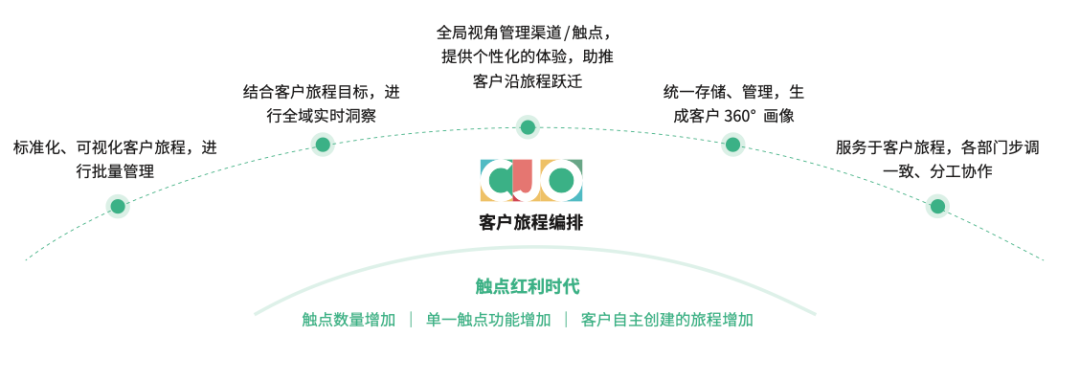
报告强调,客户旅程编排是培育客户忠诚最有效的方式。客户旅程编排理念推动企业所有相关方均以客户为中心,高效实时管理全域客户互动,更加全面满足客户需求,使客户与企业建立互信的关系,并最终形成忠诚。
通过清晰认识客户旅程的变化,并配备实时客户旅程分析能力,能够帮助企业应对、预判客户行为的变化,这将极大地增加企业的长期竞争优势。
对于企业来说,客户旅程编排能够帮助企业实现以下四方面的价值:
第一,统一认知,建立以客户为中心的业务模式。
第二,全局视角优化客户遇到的断点、卡点、摩擦点。
第三,管理长尾客户旅程,挖掘业务增量机会。
第四,准确评估 IT 系统投入产出,节省长期成本投入。
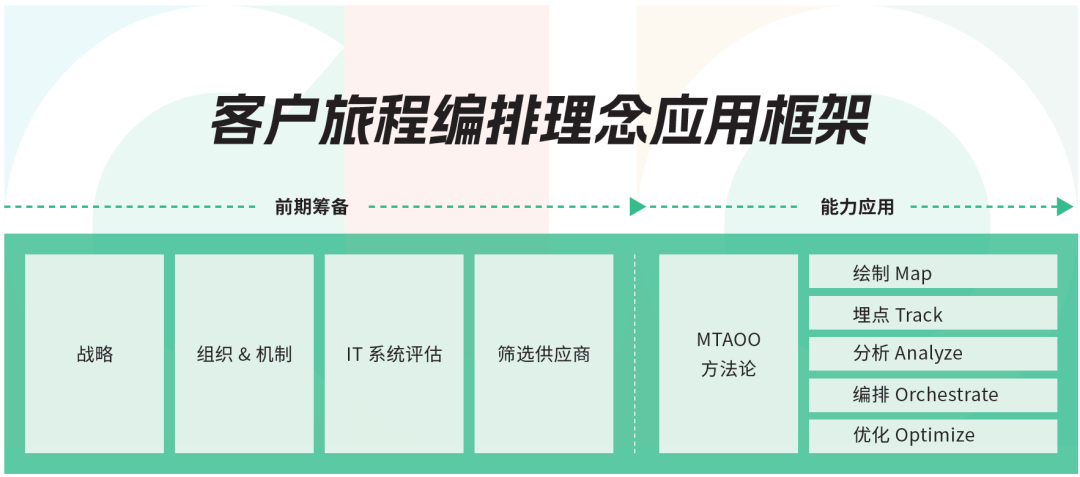
最后,报告从前期筹备和能力应用两个维度,围绕战略、组织 & 机制、IT 系统评估、供应商筛选等,详细阐述了客户旅程编排理念的应用框架,并通过案例实践进一步验证。
本次「限时预约领取活动」截止 10 月 26 日,点击文末“阅读原文”完成预约登记,即可优先获取电子版报告。(神策数据将会在 10 月 27 日中午前发送报告至您的邮箱,请耐心等待哦~)
温馨提示:正式版报告将于 10 月 27 日在神策 2023 数据驱动大会现场正式发布,您也可以报名参加大会,现场领取纸质版报告~
✎✎✎
【更多内容】
构筑卓越:为 CJO 打造关键基础设施
创造价值:CJO 如何解决核心业务挑战
解密 CJO:连接体验的下一个前沿趋势

👆🏻 神策 2023 数据驱动大会火热报名中 👆🏻
点击图片了解详情!
▼ 点击“阅读原文”,立即预约登记
这篇关于神策数据《2023 中国客户旅程编排(CJO)应用指南》预领取通知的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





