本文主要是介绍[论文阅读] Exploring Word Segmentation and Medical Concept Recognition for Chinese Medical Texts,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
英文标题:Exploring Word Segmentation and Medical Concept Recognition for Chinese Medical Texts
中文标题:探索中文医学文本的分词与医学概念识别
GitHub:GitHub - cuhksz-nlp/AESINER
动机
电子病历处理通常包括两个任务:中文分词和医学概念识别;作者认为缺乏高质量注释的医学领域数据集,特别是能够揭示中文病历特征的相关标签,因此作者建立了ACEMR语料库,专门用于医疗中中文分词和医学概念识别的数据集,并在该数据集上分别对中文分词和医学概念识别进行实验。
亮点
建立医疗领域中相对专业的数据集。
建立过程
1.收集当地医院5个科室(呼吸内科、消化内科、泌尿科、妇科、心脏病科)的500份电子病历,每份电子病历记录1名患者住院记录中的疗程记录,包括患者科室、病房、基本信息、病例特点、初步诊断、鉴别诊断、治疗方案
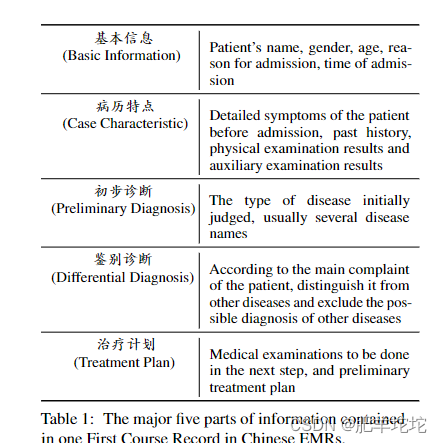
2.标注
参与标注的是2名初级医师和2名NLP在读博士,参考统一医学语言系统(UMLS)语义组定义的医学分类学和Chinese Treebank对一般领域的分割指南以及其他学者提出的标注指南后,定义了7个主要的医学概念类和20个子类,具体如表:
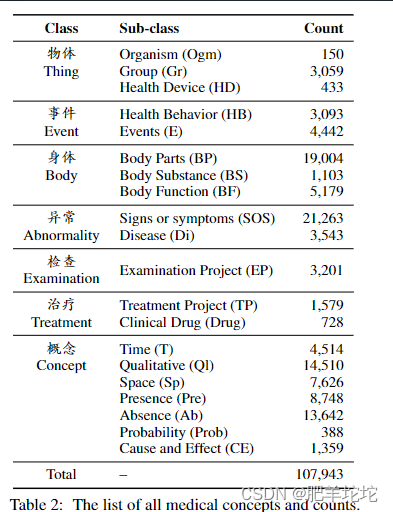
根据注释指南,两名医师首先独立标注这500份病例,并通过讨论解决他们的分歧,最终用F值来评价两个标注者标注的一致性,具体方法是将其中一个标注者(A1)的标注结果作为标准答案,计算另一个标注者(A2)标注结果的F值,用F值评价CWS和医学概念标注的一致性为0.9409和0.9360。
论文中给的一个标注例子:

解释:其中汉语单词被白色的空格隔开,附加到特定单词的医学概念标签以红色高亮显示(“/”是单词与其医学概念标签之间的分隔符)。如果一个中文单词被翻译成多个英文单词,我们在英文译文中用“*”来标记表4中的边界。例如,“3天”被翻译成“* 3天*”
实验
先验知识:
“BIES”方案、“BIOES”方案分别是命名实体识别中的标注方案
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符,非实体
1.中文分词实验:
方法:按照以往研究的惯例,将其视为’BIES‘方案的序列标注任务
相关模型:BiLSTM、Bert、Zen和WMSeg3
数据集:ACMER和CTB6
参数:参数设置参照官方设置,Embedding Dataset -- NLP Center, Tencent AI Lab
实验结果:
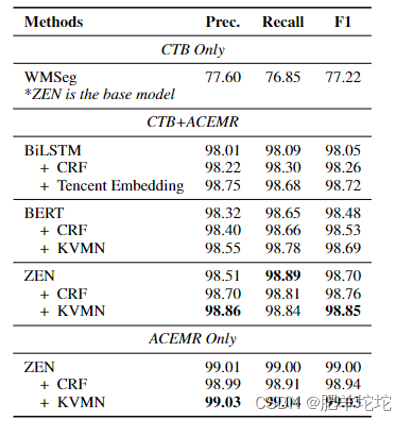
CTB Only设置显示WMSeg模型(使用Zen编码器)的结果。较差的结果证实了普通领域和医学领域的文本和指南之间的巨大差距,这表明从普通领域到医学领域进行迁移学习是一项挑战。CTB+ACEMR设置显示了在ACEMR和CTB6数据集的组合上训练的所有模型的结果,其中所有模型都比仅在CTB6上训练的WMSeg模型有很高的改善,强调了在医学领域构建带标注的数据集的必要性。与BERT和ZEN Baseline相比,在BERT/Zen编码器的顶部添加KVMN模块来利用文字信息(这正是WMSeg的体系结构)可以提高CWS的性能。
2.概念识别实验
方法:视为基于字符序列标注任务,并以与命名实体相似的方式进行识别,医学概念标记遵循“BIOES”方案。
相关模型: 基于CRF解码器的BiLSTM、BERT和ZEN编码器
结论1:
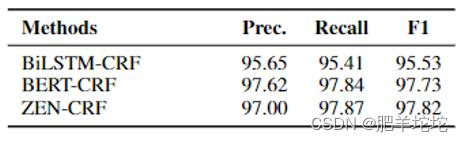
ZEN-CRF取得最高的性能表现
结论2:加入三种不同类型的自动生成的句法信息(即词性标签、依赖关系和句法成分)运行TwASP模型,得到以下结果:
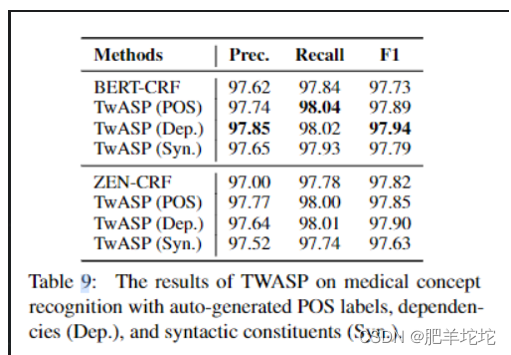
尽管在ZEN_CRF等模型上已经取得不错的效果,但是在加入句法信息后,模型性能仍有提升。
读者小结
建立属于医疗领域的语料库对于命名实体识别是非常有必要的,在医疗领域的数据集上进行医疗领域的实体对齐模型性能由于其他数据集,在读到这篇论文的时候,已经有一些开源的数据集可供医疗领域使用,但依然存在OOV问题。
这篇关于[论文阅读] Exploring Word Segmentation and Medical Concept Recognition for Chinese Medical Texts的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




