本文主要是介绍【Pipeline】林业病虫害防治AI昆虫识别项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 项目概述
1.1 原始项目简介
本项目基于百度AIStudio课程【手把手带你零基础入门深度学习-2.0版本】中课节12的内容——目标检测YOLOv3算法和AI识虫比赛改编。在课程页面加入课程后,便可点击上述链接查看课节12的内容。
该节课程使用了百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集。课程项目训练了一个YOLOv3模型,并基于它检测图像数据中的昆虫。
目标检测YOLOv3算法课程讲解了YOLOv3的基础知识以及一些对昆虫数据集的预处理操作,AI识虫比赛课程则讲解了模型的“训练”、“评估”、“预测”步骤。本项目为了简化流程,只将Pipeline运用于AI识虫比赛的课程内容,故下文中出现的“原始项目”一词均指代AI识虫比赛
1.2 为什么使用Pipeline
| 特性 | 传统方法 | Pipeline |
|---|---|---|
| 自动化 | 运行一个完整流程需要用户多次操作,来执行多个步骤。 | Pipeline将多个步骤有机的结合成一个整体,实现一次操作便可自动化的运行整个流程的效果。 具体操作方式可查看2.4节。 |
| 标准化 | 开发前需要商定多个步骤间传递数据的方式。 | Pipeline具有标准化接口,有利于多人合作开发,提升开发效率。 |
| 高可复用性 | 一个步骤难以在多个流程中使用。 | 所有步骤都被封装成Op,能更好的支持复用,减少开发工作量。 百度某热门AI项目使用Pipeline后,开发效率提升3倍。 |
| 可视化 | 无可视化功能,从而难以整体把控全流程。 | Pipeline可以将流程进行图形化展示,从而更易掌控全流程。 |
| 快速复现 | 实验记录易丢失,导致实验难以复现。 | Pipeline会保存运行记录,可以根据记录中的信息(如本项目中使用的模型类型、模型的超参数等),对实验进行快速复现。 |
| 产出管理 | 实验的产出难以管理。 | Pipeline会对实验的产出进行系统化的管理。 |
Pipeline的详细介绍可参考Pipeline简介。
Op是Pipeline运行时的基本调度单位,Pipeline中的每一个节点都需要是一个Op。Op的具体介绍请查看Op详细介绍
2 构建并运行Pipeline
2.1 Pipeline构建思路
原始项目做的事情主要有“模型训练”、“模型评估”、“模型预测”。而针对一个原始项目,我们想基于它构建一个Pipeline,最重要的是以下2点。
-
构建Op:构建每个步骤对应的Op。可以设计一个函数来决定Op的运行逻辑,也可以让Op直接调用一个能完成该步骤的脚本文件。由于原始项目中已实现了所有步骤,所以本项目可以直接调用对应的脚本文件。
-
编排Op:设计Op之间的数据传递关系。原始项目中,“模型”以读写文件的形式在3个步骤间传递,那么对应的Op之间也应该合理的传递“模型”。以读写本地文件的方式传递,可拓展性较差,且不便于保存和管理”模型”。为了解决这个问题,我们可以利用Pipeline的特性,以输入Artifact和输出Artifact的形式传递”模型“。
关于Artifact:
Artifact是由Op生成的文件,在实际的Pipeline运行过程中,Op的输入和输出是以“Artifact”的形式保存和传递的。
Op在运行前,会从Artifact仓库把对应的文件下载到指定的输入存储路径下;Op在运行完后,会把指定的输出存储路径下的文件上传到Artifact仓库保存。
这样的机制能更科学的管理实验时运行的产出。更具体的描述可参考这里。
另外,我们也可以根据需要对原始项目的脚本进行优化。比如本项目优化了“模型训练”步骤,使它可以基于预训练模型进行训练。
至于具体如何构建Op,以及如何指定Op之间的关系,本文2.3将会介绍。现在我们先看下根据上述的设计思路,最终本项目设计出来的Pipeline的流程是怎样的。
2.2 Pipeline概述
2.2.1 Pipeline流程
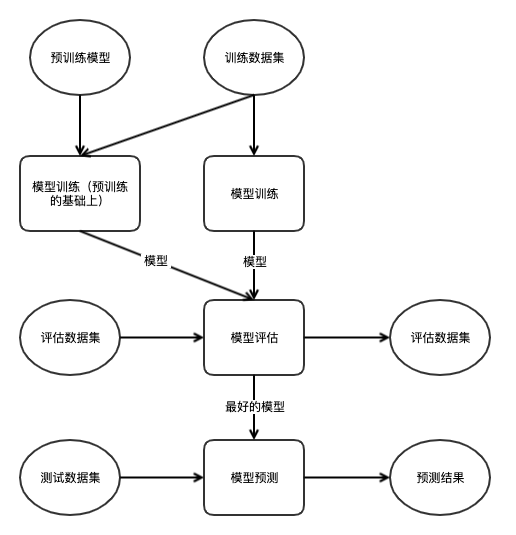
根据上述的Pipeline构建思路,本项目的主要流程如上图所示,整个Pipeline由3类Op组成,分别为“模型训练”Op、“模型评估”Op、“模型预测”Op。
-
首先是“模型训练”Op,该Op的功能是,在指定的训练数据集上,训练一个YOLOv3模型,用户可以指定是否在预训练模型的基础上进行训练。模型训练完后,会保存训练完的模型,并作为输出Artifact传给下游的“模型评估”Op。
-
其次是“模型评估”Op,该Op通过将上游的“模型训练”Op的输出Artifact,即模型,指定为输入Artifact来获取这些训练好的模型。评估所使用的数据集由用户指定。评估阶段会计算每个模型在评估数据集上评估所得到的mAP,并将其写入到日志中。同时,该Op会将最好的模型(暂时规定为mAP最高的模型)保存下来。该模型也将作为输出传给下游的“模型预测”Op。
-
最后是“模型预测”Op,该Op会使用从”模型评估“Op得到的模型,在用户指定的预测数据集上进行预测,最终预测结果会以标注框的形式显示在图像数据上,并保存下来。
2.2.2 文件目录结构
为了更好的理解后面讲到的各个函数的参数的含义,需要先简单浏览一下本案例的文件的目录结构。
可点击链接昆虫检测下载项目代码
bug_detection/
├── bug_detection.ppl
├── dataset
│ ├── test
│ │ └── images
│ │ ├── 1833.jpeg
│ │ ├── 1838.jpeg
│ │ └── ...
│ ├── train
│ │ ├── annotations
│ │ │ └── xmls
│ │ │ ├── 1.xml
│ │ │ ├── 2.xml
│ │ │ └── ...
│ │ └── images
│ │ ├── 1.jpeg
│ │ ├── 2.jpeg
│ │ └── ...
│ └── val
│ ├── annotations
│ │ ├── 1221.xml
│ │ ├── 1277.xml
│ │ └── ...
│ └── images
│ ├── 1221.jpeg
│ ├── 1277.jpeg
│ └── ...
├── pretrained_model
│ └── yolo_epoch50.pdparams
└── script├── anchor_lables.py├── box_utils.py├── calculate_map.py├── darknet.py├── draw_anchors.py├── draw_results.py├── eval.py├── image_utils.py├── insects_reader.py├── map_utils.py├── multinms.py├── predict.py├── reader.py├── train.py└── yolov3.py
如上所示,pipeline.ppl构建了一个Pipeline;数据集存放在dataset文件夹下,预训练模型存放在pretrained_model文件夹下;而script文件夹下存放了Python脚本,这些脚本文件是基于课程中的脚本文件修改的,其中除了主要的train.py、eval.py、preadict.py外,其他的文件主要包含了一些功能函数,它们的主要内容如下所示:
| 文件名 | 主要内容 |
|---|---|
anchor_lables.py | 获取锚框的属性的函数 |
box_utils.py | Bounding Box的相关计算函数,如IoU的计算 |
calculate_map.py | mAP的计算脚本 |
darknet.py | YOLOv3的主干网络的实现 |
draw_anchors.py | 锚框的绘制函数 |
draw_results.py | 预测边框的绘制函数 |
image_utils.py | 训练前对图像数据的处理 |
insects_reader.py | 数据集中数据的解析函数 |
map_utils.py | 计算mAP要用到的功能函数 |
multinms.py | 非极大值抑制的实现 |
reader.py | 数据集中数据的读取函数 |
yolov3.py | YOLOv3模型的实现 |
其中,dataset在第一次运行Pipeline前需要手动解压,在终端运行如下命令即可完成:
cd ~
unzip -d work/bug_detection data/data111732/dataset.zip
2.3 构建Pipeline
想要构建Pipeline,通常需要先完成2个步骤。首先是构建Op,然后是编排Op。
-
构建Op:本项目首先将模型的“训练”、“评估”、“预测”这三个步骤,分别用一个函数进行封装。这些函数会构建并返回一个Op,而Op能完成对应的步骤。本文称这些函数为Op构建函数。
-
编排Op:有了Op之后,本项目定义了一个函数来编排这些Op,确定它们的关系,进而构建Pipeline。本文称该函数为Pipeline函数。
接下来本文将依次讲解Op构建函数和Pipeline函数,这两个函数通常我们会在ppl文件中定义,如本项目的pipeline.ppl文件。
2.3.1 构建Op
如上文所说,我们需要先构建Pipeline需要的Op。
本项目中,有3类Op,“模型训练”Op、“模型评估”Op、“模型预测”Op,它们分别由函数train()、evaluate()、predict()来构建并返回。
train()函数
train()函数的功能是根据参数构建并返回一个"模型训练"Op。该Op会训练一个模型并保存下来。它的代码如下所示:
def train(ds_dir, pretrain_model_path="", output_model_dir="train_output", epoch=1, batch_size=10, device="gpu"):return ScriptOp(name="Model Train Op",command=["python3", "script/train.py"],arguments=["--ds_dir", ds_dir,"--device", device,"--epoch", epoch,"--batch_size", batch_size,"--output_dir", output_model_dir,"--param_path", pretrain_model_path],outputs={"model": output_model_dir})
上述代码调用了ScriptOp的构造函数。通过command参数指定该Op完成“模型训练”这个步骤的方式为“运行train.py脚本”,而train.py的主要功能进行模型训练。
通过arguments参数可以指定传递给command命令的参数,这些参数最终传递给train.py,在运行脚本的时候被使用。具体来说,--ds_dir用来指定训练数据集的存储目录;--output_dir用来指定训练完成后模型保存的目录;而--param_path用来指定预训练模型的存储路径,这个参数是原始项目中所没有的。
而outputs指定了当train.py脚本执行完后,Op会将什么路径下的文件以Artifact的形式上传到Artifact仓库。
ScriptOp参数:
ScriptOp是一个Op类别,这里简单介绍一下ScriptOp的构造函数中比较重要的参数
command:指定Op执行什么样的命令
arguments:传递给command命令的参数
outputs:传递一个dict,其中key为输出的名称,value为一个路径,在Op运行完后,路径下的文件会作为输出,被上传到Artifact仓库关于ScripOp构造函数的参数详解或者其他参数,可以参考Pipeline编排详解
另外,关于上文提到的train.py,本项目在原始项目的基础上进行了优化:支持在通过参数指定预训练模型的基础上进行训练。添加的代码如下所示:
if args.param_path:state_dict = paddle.load(args.param_path)model.load_dict(state_dict)
上述代码的args.param_path就是通过ScritpOp构造函数的arguments传递给command命令,再进而传递给train.py。
除了上述的train()函数的主要逻辑,它的参数列表如下所示:
| 参数名称 | 说明 |
|---|---|
ds_dir | 训练数据集的存储目录。 |
param_path | 预训练模型的参数文件的存放路径,若为空则不使用预训练模型。 |
output_model_dir | 输出模型的存储目录。 |
epoch | 训练时设定的epoch |
batch_size | 训练时设定的batch_size |
device | 训练时使用的硬件设备,如CPU或者GPU |
evaluate()函数
evaluate()函数的功能是根据参数构建并返回一个”模型评估“Op,评估Op的主要功能是,对从上游的“模型训练”Op获取的模型进行评估,评估后会将结果写入日志中,同时评估Op还会将最好的模型以输出Artifact的形式保存下来。
def evaluate(ds_dir, model_inputs, output_model_dir="eval_output", device="gpu"):return ScriptOp(name="Evaluate Op",command=["python3", "script/eval.py"],arguments=["--dataset_dir", ds_dir,"--output_dir", output_model_dir,"--model_names"] + list(model_inputs.keys()),inputs=model_inputs,outputs={"model": output_model_dir})
evaluate()函数构建Op的逻辑和train()函数类似。通过command让Op执行一个脚本,也就是eval.py脚本;通过arguments给命令传递参数。
inputs参数的作用是指定该Op运行时,有哪些数据以输入Artifact的形式传递给Op。在给该参数赋值时,除了指定输入的名称和内容,还可以选择是否指定输入的存放路径。
关于inputs和outputs参数的赋值,更详细的介绍可参考ScriptOp详解
eval.py脚本的主要内容与原始项目中train.py的模型评估部分相似,但有一定优化,优化后的eval.py可以对多个不同的YOLOv3模型进行评估,实现的代码如下所示:
weight_files = []
for name in args.model_names:# 通过环境变量获取Artifact的存储路径# os.getenv(name)的返回值是一个代表路径的字符串,如"./pretrained"weight_files.append(os.getenv(name)+'/param.pdparams')for params_file_path in weight_files:model = YOLOv3(num_classes=NUM_CLASSES)model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()
上述代码中,model_names是通过ScriptOp构造函数的arguments参数传递进来的。这些name的值为环境变量名,环境变量的值为待评估模型对应的Artifact的存储路径。具体原理可参考下面的注释。
关于inputs和outputs生成的环境变量:
在本项目中,所有Op的输入,也就是
inputs,在赋值时都没有指定存放路径,这种情况下,Pipeline会自动生成一个路径用来存放Op的输入。另外,对于所有Op的输入Artifact和输出Artifact,Pipeline会生成环境变量,用来保存这些Artifact的存储路径,用户也就可以通过这些环境变量来获取Artifact的存储路径,进而使用Artifact。环境变量名为Artifact的名称,即赋值时对应的key值。更具体的讲解可查看通过环境变量获取Artifact存储路径
最后,evaluate()函数的参数如下所示:
| 参数名称 | 说明 |
|---|---|
ds_dir | 评估数据集的存储目录。 |
model_inputs | 数据类型为dict,其中key为模型的名称,value为要输入的内容 |
output_model_dir | 输出模型的存储路径。 |
device | 评估时是用的设备,如CPU或GPU。 |
predict()函数
predict()函数的功能是构建并返会一个“模型预测”Op,该Op使用评估得出的最佳模型进行预测,预测的结果会以Bounding Box的形式标注在原图像中,并将标注后的图像保存到指定的目录下。
def predict(ds_dir, model_input, res_save_dir="predict_output", device="gpu"):return ScriptOp(name="Predict Op",command=["python3", "script/predict.py"],arguments=["--image_dir", ds_dir,"--output_dir", res_save_dir],inputs=model_input)
predict()函数构建Op的方式和上述的train()和evaluate类似,其中的command、arguments、inputs参数的功能与前面的用法一致,这里不过多赘述。
predict()函数的参数如下所示:
| 参数名称 | 说明 |
|---|---|
ds_dir | 测试数据集的存储路径。 |
model_input | 待预测模型,必须指定模型的存储路径,读取待预测模型时需要用到。 |
res_save_dir | 预测结果图像保存的目录。 |
device | 预测时使用的硬件设备,如CPU或GPU |
2.3.2 编排Op
有了Op之后,我们就可以通过一个Pipeline函数来编排这些Op。
本项目定义的了如下的pipeline_func函数,该函数可在pipeline.ppl中查看。
def pipeline_func(train_ds_dir="dataset/train", eval_ds_dir="dataset/val",predict_img_dir = "dataset/test/images", device="gpu"):train_op1 = train(ds_dir=train_ds_dir,output_model_dir="train_output/no_pretrained",batch_size=batch_size)train_op2 = train(ds_dir=train_ds_dir,pretrain_model_path="pretrained_model/yolo_epoch50.pdparams",output_model_dir="train_output/pretrained",batch_size=batch_size)eval_op = evaluate(ds_dir=eval_ds_dir, model_inputs={"no_pretrained": train_op1.outputs["model"],"pretrained": train_op2.outputs["model"]},output_model_dir="eval_output")predict_op = predict(ds_dir=predict_img_dir,model_input={"model": eval_op.outputs["model"]},res_save_dir="predict_res")如上代码所示,Pipeline先后调用了3种Op构建函数,分别为train()、evaluate()、predict()。
首先我们调用了两次train()函数,传入不同的参数,先后构建两个“训练”Op,并分别赋值给train_op1和train_op2。这两个训练Op会分别输出两个训练后的模型,其中train_op2是基于预训练模型来训练的。
train_op1和train_op2的下游Op是evaluate()函数构建的eval_op,它对所有从train_op获得的模型进行评估,并将最好的模型作为输出传输到下游的predict_op。
train_op1.outputs["model"]为train_op1中名称为“model”的输出Artifact,这个名称是在train()函数中通过outputs参数指定的。具体原理可参考输出Artifact
predict_op由predict()函数构建,它会使用从上游获得的模型在指定的测试数据集上进行预测,并将结果以图片的形式保存下来。
和普通函数一样,pipeline_func也能传入参数,在本项目中,传入的4个参数中,前3个依次是训练、评估、预测3个数据集的存储路径,最后一个是用来决定运行时是用的是CPU还是GPU。
2.4 运行Pipeline
编排好一个Pipeline后,我们可以尝试运行Pipeline。
在定义了pipeline_func的pipeline.ppl文件中输入如下代码:
Run().create(pipeline_func)
这行代码的主要作用是根据用户定义的Pipeline函数,运行对应的Pipeline,pipeline_func就是本项目定义的Pipeline函数。
本项目默认使用GPU运行,如果环境不支持GPU,请将pipeline_func的device参数设置为"cpu"。
在第一次运行Pipeline前需要手动解压数据集,在终端下运行如下命令即可完成:
cd ~ unzip -d work/bug_detection data/data111732/dataset.zip
2.4.1 在CodeLab运行
我们可以在CodeLab上,选择并跳转到.ppl文件的代码编辑页面,就可以通过界面交互的方式简单快捷的运行Pipeline。
本地调试
可以通过点击“调试”按钮的方式运行Pipeline,如下图所示。
在Pipeline运行时,终端上会先后显示训练的进度、评估的结果、预测的结果,以及其他信息,具体如下所示。
训练Op运行时,终端输出的部分信息:

本地运行
调试过后,如果没有Bug,就可以正常运行了,本地运行和本地调试从结果来看稍有不同,这里暂不展开,有兴趣可以查看本地运行任务。
操作方式如下图所示:

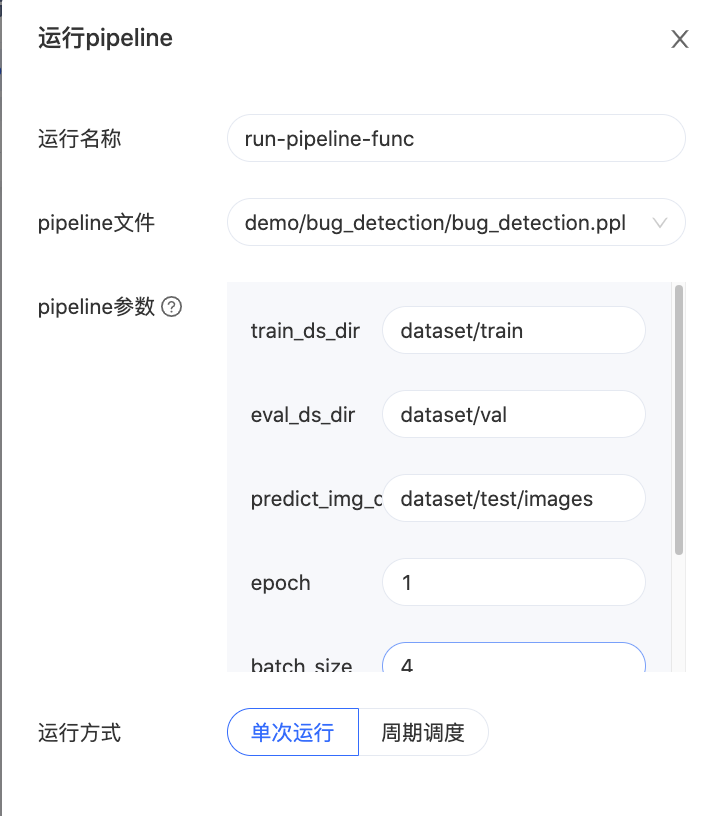
点击运行后,会弹出一个界面,在这个界面可以选择“单次运行”还是“周期运行”。同时还可以指定想要传给Pipeline的参数。具体界面如下图所示:
本地运行的优势之一在于,可以将运行记录保存下来,每一次运行的参数、结果等信息,都会被记录,这有利于用户分析问题,也便于日后的复现。查看运行历史记录的界面在左侧的菜单栏,点击图标即可查看所有的记录。如下图所示:

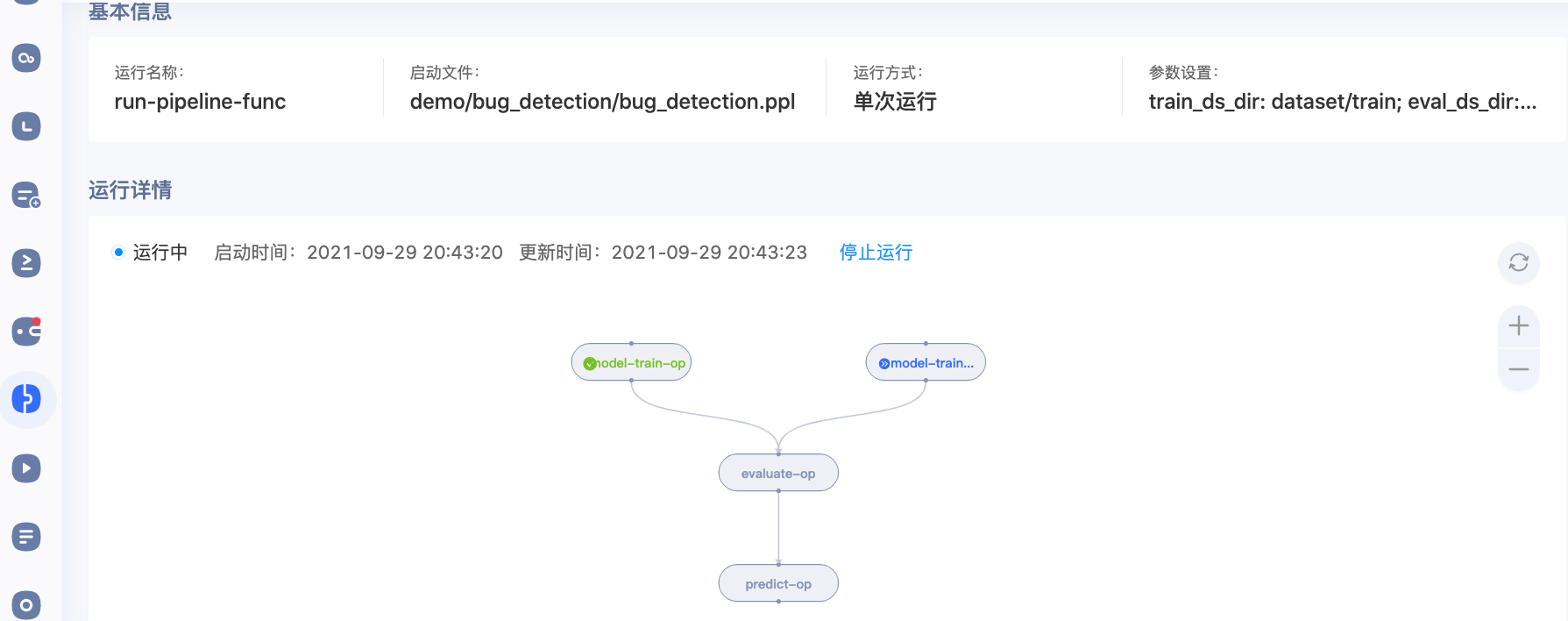
再点击某一条记录,就可以查看详情。详情页面如下所示:
在CodeLab上,还可以在运行前通过可视化的方式查看Op之间的关系和每个Op的相关信息,具体方式可查看可视化
2.4.2 以命令行的方式运行
除了在CodeLab上以界面交互的方式运行,我们也能在终端以命令行的方式运行Pipeline。
输入如下命令可以以本地调试的方式运行:
ppl run create bug_detection.ppl --debug --show-log
其中 bug_detection.ppl就是我们编写Pipeline的文件,--debug表示以调试的方式运行,--show-log会将脚本的输出显示在终端上。
同样,也可以不以调试的模式运行,只需去掉--debug即可,命令如下:
ppl run create bug_detection.ppl --show-log
更多命令行的操作,如查看运行记录等,可查看命令行运行
【Pipeline】林业病虫害防治AI昆虫识别项目
这篇关于【Pipeline】林业病虫害防治AI昆虫识别项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






