本文主要是介绍【翻译】How to Backdoor Federated Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 标题:如何后门攻击联邦学习
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 联邦学习
- 4. 攻击概述
- A. 威胁模型
- B. 构造攻击模型
- C. 逃避异常检测
标题:如何后门攻击联邦学习
摘要
联邦学习使成千上万的参与者能够构建一个深度学习模型,而无需共享他们的私人训练数据。例如,多部智能手机可联邦训练键盘下一个单词的预测器,而不会透露用户输入的内容。我们证明,联邦学习的任何参与者都可以在l联邦全局模型中引入隐藏的后门功能,例如,为了确保图像分类器将攻击者选择的标签赋给具有某些特征的图像,或者单词预测器使用攻击者选择的单词来完成某些句子。
我们设计并评价了一种新的基于模型替换的模型中毒方法。在一轮联邦学习中被选中的攻击者可以使全局模型在后门任务上立即达到100%的准确性。对于标准的联邦学习任务,我们在不同的假设下对攻击进行了评估,结果表明它的性能大大优于数据中毒。我们的通用约束和规模技术还避免了基于异常检测的防御,将逃逸纳入了攻击者在训练期间的损失函数中。
1. 引言
最近提出的联邦学习[9]、[21]、[27]、[31]是大规模分布式深度学习模式训练的一个很有吸引力的框架。联邦学习使每一轮随机参与者的局部模型平均化,并迅速收敛到精确的全局模型。激励应用程序包括训练图像分类器和用户智能手机上的下一个单词预测器。为了确保敏感训练数据的隐私,并利用范围广泛的非特定于用户的数据分布,设计联邦学习对参与者的本地数据和训练没有可见性。
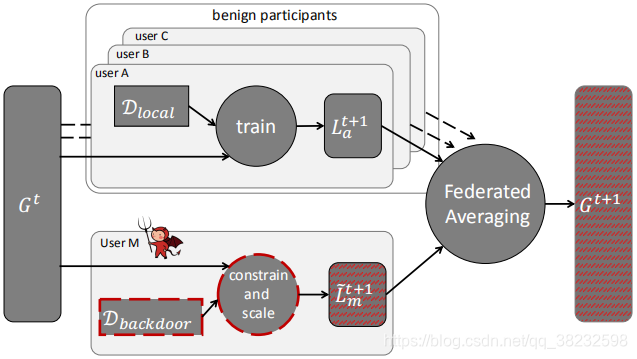
图1:攻击概述。攻击者使一个或多个参与者妥协,使用我们的新的约束和放缩技术对后门数据进行模型训练,并提交结果模型。在联邦平均化之后,全局模型被攻击者的后门攻击的模型所取代。
我们演示了联邦学习使恶意参与者能够在全局模型中引入隐秘的后门功能。图1给出了攻击的高级概述。在每一轮中,中央服务器将当前的全局模型分发给随机选择的参与者。每个参与者在本地进行训练,并向服务器提交一个更新的模型,服务器将更新平均为新的全局模型。
我们设计和评估了一种新的模型替换技术,使控制一个或多个参与者的攻击者能够“后门攻击”全局模型,使得它在攻击者选择的输入上表现不正确。例如,后门攻击的图像分类模型将具有特定特征的图像错误分类给攻击者选择的类;被后门攻击的单词预测模型将攻击者选择的单词预测为特定的句子。我们的攻击方法利用了联邦学习中的观察结果,攻击者可以(1)直接影响全局模型的权重,(2)以任何有利于中毒的方式进行训练,以及(3)将潜在防御的逃避纳入训练期间的损失函数中。
我们从联邦学习文献中展示了我们攻击两项具体学习任务的力量:CIFAR-10图像分类和Reddit语料库中的单词预测。即使是一次单击攻击,攻击者在一轮训练中被选中,也会导致全局模型在后门任务上达到100%的准确性。控制不到1%参与者的攻击者可以阻止全局模型取消对后门的学习,而不会降低其在主要任务上的准确性。我们的攻击大大超过了“传统”数据中毒[13]:总之,80000名参与者的预测任务中,仅牺牲8名就足以达到50%的后门准确率,相比之下,数据中毒攻击需要400名恶意参与者。
我们认为联邦学习从根本上说很容易受到后门攻击。首先,在与数百万参与者进行训练时,不可能确保没有人是恶意的。第二,通过设计进行联邦学习对这些参与者在本地所做的工作没有可见性,而且“安全聚合”[4]显然阻止任何人去审查参与者联邦模型的更新情况。现有的数据中毒防御不能用于联邦学习,因为它们都需要访问训练数据。
对于不使用安全聚合并且审核参与者的贡献的情况,我们演示了一种通用的约束和缩放技术,该技术将逃避合并到攻击者的损失函数中。这使得攻击者能够避开甚至比较复杂的异常检测器,例如那些测量参与者模型和全局模型之间的余弦相似性的异常检测器。我们还开发了一种简单而有效的训练和放缩(train-and-scale)技术,以避开异常检测器,这些异常检测器关注模型的权重[40]或其在主要任务上的准确性。拜占庭式的分布式学习[3]使我们的攻击更加有效。参与者级别的差异隐私[28]部分缓解了攻击,但代价是降低了全局模型对其主要任务的准确性。
造成这一漏洞的根本原因是深度学习模式的大规模过剩。良好的测试准确性表明,模型已经很好地学习了它的主要任务,但是它没有学到什么——比如一个后门的功能被参与到训练模型中的参与者偷偷地引入。
2. 相关工作
对训练数据的攻击。
“传统”中毒攻击损害了训练数据,从而改变了模型在推理时的行为[2]、[17]、[26]、[39]、[44]。
后门攻击只在特定攻击者选择的输入[7]、[13]、[25]上改变模型的行为,而不影响其在主要任务上的性能,通过被backdoor的样本毒害训练数据。在[19]中,一个被backdoor的组件直接插入到模型中。我们表明,数据中毒攻击对联邦学习不起作用,在联邦学习中,攻击者的模型与数百或数千个良性模型聚合在一起。针对中毒的防御措施侧重于从训练数据[38]、[44]或在分布环境下从参与者模型[10]、[40]中移除离异常值。在第六节中,我们解释了为什么这些防御措施对我们的攻击无效。
对测试数据的攻击。
对抗性的例子[11]、[24]、[33]是故意精心设计的,以便被该模型错误分类。相反,后门攻击会导致模型对未经修改的输入进行错误分类-请参阅第IV-A节中的进一步讨论。
安全ML。
安全多方计算可以帮助训练模型,同时保护训练数据的隐私[30],但它不能保护模型的完整性。参与者模型更新的安全聚合[4]使我们的攻击变得更容易,因为不再可能检测异常更新并将它们跟踪到特定的参与者。专门的解决方案,如对加密的垂直分区数据的秘密模型的训练[14],不适用于联邦学习。
参与者级别差异隐私。
差异私有联邦学习[28]限制了每个参与者对联邦模型的影响。在第六-C节中,我们评估了它在多大程度上减轻了我们的攻击。Pate[32],[34]利用知识蒸馏[16]将关于私人数据的“教师”模型中的知识转移到“学生”模型。参与者必须就他们自己的数据集中可能不存在的类标签达成一致,因此Pate可能不适合使用50K字典[28]来执行诸如Nextword预测这样的任务。联邦学习的目的是对与公共数据不同分布的私有数据进行训练。目前还不清楚在没有从与教师私人数据相同的分布中提取未标记的公共数据的情况下,知识转移是如何工作的。
拜占庭容忍的分布式学习。
最近关于拜占庭容忍的联邦学习的工作[3]、[8]、[46]提出了替代聚合机制,以确保在拜占庭参与者的存在下收敛。主要假设是参与者的训练数据为独立同分布的[3]或甚至未经修改和平均分配[8]、[46]。对于联邦学习,这些假设显然是错误的。在第VI-B节中,我们证明了[3]中提出的防御措施使我们的攻击更加强大。


3. 联邦学习
联邦学习[27]通过迭代地将局部模型聚合成一个联合全局模型,将深层神经网络的训练分布在n个参与者之间。动机是效率——N可以是数亿的[27]——隐私也是一样的。本地训练数据永远不会离开参与者的机器,因此联邦模型可以对敏感的私有数据(例如用户的类型消息)进行训练,这些信息与公开可用的信息有很大的不同。OpenMed[31]和分散化ML[9]提供了开放源码软件,使用户能够对其私有数据进行模型训练,并从销售所得的联合模型中分享利润。其他类型的分布式学习包括同步SGD[41],但它是微不足道的后门(见第IV-B节),我们没有进一步考虑它。
在每一轮t中,中央服务器随机选择m参与者的一个子集 S m S_m Sm,并向他们发送当前的全局模型 G t G^t Gt。选择m涉及到训练的效率和速度之间的权衡。每个被选中的参与者通过使用算法1对其私有数据进行训练,将该模型更新为新的本地模型 L t + 1 L^{t+1} Lt+1,并将差异 L i t + 1 − G t L^{t+1}_{i} − G^t Lit+1−Gt发送回中央服务器。通信开销可以通过将随机掩码应用于模型权重[21]减少,但我们忽略了这一优化。中央服务器对接收到的更新进行平均,以获得新的全局模型:
G t + 1 = G t + η n ∑ i = 1 m ( L i t + 1 − G t ) ( 1 ) G^{t+1} = G^t + \frac {\eta} {n} \sum^{m}_{i=1}(L^{t+1}_{i} - G^t) \space \space \space \space \space \space \space(1) Gt+1=Gt+nηi=1∑m(Lit+1−Gt) (1)
全局学习速率η控制每一轮更新的全局模型的部分;如果η=n/m,则模型完全由局部模型的平均值代替。有些任务(如CIFAR-10)需要较低的η才能收敛,而对 n = 1 0 8 n=10^8 n=108个用户的x训练需要更大的η才能使本地模型对全局模型产生任何影响。与同步分布式SGD[6]相比,联邦学习减少了每轮的参与者数量并收敛得更快。经验上,诸如图像分类和单词预测之类的共同任务在少于10000轮中收敛[27]。
联邦学习是在假设参与者的本地训练数据集相对较小并且来自不同分布的情况下明确设计的。因此,局部模型往往过分拟合,偏离全局模型,且精度较低。个别模型的权重也有显着性差异(我们在第VI-A节中进一步讨论了这一点)。平均本地模型平衡他们的贡献,以产生一个准确的全局模型。
4. 攻击概述
联邦学习是将机器学习推向用户的设备的总体趋势的实例,比如电话、智能扬声器、汽车等。联邦学习被设计为与成千上万的用户一起工作,而不限制资格,例如通过注册个人智能手机[12]。类似地,群源ML框架[9],[31]接受任何人运行(可能被修改的)学习软件。
用户设备上的训练模型创建了一个新的攻击面,因为其中一些可能会被破坏。在与数千名用户进行训练时,似乎没有任何现实的方法将敌对参与者排除在外。此外,现有的框架并不能证实训练工作是否正确。受影响的参与者可以提交恶意模型,该模型不仅针对所分配的任务而被训练,而且还包含后门功能。例如,它故意错误地识别某些图像或在其建议中注入不必要的广告。正如我们将要展示的那样,我们很难区分一个被后门攻击的模型和一个经过专门针对用户的私有数据进行训练的良性模型。
A. 威胁模型
攻击者。联邦学习使攻击者完全控制一个或几个参与者,例如智能手机,它的学习软件已被恶意软件破坏。攻击者(1)控制任何受损参与者的本地训练数据(这是整个训练数据的一小部分);(2)控制局部训练过程,可任意改变epoch数、学习率等超参数;(3)在提交模型之前,可以修改模型的权重;最后,(4)能够自适应地将局部训练从一轮改为一轮。
攻击者不控制用于将参与者的更新组合到联合模型中的聚合算法,也不控制在聚合之前或期间使用的异常检测(如果有的话)。过滤掉可疑的模型。此外,攻击者无法控制良性参与者训练的任何方面。我们假设他们通过正确地将联邦学习所规定的训练算法应用于他们的本地训练数据来建立他们的局部模型。
此设置与传统的中毒攻击(参见第二节)之间的主要区别是,后者假定攻击者控制了训练数据的很大一部分。相比之下,在联邦学习中,攻击者控制整个训练过程,但只对一个或几个参与者进行控制。
攻击的目标。攻击者希望联邦学习生成一个全局模型,该模型在其主要任务上收敛并显示出良好的准确性,同时在特定的、攻击者选择的后门输入的任务上也表现出某种特定的方式。相比之下,“传统”数据中毒的目的是改变模型在输入空间[2]、[39]、[44]上的性能,而拜占庭攻击的目的是防止收敛。
有些后门涉及精心制作的输入。例如,Badnet攻击[13]毒害图像分类模型的训练数据,从而学会为所有具有攻击者选择像素图案的图像分配特定的标签。
我们转而关注语义后门。带有语义后门的图像分类模型为所有具有特定自然特征的图像分配攻击者选择的标签,例如,所有带有赛车条纹的汽车都被错误分类为鸟类(或攻击者选择的任何其他标签)。一个被后门攻击的单词预测模型接收一个攻击者选择的单词来完成特定的句子。
攻击者的目标是:(1)全局模型在主要任务和后门任务上都要达到较高的精度;(2)如果不使用安全聚合[4],则由攻击者控制的参与者提交的更新不应该在其他参与者“更新”中显示为异常,因为对于“异常”的任何定义都由中央服务器使用;(3)全球模型应在多次攻击后保持多轮的较高后门准确性。
后门与对抗样本。 对抗性转换利用模型对不同类的表示之间的边界来产生被模型错误分类的输入。相比之下,后门攻击故意改变了这些边界,从而导致某些输入被错误分类。像素图案后门[13]似乎比对抗性转换更弱,因为除了训练时中毒之外,攻击者还必须在推理时修改输入。同样的结果可以通过纯推理时攻击来实现:对输入应用对抗性转换,并导致未经修改的模型对其进行错误分类。然而,语义后门会导致模型错误分类,甚至是攻击者未更改的输入,例如,由良性用户提交的句子或具有特定、自然发生的、图像级别或物理特征(例如某些对象的颜色或属性)的非对抗性图像。因此,模型中的后门漏洞可以超越其众所周知的脆弱性,成为对抗性的例子。
B. 构造攻击模型
简单的方法。攻击者可以简单地在后门攻击的输入上训练其模型。按照[13],每个培训批次应包括正确标记的输入和被添加后门的输入的混合,以帮助模型学会识别差异。攻击者还可以改变本地学习速率和本地epoch数,以最大化对backdoored数据的过拟合。
即使是这种攻击,也立即破坏了同步SGD[41]的分布式学习,后者直接将参与者的更新应用于全局模型,从而引入了后门。然而,在联邦学习中,简单的方法有一个根本的局限性。模型平均抵消了大多数backdoored模型的贡献,而全局模型很快就忘记了后门。攻击者需要经常被选中,即使这样,中毒也是非常缓慢的。在我们的实验中,我们使用简单的方法作为基线。
更换模型。在这种方法中,攻击者雄心勃勃地试图用方程1中的恶意模型X替换新的全局模型 G t + 1 G^{t+1} Gt+1:
X = G t + η n ∑ i = 1 m ( L i t + 1 − G t ) ( 2 ) X = G^t + \frac {\eta} {n} \sum^{m}_{i=1}(L^{t+1}_{i} - G^t) \space \space \space \space \space \space \space (2) X=Gt+nηi=1∑m(Lit+1−Gt) (2)
因为训练数据是独立同分布的,每个本地模型可能远离目前的全局模型。当全局模型收敛时,这些偏差开始抵消,即: ∑ i = 1 m − 1 ( L i t + 1 − G t ) ≈ 0 \sum^{m-1}_{i=1} (L_{i}^{t+1} - G^t) \approx 0 ∑i=1m−1(Lit+1−Gt)≈0。因此,攻击者可以按以下方式解决它需要提交的模型: L ~ m t + 1 = n η X − ( n η − 1 ) G t − ∑ i = 1 m − 1 ( L i t + 1 − G t ) ≈ n η ( X − G t ) + G t \tilde {L}_{m}^{t+1} = \frac {n}{\eta} X - (\frac {n}{\eta} - 1)G^t - \sum_{i=1}^{m-1}(L_{i}^{t+1} - G^t) \approx \frac{n}{\eta}(X - G^t) + G^t L~mt+1=ηnX−(ηn−1)Gt−i=1∑m−1(Lit+1−Gt)≈ηn(X−Gt)+Gt
直观地,这种攻击通过 γ = n η \gamma = \frac{n}{\eta} γ=ηn增加了backdoored的模型X的权重,以确保后门能够在平均中存活,全局模型被X取代。这种攻击在任何一轮联邦学习中都有效,但在以后几轮中,当全局模型接近收敛时更有效。我们在V-F节中进一步讨论了这一点。
在[3]中提到了模型替换的可行性,其中攻击者的目标是防止收敛。在第VI-B节中,我们证明了[3]中提出的防御措施并没有阻止我们的攻击,而是使我们的攻击更加强大。
不知道n和η的攻击者可以通过每轮迭代增加缩放因子 γ \gamma γ并在后门任务上测量模型的精度来近似找到一个合适的值。 γ < n η \gamma < \frac{n}{\eta} γ<ηn的扩展不能完全取代全局模型,但攻击仍然达到了很好的后门准确率。我们在V-G节中进一步讨论了这一点。
模型替换确保攻击者的贡献在平均中存活并转移到全局模型。这是单次性攻击(single-shot attack):全局模型在被毒化后立即显示出在后门任务上的高精度。


C. 逃避异常检测
联邦学习的最新建议使用安全聚合[4]。它可驱动地防止聚集器检查参与者提交的模型。通过安全聚合,无法检测到聚合是否包含恶意模型,也无法检测是谁提交了此模型。如果没有安全聚合,中央服务器聚合参与者的模型可能会尝试筛选出“异常”贡献。因为使用等式3创建的模型的权重明显扩大,这类模型似乎很容易发现和过滤。然而,联邦学习的主要动机是利用非独立同分布的训练数据的参与者的多样性,包括不寻常或低质量的本地数据,如智能手机照片或短信历史[27]。因此,通过设计,聚合器应该接受本地的模型,即使这些模型的准确性很低,并且与当前的全局模型有很大的不同。在第VI-A节中,我们具体地展示了良性参与者模型的相当广泛的分布如何使攻击者能够创建不出现异常的backdoored的模型。
更新中…
这篇关于【翻译】How to Backdoor Federated Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!