pipeline专题

Redis中管道操作pipeline的实现
《Redis中管道操作pipeline的实现》RedisPipeline是一种优化客户端与服务器通信的技术,通过批量发送和接收命令减少网络往返次数,提高命令执行效率,本文就来介绍一下Redis中管道操... 目录什么是pipeline场景一:我要向Redis新增大批量的数据分批处理事务( MULTI/EXE

Jenkins--pipeline版本管理
为了提高脚本可维护性,更好的管理pipeline脚本,我们可以在项目配置中修改流水线定义,使用版本管理脚本,选择pipeline script from SCM: 我们看到现在SCM是无,因为还没有安装版本管理工具,先需要到插件管理中安装git。 安装后,在流水线设置的SCM中就能查看到Git: 在Repository URL中添加版本管理工具github或码云的仓库地址: 在Cred

Jenkins--pipeline认识及与RF文件的结合应用
什么是pipeline? Pipeline,就是可运行在Jenkins上的工作流框架,将原本独立运行的单个或多个节点任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。 为什么要使用pipeline? 1.流程可视化显示 2.可自定义流程任务 3.所有步骤代码化实现 如何使用pipeline 首先需要安装pipeline插件: 流水线有声明式和脚本式的流水线语法 流水线结构介绍 Node:

使用Azure Devops Pipeline将Docker应用部署到你的Raspberry Pi上
文章目录 1. 添加树莓派到 Agent Pool1.1 添加pool1.2 添加agent 2. 将树莓派添加到 Deployment Pool2.1 添加pool2.2 添加target 3. 添加编译流水线3.1 添加编译命令3.2 配置触发器 4. 添加发布流水线4.1 添加命令行4.2 配置artifact和触发器 5. 完成 1. 添加树莓派到 Agent Pool
Netty源码解析3-Pipeline
请戳GitHub原文: https://github.com/wangzhiwubigdata/God-Of-BigData Channel实现概览 在Netty里,Channel是通讯的载体,而ChannelHandler负责Channel中的逻辑处理。 那么ChannelPipeline是什么呢?我觉得可以理解为ChannelHandler的容器:一个Channel包含一个Chan

【人工智能】Transformers之Pipeline(十五):总结(summarization)
目录 一、引言 二、总结(summarization) 2.1 概述 2.2 BERT与GPT的结合—BART 2.3 应用场景 2.4 pipeline参数 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4.3 pipeline返回参数 2.5 pipe

NLP-文本摘要:利用预训练模型进行文本摘要任务【transformers:pipeline、T5、BART、Pegasus】
一、pipeline 可以使用pipeline快速实现文本摘要 from transformers import pipelinesummarizer = pipeline(task="summarization", model='t5-small')text = """summarize: (CNN)For the second time during his papacy, Pope Fr

jenkins pipeline文件使用码云保存
基本步骤如下: 1.在码云新建个空的代码仓库 2.如果使用blue ocean工具编写则将码云仓库地址复制过去,依据编辑器配置即可,保存成功后,会在码云仓库保存编写好的Jenkinsfile文件 3.如果不是使用blue ocean编写的,用其它工具编写,则在Jenkins创建流水线后配置仓库地址即可,如: 对应仓库如下: 说明:pipeline默认的流水线文件名为Jenkinsfile,
【问题解决】Jenkins的Pipeline无法正常后台启动Jar包
文章目录 问题描述排查Jenkins日志启动流水线观察Jar包启动情况初步推测问题问题原因:Jenkins进程管理机制问题解决:改写启动Jar包命令参考文章 问题描述 执行Jenkins的Pipeline,执行结果显示为成功,但是Java程序没有成功启动 排查Jenkins日志 日志中执行的启动Jar包命令为 nohup java -jar /root/jenkins/wo
百日筑基第六十二天-持续集成和持续交付的 pipeline 概念
百日筑基第六十一天-持续集成和持续交付的 pipeline 概念 在软件开发中,Pipeline 是一种自动化的过程,它包括从开发人员提交代码,到代码构建,测试,部署等一系列的步骤。在持续集成(Continuous Integration)/持续部署(Continuous Deployment)领域,Pipeline 是非常重要的,因为它可以帮助开发团队更快,更有效地构建,测试和部署软件。 持

【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
目录 一、引言 二、零样本物体检测(zero-shot-object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipeline(管道)是huggingface trans
Pipeline知识小记
在scikit-learn(通常缩写为sklearn)中,Pipeline是一个非常重要的工具,它允许你将多个数据转换步骤(如特征选择、缩放等)和估计器(如分类器、回归器等)组合成一个单一的估计器对象。这种组合使得数据预处理和模型训练变得更加简洁和高效。 使用Pipeline的主要好处包括: 简化工作流:你可以在一个对象中定义整个数据处理和建模流程。避免数据泄露:在交叉验证或其他评估过程中,P

.NET客户端实现Redis中的管道(PipeLine)与事物(Transactions)(八)
序言 Redis中的管道(PipeLine)特性:简述一下就是,Redis如何从客户端一次发送多个命令,服务端到客户端如何一次性响应多个命令。 Redis使用的是客户端-服务器模型和请求/响应协议的TCP服务器,这就意味着一个请求要有以下步骤才能完成:1、客户端向服务器发送查询命令,然后通常以阻塞的方式等待服务器相应。2、服务器处理查询命令,并将相应发送回客户端。这样便会通过网络连接,如
【Linux】Jenkins Pipeline流水线详解及基于Jenkins流水线实现自动更新项目(实战)
👨🎓博主简介 🏅CSDN博客专家 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支持,我们一起进步!😄 🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗 文章目录 一、Pipeline 流水线的简介1.1 什么

以MixtralForCausalLM为例,演示如何不依赖框架实现pipeline并行
以MixtralForCausalLM为例,演示如何不依赖框架实现pipeline并行 1.创建Mixtral-8x7B配置文件2.测试代码 本文以MixtralForCausalLM为例,演示如何不依赖框架实现pipeline并行 主要步骤: 1.分析网络结构,确定拆分规则: 第一部分:embed_tokens+MixtralDecoderLayer[:8] 第二部分:Mixt
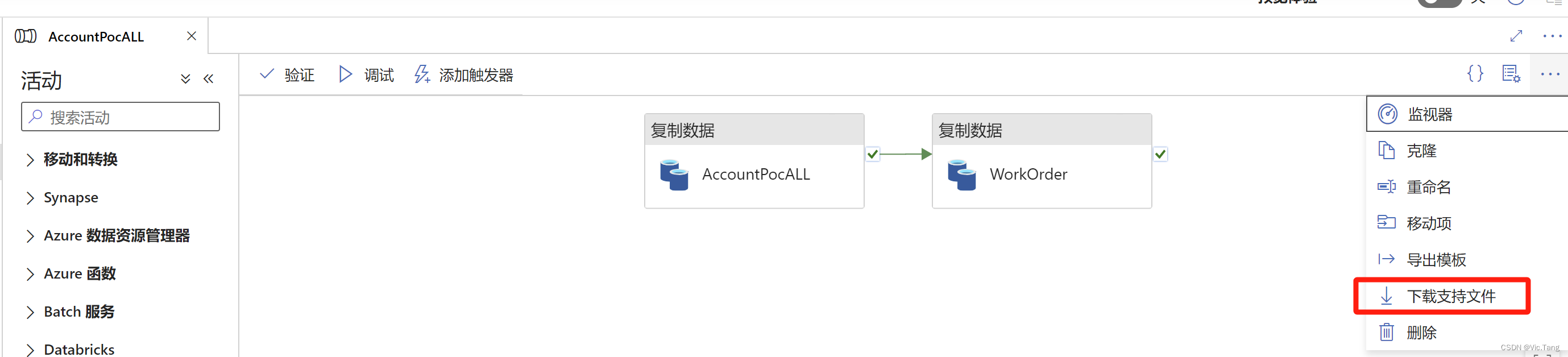
AzureDataFactory 在不同的订阅间迁移Pipeline
前面的博文中的POC是客户向微软申请的试用环境,POC结束客户也购买了Azure订阅,需要复用试用环境中的Pipeline,此时就需要将Pipeline进行迁移。 目之所及有两种方式,第一种是通过导入导出模版,选择需要迁移的Pipeline,导出模版,导出后是一个zip文件 然后再到你的目标环境中选择导入模版,选择刚刚下载的zip文件

docker镜像拉取K8s的calico,Pod报错Init:ImagePullBackOff及kubekey生成离线包报错error: Pipeline[ArtifactExportpipe的解决
配置k8s集群出现问题 起初以为是版本问题,最后比对了一下发现没有问题。使用 kubectl describe calico-node-mg9xh -n kube-system命令查看发现docker pull 镜像失败,但是docker国内镜像源早就配置过了。 猜测Docker的缓存可能会导致拉取镜像失败。尝试删除Docker的缓存,然后重新拉取镜像。但还是失败,网上查了整整一天的时间去折腾

Redis高级特性和应用:慢查询、Pipeline、事务、Lua
Redis提供了许多高级特性,可以帮助优化和管理系统性能。本文将介绍Redis的慢查询、Pipeline、事务和Lua脚本的使用及其相关配置。 Redis的慢查询 慢查询日志是开发和运维人员定位系统慢操作的重要工具。Redis也提供了类似的功能,通过记录超过预设阀值的命令执行时间来帮助诊断性能问题。 Redis客户端执行命令的过程 Redis客户端执行一条命令的过程可以分为以下四个部分:
Pipeline流水线组件
文章目录 1、新建pipeline流水线2、定义处理器3、定义处理器上下文4、pipeline流水线实现5、处理器抽象类实现6、pipeline流水线构建者7、具体处理器实现8、流水线测试9、运行结果 1、新建pipeline流水线 package com.summer.toolkit.model.chain;import java.util.List;import java
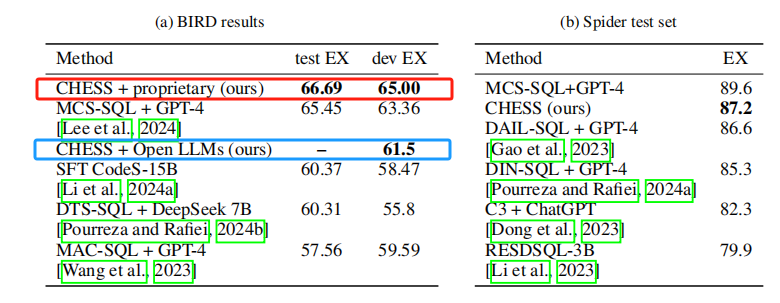
【Text2SQL 论文】CHESS:利用上下文来合成 SQL 的 pipeline
文章目录 一、论文速读二、CHESS pipeline2.1 Entity and Context Retrieval2.2 Schema Selection2.3 Query Generation 三、预处理四、实验五、总结讨论 一、论文速读 本文提出了一个 pipeline 框架——CHESS——来解决应用于复杂的真实数据库场景下的 Text2SQL 问题。 在现实场景下

Jenkins高级篇之Pipeline实践篇-8-Selenium和Jenkins持续集成-添加事后删除报告功能和解决报告名称硬编码
这篇,我们第一件事情来实现把html报告publish完成之后就删除报告文件。这个是很有必要的操作,虽然我们前面写死了报告名称为index.html,你跑多次测试,都会在test-output文件夹下覆盖原来的html报告文件。但是,就像我们最早的时候,报告名称是特定文字加时间戳命名,那么如果不删除,这个test-output下就有多个html文件。 1.代码优化,添加删除报告文件代码 我之前

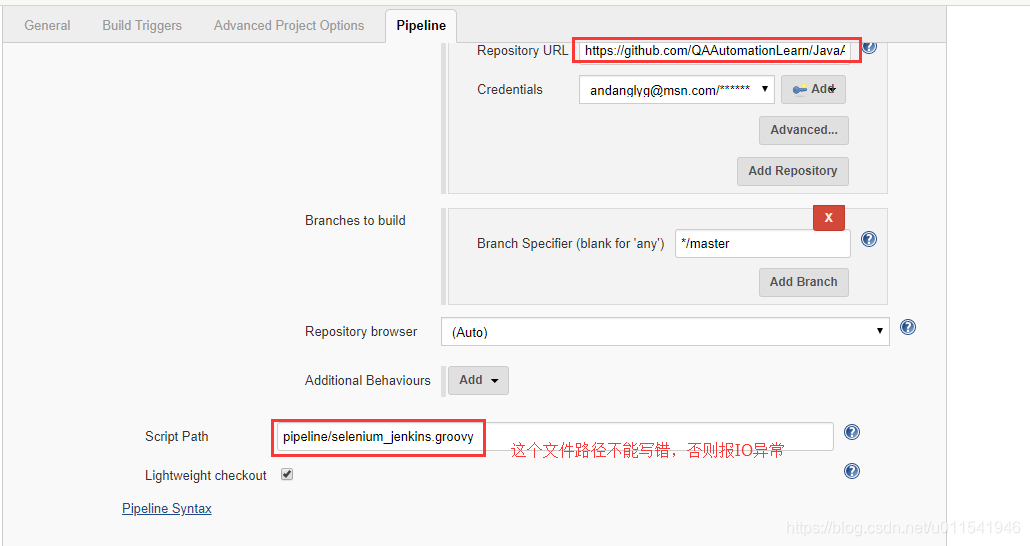
Jenkins高级篇之Pipeline实践篇-7-Selenium和Jenkins持续集成-publish html report插件的pipeline使用介绍
前面我介绍了一个pipeline实现selenium的参数化构建过程,这边我来介绍,如何把我们代码测试之后得到的extent report文件,在Jenkins的构建Job中显示。在介绍之前,我更新下几个和前面代码变化之处。 1)在run.bat中,我们这篇cd的路径是在jenkins salve机器拉取代码的路径,而不是我之前在机器上的git的文件夹下的项目 例如,我配置了一个windows

Jenkins高级篇之Pipeline实践篇-6-Selenium和Jenkins持续集成-pipeline参数化构建selenium自动化测试
这篇来思考下如何写一个方法,可以修改config.properties文件里面的属性。加入这个方法可以根据key修改value,那么我们就可以通过jenkins上变量,让用户输入,来修改config.properties文件里面的值。例如测试服务器地址和浏览器类型的名称。如果用户在Jenkins界面填写浏览器是chrome,那么我们就修改config.properties里面的bro
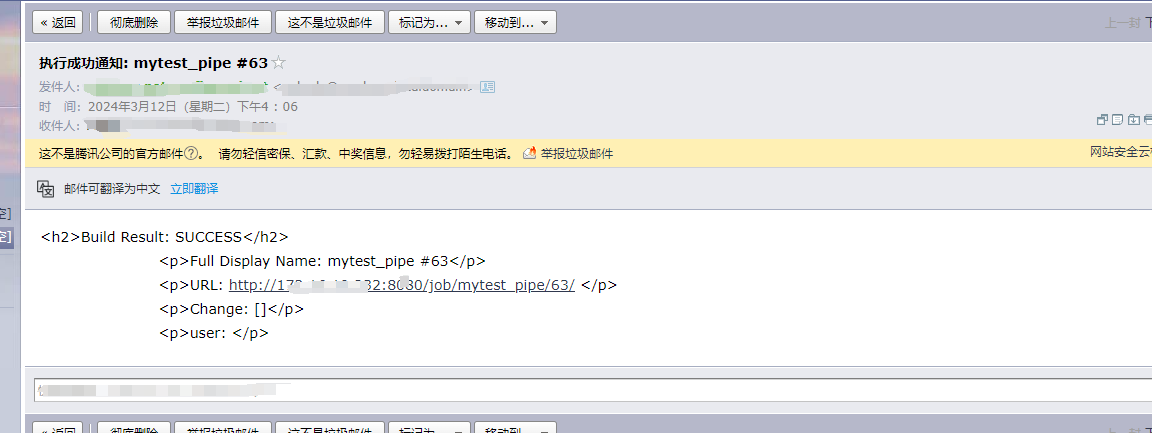
Jenkins高级篇之Pipeline实践篇-5-Selenium和Jenkins持续集成-Pipelinejob草稿版
前面,我们通过在jenkins上创建一个free style job,然后跑起来我们的selenium自动化测试。现在开始,我们要把这种方式给丢弃,采用pipeline的方式,让更多手工配置操作,写入到代码中去。一开始,我们从简单做起,慢慢来。这篇文章的目标就是,创建并成功运行一个pipeline job,先不考虑灵活的变量,我们只考虑如何在pipeline代码中去执行run.bat

Jenkins高级篇之Pipeline实践篇-4-Selenium和Jenkins持续集成-freestyle jenkins job
这篇开始,我打算介绍如何把Selenium自动化测试框架和Jenkins做持续集成。今天这篇很基础,很多人都会,就是在jenkins上创建一个freestyle的job,然后能跑起来Selenium的自动化脚本。这里,我们先来看看市场上大部分同行,是如何实现的。这个介绍完了之后,我们依然要回到pipeline的主线上,用pipeline代码和思维去改变selenium自动化持续集成的方式。 1.