visiontransformer专题

使用 VisionTransformer(VIT) FineTune 训练驾驶员行为状态识别模型
一、VisionTransformer(VIT) 介绍 大模型已经成为人工智能领域的热门话题。在这股热潮中,大模型的核心结构 Transformer 也再次脱颖而出证明了其强大的能力和广泛的应用前景。Transformer 自 2017年由Google提出以来,便在NLP领域掀起了一场革命。相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM), Transformer 凭借自注意力机制
visionTransformer window平台下报错
错误: KeyError: 'Transformer/encoderblock_0/MlpBlock_3/Dense_0kernel is not a file in the archive' 解决方法: 修改这个函数即可,主要原因是Linux系统与window系统路径分隔符不一样导致 def load_from(self, weights, n_block):ROOT = f"

【clip源码阅读】VisionTransformer
lib/python3.8/site-packages/clip/model.py#L206 class VisionTransformer(nn.Module):def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):su
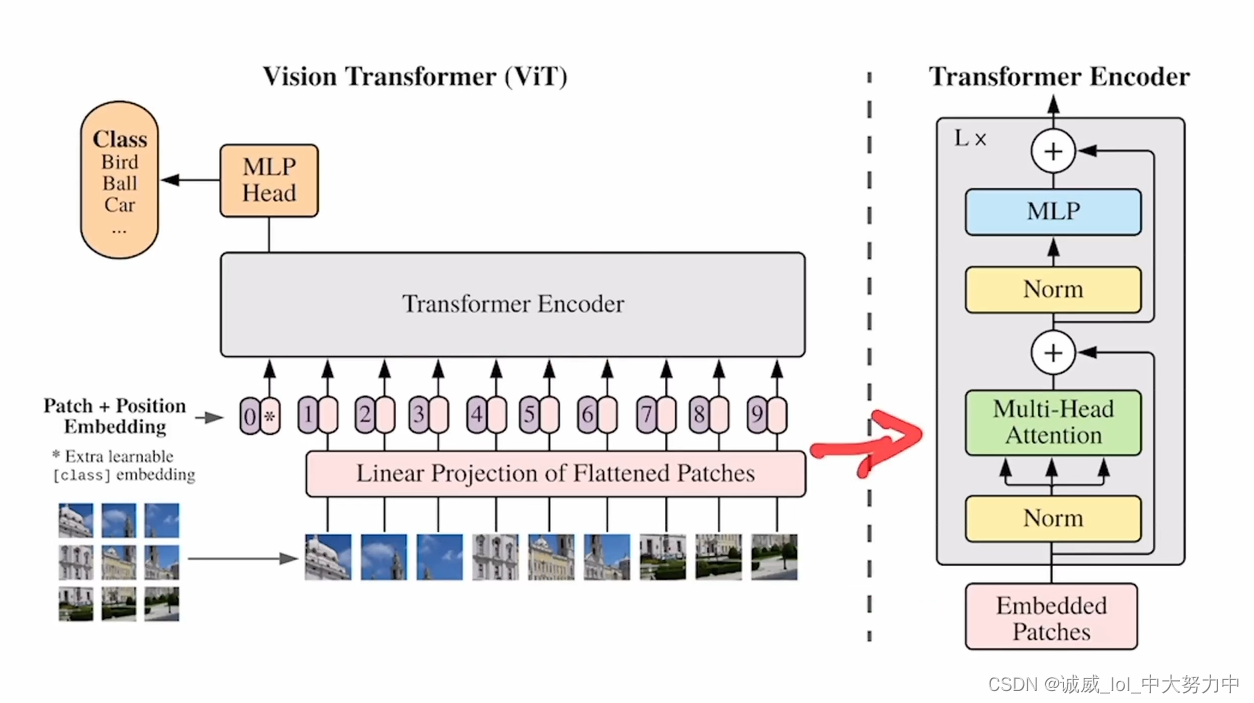
李沐——论文阅读——VIT(VIsionTransformer)
一、终极结论: 如果在足够多的数据上面去做预训练,那么,我们也可以不用 卷积神经网络,而是直接用 自然语言处理那边搬过来的 Transformer,也能够把视觉问题解决的很好 (tips:paperswithcode.com——查看各个机器学习领域的State of art) 二、标题信息: 一张图像 == 很多16*16大小的单词序列 三、摘要:
李沐——论文阅读——VIT(VIsionTransformer)
一、终极结论: 如果在足够多的数据上面去做预训练,那么,我们也可以不用 卷积神经网络,而是直接用 自然语言处理那边搬过来的 Transformer,也能够把视觉问题解决的很好 (tips:paperswithcode.com——查看各个机器学习领域的State of art) 二、标题信息: 一张图像 == 很多16*16大小的单词序列 三、摘要: