本文主要是介绍【Text2SQL 论文】CHESS:利用上下文来合成 SQL 的 pipeline,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、论文速读
- 二、CHESS pipeline
- 2.1 Entity and Context Retrieval
- 2.2 Schema Selection
- 2.3 Query Generation
- 三、预处理
- 四、实验
- 五、总结讨论
一、论文速读
本文提出了一个 pipeline 框架——CHESS——来解决应用于复杂的真实数据库场景下的 Text2SQL 问题。
在现实场景下,数据库 schema 通常包含不明确的 column name、table name 和混乱的数据,这都对 SQL 转换问题提出了挑战,因此需要一个健壮的检索系统来识别出其中相关的信息。下图展示了一个在做 Text2SQL 时会面临的挑战:
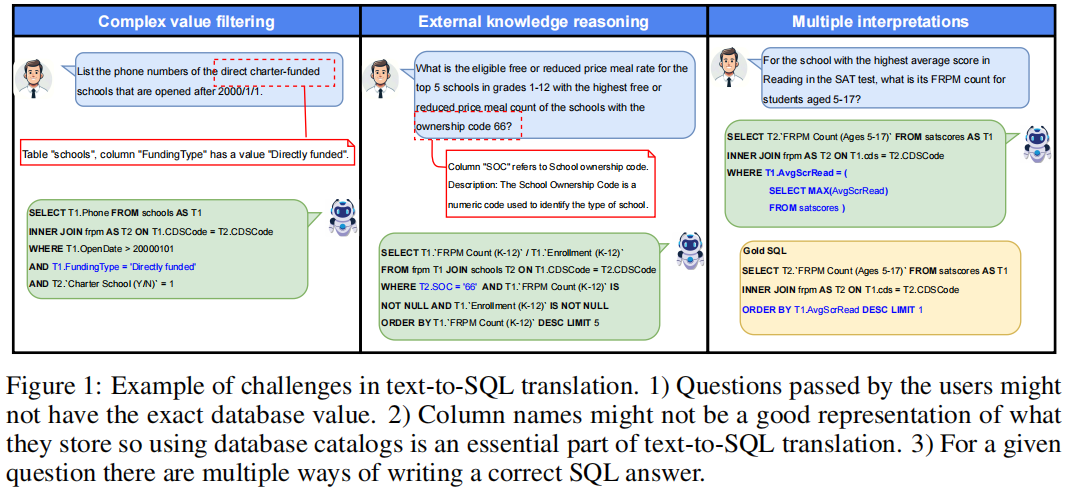
- 1)用户问题可能没有确切的数据库值
- 2)column name 可能不能很好的表示这一列存储了什么数据,因此需要 database catalogs 信息来辅助
- 3)对于一个 question,有多种 SQL 写法
在以往的研究中,大多将 SQL 生成的上下文限制为 table schema、column 定义和 sample rows,但在生产级数据库中,db catelog、db value 也是重要的辅助信息。
本文提出了 CHESS,一个针对现实世界的复杂 DB 的 Text2SQL 系统,它引入了一个 scalable、effective 的 LLM-based 的 pipeline 用于 SQL 生成,主要由三个组件构成:entity and context retrieval、schema selection、SQL generation。
二、CHESS pipeline
CHESS 整个 pipeline 执行的流程如下图所示,共由三个模块组成:
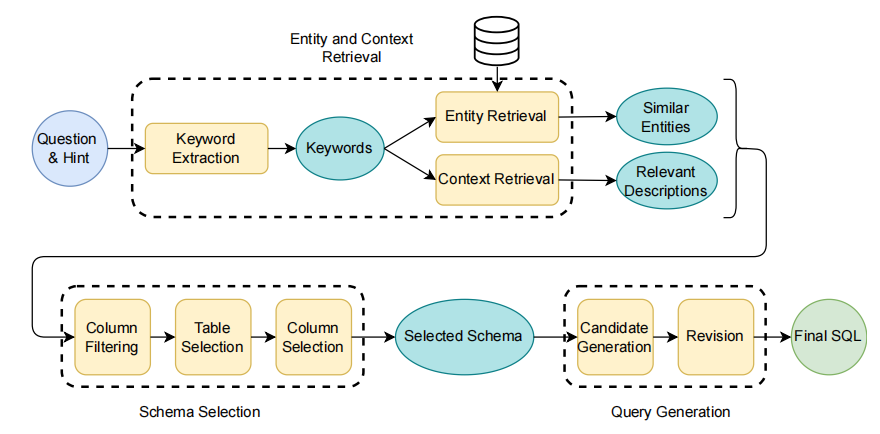
这个流程中有一个需要解决的关键问题是:由于 LLM 上下文窗口的限制,无法将 DB 所有信息都传给 LLM,但 context 又不能缺失有关信息,因此过滤出有用的 DB 信息是需要特别关注的。
2.1 Entity and Context Retrieval
这个 module 需要将 user question 中提及到的相关 entity 和 db schema 提取出来,用于后序步骤的输入。这个过程分成 3 步:
- Keyword Extraction:这一步是从 NL 中提取出 keywords,使用的方法就是 prompt + few-shots ICL 来让 LLM 提取出 keywords、keyphrases、named entities。
- Entity Retrieval:在得到 keyword list 后,我们从数据库中检索相似的值,并为每个 keyword 返回相关的 db cell value,以及对应的 column。这里的检索方法采用了局部敏感哈希(LSH)和 semantic embedding similarity 检索的分层检索策略,从而高效地检索出与 keyword 语法和语义都相似的 cell value。
- Context Retrieval:除了 db cell value,数据库中的 catelogs 包含了解释 db schema 的可用信息(比如注释),这一步使用 vector db 来检索与 keyword 最相似的描述信息。
2.2 Schema Selection
这个 module 是缩小 schema 的范围,使之只包含生成 SQL 时必要的 tables 和 columns。这种过滤后的 schema 称为 efficient schema。这里分为如下步骤:
- Individual Column Filtering:这一步是筛选掉 db 中不相关的 columns,只将最相关的 columns 传递给表选择步骤。实现方式上,是将每个 column 与 question 的相关性视为一个二分类任务,本质上是询问 LLM 该列是否可能与 question 有关。注意,这一步只对移除明显不相关的 columns 有用,之后会再次过滤。
- Table Selection:过滤掉不相关的 columns 之后,这一步继续选择必需的 tables。实现方式是,将前一步过滤的 schema 交给 LLM 来评估 table 与 question 的相关性,并只选择与 SQL 查询所需要的 tables。
- Final Column Selection:从选择出的 tables 中再次过滤 columns,将 schema 减少到生成 SQL 所需的最小列集。实现方式是,prompt LLM 让它评估每一 column 的必要性,包含它的 Chain-of-Thought 的解释。
2.3 Query Generation
前面的步骤已经选出了一个上下文增强的 efficient schema,其中包含了创建 SQL 所需的所有必要信息。下面的步骤中,就是先生成一个候选 SQL,然后对此 SQL 执行并让 LLM 修复其中的语义和语法错误。
- Candidate Generation:通过 prompt LLM 让它生成一个候选 SQL
- Revision:基于 context 和候选 SQL 的执行结果,要求 model 评估 SQL 查询的正确性,并在必要时对其进行修改。具体实现时,可能会给他一套 rules,同时使用 self-consistency 等技巧。
三、预处理
在 CHESS pipeline 中,需要使用 LSH 算法检索和 vector db 检索,因此需要一个预处理过程来为数据库构建检索索引。
四、实验
论文主要在 BIRD 和 Spider 上做了实验,LLM 选择了多种类型进行了对比。
下图是 CHESS 与现有方法的对比:
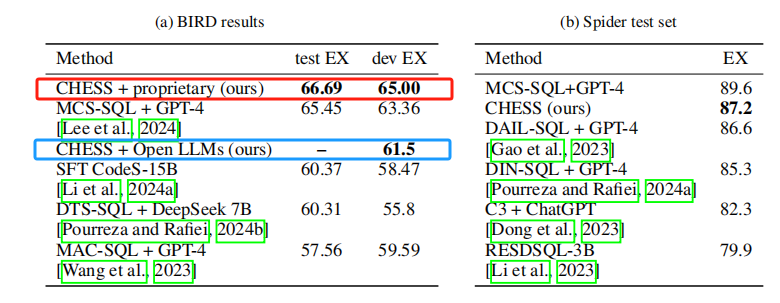
- 红色是 CHESS 框架并使用专用模型,蓝色是使用了开源通用模型
五、总结讨论
CHESS pipeline 在 BIRD 和 Spider 数据集上都取得了不错的表现。此外,CHESS 还开发了一个完全开源的版本,可以私有部署,且在 BIRD 上执行准确率超过 60%,缩小了闭源和开源 LLM 的性能差距,同时保证了企业数据隐私。
但对于 BIRD 数据集,目前的模型仍然不如人类写 SQL 的表现,未来的工作应该旨在进一步缩小这个差距。
此外,设计更高精度的 schema selection 方法是未来研究的一个高影响领域,可以对准确性产生巨大影响。
这篇关于【Text2SQL 论文】CHESS:利用上下文来合成 SQL 的 pipeline的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




