本文主要是介绍一.开发记录之AHRS、惯导传感器SBG-Ellipse-N传感器配置和使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 磁力计校准
Window上位机连接上模块
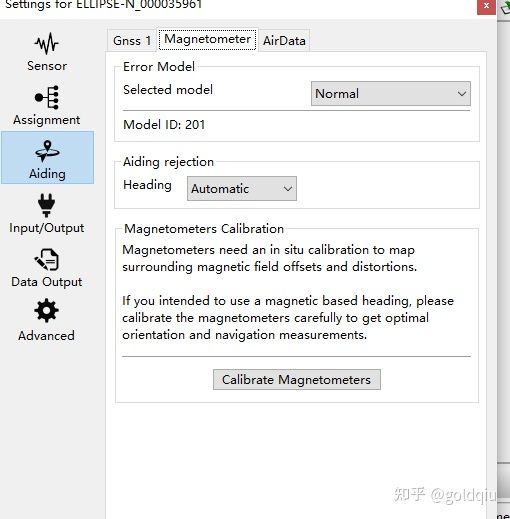
在室外点击Calibrate Magnetometers,然后按手册进行校准,让传感器尽可能在多的不同方向旋转。校准结束,按下“Calibrate”按钮,点击OK,上位机会有参数值示意,达到1左右就可以了。
二、 惯导ROS驱动yaml文件修改
惯导ROS驱动包yaml文件可以修改传感器参数,但是不建议。建议的做法是在上位机进行修改,修改后yaml文件也同步进行修改。比如:
1) 需要找到传感器的串口号,然后更改portName: "/dev/ttyUSB0"
2) 更改波特率: baudRate: 921600
3) 更改运动模型: motionProfile: 2 (注:车载模型)
4) 更改输出:改成ros时间:time_reference: "ros"
5) 更改输出:改成ROS的IMU消息格式 : ros_standard: true
6) 更改输出:更改为ENU坐标系, use_enu: true
7) 更改输出:更改frame_id : frame_id: "imu_link"
8) 更改输出:更改系统状态刷新频率:log_status: 200
9) 更改输出:更改IMU数据刷新频率: log_imu_data: 1
10) 更改输出:更改UTC时间刷新频率: log_utc_time: 200
11) 更改输出:更改磁力计数据刷新频率: log_mag: 4
三、 编译和运行
cd catkin_ws/src
git clone https://github.com/SBG-Systems/sbg_ros_driver.git
cd ../
catkin_make
roslaunch sbg_driver sbg_device.launch
注意:在运行前要给设备串口给权限。
这篇关于一.开发记录之AHRS、惯导传感器SBG-Ellipse-N传感器配置和使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






