本文主要是介绍李沐——论文阅读——VIT(VIsionTransformer),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、终极结论:
如果在足够多的数据上面去做预训练,那么,我们也可以不用 卷积神经网络,而是直接用 自然语言处理那边搬过来的 Transformer,也能够把视觉问题解决的很好
(tips:paperswithcode.com——查看各个机器学习领域的State of art)
二、标题信息:
一张图像 == 很多16*16大小的单词序列
三、摘要:
在NLP中无论是Bert,GPT还是T5,其中的transformer已经成为了标配,但是,计算机视觉中tranformer用得还有限,即使是使用了transformer,也只是在整个model的一个stage中用到了自注意力机制。而VIT会告诉你,这些都不用,直接照搬NLP的model就可以了
四、引言:
首先,transformer的应用,使得GPT那些大模型还没有性能饱和,
其次,直接用原始像素的话太大了,不可行,而已有的工作呢,比如,有把网络中间的feature map作为transformer的输入的,也有分横轴、纵轴作为transformer的输入的(这个的硬件加速没有实现,所以很难做大模型)
之后,就是VIT的工作,就是将图像看作1个个16*16大小的“单词序列”,直接输入到NLP的model中即可
最后,结果显示,只要预训练的数据够多,就能够取得比原来卷积神经网络更好的效果
五、结论:
反正,就是这个VIT能够把分类任务做得很好,然后,在图像分割等视觉也应该能够做得很好(挖坑),并提出了一些展望什么的。
六、相关工作:
和introduction中的前期工作相似,多了一个利用图像生成(imageGPT)进行图像分类,当时只是达到72%的正确率,但是,后来何凯明团队提出的MAE却能够利用图像生成在各个图像任务上面取得很好的效果
七、主题:VIT模型的结构
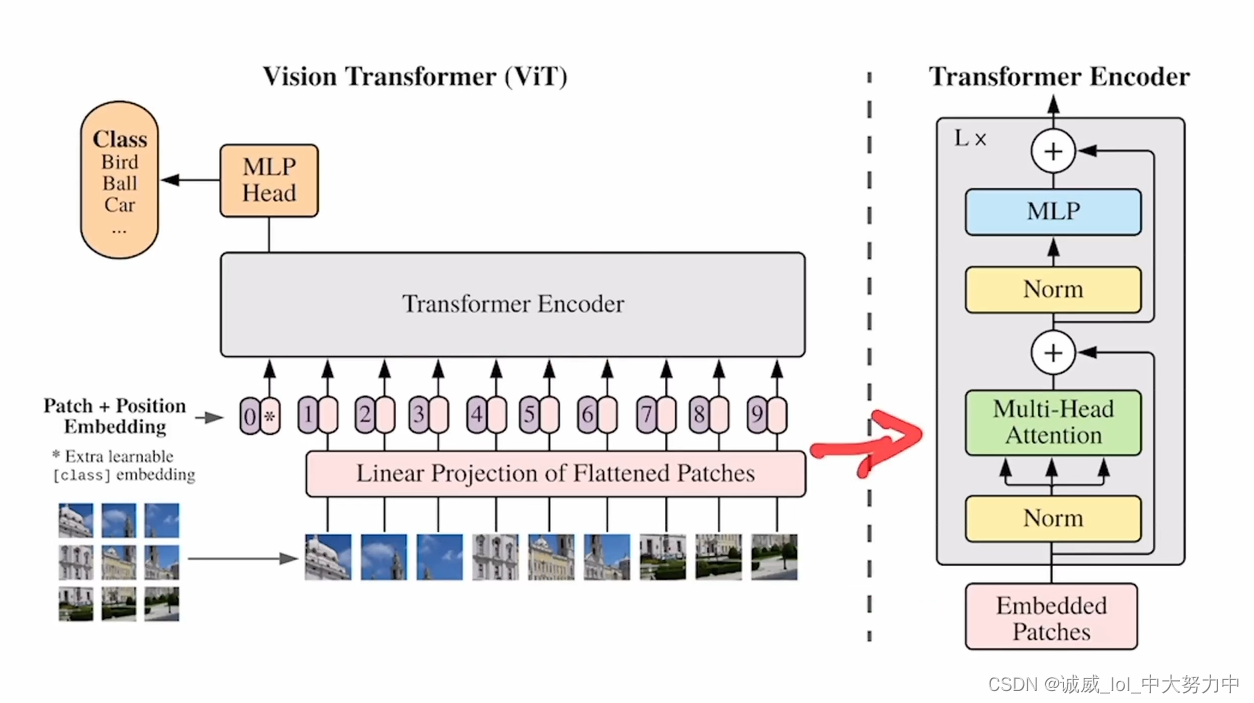
主要就是这个patch embedding的部分,整个transformer Encoder就是 重复了L次的上面右图的结构,同时,这个视频也讲到整个 “前向流程”——包括1D的位置编码。。。参见视频即可,需要用的时候再去了解
(对了,这里明白了一个新的点,就是消融实验,一般放到附录中,有点像 单一变量原则)
八、实验部分:
就是 展示了这个VIT的正确率情况等等。。。反正就是表现得非常nice,还有它里面每一层特征学到的结果,还有改用自监督的方式训练得到的结果正确率只有80%。。。
这篇关于李沐——论文阅读——VIT(VIsionTransformer)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)