本文主要是介绍(一)《The Application of Hidden Markov Models in Speech Recognition》论文学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ABSTRACT:
隐马尔可夫模型(HMMs)为时变谱向量序列建模提供了一个简单有效的框架。因此,目前几乎所有的大词汇量连续语音识别(LVCSR)系统都是基于HMM的。虽然基于HMM的大词汇量连续语音识别的原理很简单,但是直接应用的话,会造成非常低的准确率并且对于改变操作环境的敏感度特别差。这篇综述的目的是首先提出基于HMM的LVCSR系统的核心架构,然后描述实现最先进性能所需的各种改进。这些改进包括特征投影、改进的协方差建模、鉴别参数估计、自适应和归一化、噪声补偿和多通道系统组合。文章最后以广播新闻与新闻产业的LVCSR为例进行了分析
对话记录,以说明所描述的技巧。
INTRODUCTION:
自动连续语音识别有很多潜在的应用,包括命令、听写、转译等等。而所有语音识别系统的核心都由一组统计模型组成,这些模型代表了被识别语言的各种声音。因为语音有时序结构并且能被编码为一组横跨音频范围的谱向量的序列,隐马尔可夫模型为建造这种模型提供了一种很自然的框架。虽然过去十多年的基本框架没怎么重大变化,但是在这个框架中开发的详细建模技术已经发展的贼复杂。上世纪80年代受限于计算能力,语音识别系统停留在离散词说话者依赖的大词汇系统或者全词小词汇说话者独立应用。在九十年代初期,关注点转到了连续非特定人识别。
Architecture of an HMM-Based Recogniser:
大型连续性语音识别器最主要的组件如下图:

语音信号作为输入从麦克风被转换成固定尺寸的声学向量的序列 Y 1 : T = y 1 , y 2 , . . . , y T Y_{1:T} =y_1,y_2,...,y_T Y1:T=y1,y2,...,yT,这个过程就是特征抽取。解码器随后寻找最佳匹配的词汇 W 1 : L = w 1 , w 2 , . . . , w L W_{1:L} =w_1,w_2,...,w_L W1:L=w1,w2,...,wL的序列,生成最可能的 Y Y Y,也就是编码器试图找到 w ^ = a r g m a x w P ( w ∣ Y ) ( 2.1 ) \hat{w}= \mathop{argmax}\limits_w {P(w|Y )} (2.1) w^=wargmaxP(w∣Y)(2.1)。但是直接建模 P ( w ∣ Y ) P(w|Y) P(w∣Y)很困难,使用贝叶斯规则将2.1公式转换为 w ^ = a r g m a x w p ( Y ∣ w ) P ( w ) ( 2.2 ) \hat{w}= \mathop{argmax}\limits_w{p(Y |w)P(w)} (2.2) w^=wargmaxp(Y∣w)P(w)(2.2), P ( Y ∣ w ) P(Y|w) P(Y∣w)的可能性由声学模型决定, P ( w ) P(w) P(w)的可能性由语言模型所决定。(在实际应用中,声学模型是不归一化的,语言模型通常是由经验确定的常数和添加一个词插入惩罚,即在对数域中,总似然被计算为 l o g P ( Y ∣ w ) + α l o g ( P ( w ) ) + β ∣ w ∣ log P(Y |w) + αlog(P(w)) + β|w| logP(Y∣w)+αlog(P(w))+β∣w∣,其中 α α α的范围通常是 8 − 20 8-20 8−20,而 β β β的范围通常是 0 − 20 0-20 0−20。声学模型所代表的声音的基本单位是音素,例如,"bat"是由音素 / b / / a e / / t / /b/ /ae/ /t/ /b//ae//t/,英语需要这样的40个音素。对于任何给定的 w w w,相应的声学模型通过连接音素模型来合成单词,如发音字典所定义的那样。这些音素模型的参数是由语音波形及其正字法转录组成的训练数据估计的。语言模型通常是一个 N − g r a m N-gram N−gram模型,其中每个单词的概率只取决于它的 N − 1 N- 1 N−1祖先。通过统计适当文本语料库中的 N N N组来估计 N N N元组参数。解码器通过使用修剪来搜索所有可能的单词序列,以删除不可能的假设,从而保持搜索的可处理性。当到达话语的末尾时,输出最有可能的词序列。另外,现代解码器可以生成包含最可能假设的紧凑表示的格。
以下部分将更详细地描述这些流程和组件:
2.1 特征提取
特征提取目的是提供一个紧凑的语音波形,这种方式应当降低识别词间的信息损失,并提供一种声学模型的分布假设的良好匹配方式。例如,如果状态输出分布使用对角协方差高斯分布,那么特征应该设计为高斯和不相关。特征向量差不多是一个 25 m s 25ms 25ms重叠的分析窗,每 10 m s 10ms 10ms计算一次。最简单和最广泛使用的编码方案之一是基于 梅尔频率倒频谱系数 (MFCCs) \textrm{梅尔频率倒频谱系数}\textit{(MFCCs)} 梅尔频率倒频谱系数(MFCCs)的编码方案。这些是通过将截断的离散余弦变换 (DCT) \textit{(DCT)} (DCT)应用到 对数谱估计 中生成的,该 对数谱估计 是通过平滑快速傅里叶变换 (FFT) \textit{(FFT)} (FFT)计算得到的, FFT \textit{FFT} FFT约有20个 frequency bin \textit{frequency bin} frequency bin在语音谱中呈非线性分布。所使用的非线性频率尺度被称为梅尔尺度,它近似于人耳的响应, DCT \textit{DCT} DCT被应用是为了平滑谱估计并且对特征元素进行近似去相关处理。余弦转换之后,第一个元素代表 frequency bin \textit{frequency bin} frequency bin的对数能量的平均值。有时被帧的对数能量所取代或者完全去掉。
(注释:) \textit{(注释:)} (注释:)
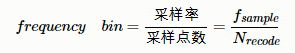

进一步的心理声学约束被纳入到一个相关的编码中,称为知觉线性预测 ( P L P ) (PLP) (PLP), P L P PLP PLP从感知加权非线性压缩功率谱计算线性预测系数,然后将线性预测系数转换为倒谱系数。实践中, P L P PLP PLP比 M F C C MFCC MFCC强一丢丢,尤其在有噪环境,因此它在很多系统中是更合适的编码选择。除了频谱系数外,一阶 ( d e l t a ) (delta) (delta)和二阶 ( d e l t a − d e l t a ) (delta - delta) (delta−delta)回归系数通常被附加在摸索性的尝试中,以补偿基于 H M M HMM HMM的声学模型的条件独立假设。如果原始特征向量是 y t s y^s_t yts,则 d e l t a delta delta参数 Δ y t s \Delta y_t^s Δyts由公式2.3给出。
∑ i = 1 n w i ( y t + i s − y t − i s ) 2 ∑ i = 1 n w i 2 . ( 2.3 ) \frac{\sum_{i=1}^{n}w_{i}(y_{t+i}^{s}-y_{t-i}^{s})}{2\sum_{i=1}^{n}w^2_i}. (2.3) 2∑i=1nwi2∑i=1nwi(yt+is−yt−is).(2.3)
n n n是窗口的宽度, w i w_i wi是回归系数, d e l t a − d e l t a delta-delta delta−delta参数 Δ 2 y t s T \Delta^2{y_t^s}^T Δ2ytsT以同样的方式产生,但是使用不同的 d e l t a delta delta参数,把他们连在一起,就成了特征向量 y t y_t yt
y t = [ y t s Δ y t s Δ 2 y t s ] T . ( 2.4 ) y_t = {[y_t^s \quad \Delta{y_t^s}\quad \Delta^2y_t^s]}^T. (2.4) yt=[ytsΔytsΔ2yts]T.(2.4)
最终的结果是一个特征向量,其维度数量通常在40左右,并且已经部分而不是完全去相关。
2.2 HMM声学模型 (Basic-Single Component)
如上所述,每个口语单词 w w w被分解为一个序列 K w K_w Kw的基本声音,被称为基本音素。这个序列被称为发音 q 1 : K w ( w ) = q 1 , . . . , q K w q_{1:K_w}^{(w)}=q_1,...,q_{K_w} q1:Kw(w)=q1,...,qKw。考虑到多个发音的可能性,可以通过多个发音来计算可能性 p ( Y ∣ w ) p(Y |w) p(Y∣w)。
p ( Y ∣ w ) = ∑ Q p ( Y ∣ Q ) P ( Q ∣ w ) ( 2.5 ) p(Y|w)=\sum_Qp(Y|Q)P(Q|w) \qquad(2.5) p(Y∣w)=Q∑p(Y∣Q)P(Q∣w)(2.5)
其中对w的所有有效发音序列求和,Q是一个特定的发音序列,
P ( Q ∣ w ) = ∏ l = 1 L P ( q w l ∣ w l ) ( 2.6 ) P(Q|w)=\prod^L_{l=1}P(q^{w_l}|w_l)\qquad(2.6) P(Q∣w)=l=1∏LP(qwl∣wl)(2.6)
其中每个 q ( w l ) q^{(w_l)} q(wl)是词汇 w l w_l wl的一个有效发音。在实践中,对于每个 w l w_l wl只有非常少的替代发音,使得 ( 2.5 ) (2.5) (2.5)中的求和容易处理。
每个基础音素 q q q由图2.2所示形式的连续密度 H M M HMM HMM表示,其转移概率参数 { a i j } \{a_{ij}\} {aij}和输出观测分布 { b j ( ) } \{b_j ()\} {bj()}。在操作中, H M M HMM HMM每次都从当前状态转移到其中一个连接状态。从状态 s i s_i si到 s j s_j sj的特定转移概率由转移概率 a i j {a_{ij}} aij决定。进入状态时,使用与所进入状态相关联的分布 b j ( ) {b_j()} bj()生成特征向量。这种形式的过程产生了一个 H M M HMM HMM的标准条件独立性假设。
- 当前状态有条件地独立于其他所有已给状态
- 观察状态有条件地独立于其他所有生成的观察状态
更多关于 H M M HMM HMM的细节请参考《 L. R. Rabiner, “A tutorial on hidden Markov models and selected applications
in speech recognition,” Proceedings of IEEE, vol. 77, no. 2, pp. 257–286, 1989.》也可以看我的论文详解,点我传送
输出分布假设为单多元高斯函数:
b j ( y ) = N ( y ; μ ( j ) , ∑ ( j ) ) ( 2.7 ) b_j(y)=N(y;μ^{(j)},\sum\nolimits^{(j)})\qquad(2.7) bj(y)=N(y;μ(j),∑(j))(2.7)
其中 μ ( j ) μ^{(j)} μ(j)是状态 s j s_j sj的平均值并且 ∑ ( j ) \sum\nolimits^{(j)} ∑(j)是它的协方差。因为声学向量 y y y的维度数量比较高,协方差通常转换成对角的。随后在 HMM Structure Refinements \textit {HMM\ \textit{Structure}\ Refinements} HMM Structure Refinements详细讨论使用混合高斯模型的好处。
给定由所有组成的基本音素 q w 1 , . . . , q w l q^{w_1},...,q^{w_l} qw1,...,qwl拼接而成的复合 H M M Q HMM\ Q HMM Q,则声音似然由公式2.8给出:
p ( Y ∣ Q ) = ∑ θ p ( θ , Y ∣ Q ) ( 2.8 ) p(Y|Q)=\sum_\theta p(\theta,Y|Q)\qquad(2.8) p(Y∣Q)=θ∑p(θ,Y∣Q)(2.8)
其中 θ = θ 0 , . . . , θ T + 1 \theta=\theta_0,...,\theta_{T+1} θ=θ0,...,θT+1是一个状态序列通过合成模型得到,并且
p ( θ , Y ∣ Q ) = α θ 0 θ 1 ∏ t = 1 T b θ t ( y t ) α θ t θ t + 1 ( 2.9 ) p(\theta,Y|Q)=\alpha_{\theta_0\theta_1}\prod^T_{t=1}b_{\theta_t}(y_t)\alpha_{\theta_t\theta_{t+1}}\qquad(2.9) p(θ,Y∣Q)=αθ0θ1t=1∏Tbθt(yt)αθtθt+1(2.9)
在这个等式中, θ 0 \theta_0 θ0和 θ T + 1 \theta_{T+1} θT+1对应图2.2所示的非发射进入和退出状态,这些是为了简化连接音素模型形成单词的过程。简单起见,这些非发射状态将被忽略,关注点将聚焦于状态序列 θ 1 , . . . , θ T \theta_1,...,\theta_T θ1,...,θT。
声学模型参数 λ = [ { a i j } { b i j } ] \lambda=[\{a_{ij}\}\{b_{ij}\}] λ=[{aij}{bij}]可以通过大量前向算法的训练文本被有效预测,前向算法是最大期望值算法 ( E M ) (EM) (EM)算法的一个例子。对于每个句子 Y ( r ) , r = 1 , . . . , R Y^{(r)}, r=1,...,R Y(r),r=1,...,R,基本形式的序列长度 T ( r ) T^{(r)} T(r),对应话语中的单词序列 H M M s HMMs HMMs已经发现,并且相应的复合 H M M HMM HMM被建立。在算法的第一阶段,第E步,前向概率 α t ( r j ) = p ( Y 1 : t ( r ) , θ t = s j ; λ ) \alpha^{(rj)}_t=p(Y^{(r)}_{1:t},\theta_t=s_j;\lambda) αt(rj)=p(Y1:t(r),θt=sj;λ)并且反向概率 β t ( r j ) = p ( Y t + 1 : T ( r ) ( r ) ∣ θ t = s i ; λ ) \beta_t^{(rj)}=p(Y^{(r)}_{t+1:T^{(r)}}|\theta_t=s_i;\lambda) βt(rj)=p(Yt+1:T(r)(r)∣θt=si;λ)通过下述公式递归求得:
α t ( r j ) = [ ∑ i α t − 1 ( r i ) α i j ] b j ( y t ( r ) ) ( 2.10 ) \alpha_t^{(rj)}=\lbrack \sum_i\alpha_{t-1}^{(ri)}\alpha_{ij} \rbrack b_j (y_t^{(r)})\qquad(2.10) αt(rj)=[i∑αt−1(ri)αij]bj(yt(r))(2.10)
β t ( r i ) = [ ∑ j a i j b j ( y t + 1 ( r ) ) β t + 1 r j ] ( 2.11 ) \beta_t^{(ri)}=\lbrack \sum_j a_{ij}b_j(y_{t+1}^{(r)})\beta_{t+1}^{rj} \rbrack\qquad(2.11) βt(ri)=[j∑aijbj(yt+1(r))βt+1rj](2.11)其中 i i i和 j j j对所有状态求和。在执行这些递归时,长语音段可能会出现向下溢出,因此在实践中存储对数概率,并使用对数算法来避免这个问题(我觉得就是因为在数据量越来越大的时候,使用log可以极大的降低运算率,并且不会造成溢出)。
给定前向和反向概率,模型在t时刻任意给定话语r,占据状态 s j s_j sj的概率为
γ t ( r j ) = P ( θ t = s j ∣ Y ( r ) ; λ ) = 1 P ( r ) α t ( r j ) β t ( r j ) ( 2.12 ) \gamma_t^{(rj)}=P(\theta_t=s_j|Y^{(r)};\lambda)=\frac{1}{P^{(r)}}\alpha_t^{(rj)}\beta_t^{(rj)}\qquad(2.12) γt(rj)=P(θt=sj∣Y(r);λ)=P(r)1αt(rj)βt(rj)(2.12)
其中 P ( r ) = p ( Y ( r ) ; λ ) P^{(r)}=p(Y^{(r)};\lambda) P(r)=p(Y(r);λ)。这些状态的占用概率,也称为占用数,表示模型状态与数据的软对齐,并且它很容易证明新的高斯参数集定义为
μ ^ ( j ) = ∑ r = 1 R ∑ t = 1 T ( r ) γ t ( r j ) y t ( r ) ∑ r = 1 R ∑ t = 1 T ( r ) γ t ( r j ) ( 2.13 ) \hat{\mu}^{(j)}=\frac{\sum_{r=1}^R\sum_{t=1}^{T^{(r)}}\gamma_t^{(rj)}y_t^{(r)}}{\sum_{r=1}^R\sum_{t=1}^{T^{(r)}}\gamma_t^{(rj)}}\qquad(2.13) μ^(j)=∑r=1R∑t=1T(r)γt(rj)∑r=1R∑t=1T(r)γt(rj)yt(r)(2.13)
∑ ^ ( j ) = ∑ r = 1 R ∑ t = 1 T ( r ) γ t ( r j ) ( y t ( r ) − μ ( j ) ^ ) ( y t ( r ) − μ ( j ) ^ ) T ∑ r = 1 R ∑ t = 1 T ( r ) γ t ( r j ) ( 2.14 ) \hat{\sum}^{(j)}=\frac{\sum_{r=1}^R\sum_{t=1}^{T^{(r)}}\gamma_t^{(rj)}(y_t^{(r)}-\hat{\mu^{(j)} }) ( y_t^{(r)}-\hat{\mu^{(j)} } )^T }{\sum_{r=1}^R\sum_{t=1}^{T^{(r)}}\gamma_t^{(rj)}}\qquad(2.14) ∑^(j)=∑r=1R∑t=1T(r)γt(rj)∑r=1R∑t=1T(r)γt(rj)(yt(r)−μ(j)^)(yt(r)−μ(j)^)T(2.14)
在给定这些数据对齐的情况下最大似然估计。对于转移概率,可以推导出类似的再估计方程
∑ ( r = 1 ) R 1 P ( r ) ∑ t = 1 T ( r ) α t ( r i ) a i j b j ( y t + 1 r ) β t + 1 ( r j ) y r ( r ) ∑ r = 1 R ∑ t = 1 T ( r ) γ t ( r j ) ( 2.15 ) \frac{ \sum^R_{(r=1)} \frac{1}{P^{(r)}} \sum_{t=1}^{T^{(r)}} \alpha_t^{(ri)} a_{ij} b_j (y_{t+1}^r) \beta_{t+1}^{(rj)} y_r^{(r)}}{ \sum_{r=1}^R\sum_{t=1}^{T^{(r)}}\gamma_t^{(rj)} }\qquad(2.15) ∑r=1R∑t=1T(r)γt(rj)∑(r=1)RP(r)1∑t=1T(r)αt(ri)aijbj(yt+1r)βt+1(rj)yr(r)(2.15)
这是算法的第二或第 M M M步。从一些参数的初始化估计开始, λ ( 0 ) \lambda^{(0)} λ(0), E M EM EM算法的连续迭代得到参数集 λ ( 1 ) , λ ( 2 ) , . . . \lambda^{(1)},\lambda^{(2)},... λ(1),λ(2),...,这将保证将可能性提升到某个最大值。对于初始化参数 λ ( 0 ) \lambda^{(0)} λ(0)的一个通用选择是分配全局均值,数据到高斯输出分布的协方差并且设置所有转移概率相等。也就是所谓的平启动模式。
这种声学建模的方法通常被称为串珠模型,之所以这样说是因为所有的语音都是由一连串的音素模型连接在一起。这样做的主要问题是,将每个词汇分解成一系列与上下文无关的基础音素,并不能捕捉到真实语音中存在的很大程度上与上下文相关的变化。例如, “ m o o d ” “mood” “mood”和 “ c o o l ” “cool” “cool”的基本形式发音会对 “ o o ” “oo” “oo”使用相同的元音,但在实践中,由于前辅音和后辅音的影响, “ o o ” “oo” “oo”在两种语境中的实现是非常不同的。上下文无关的音素模型被称为单音素。
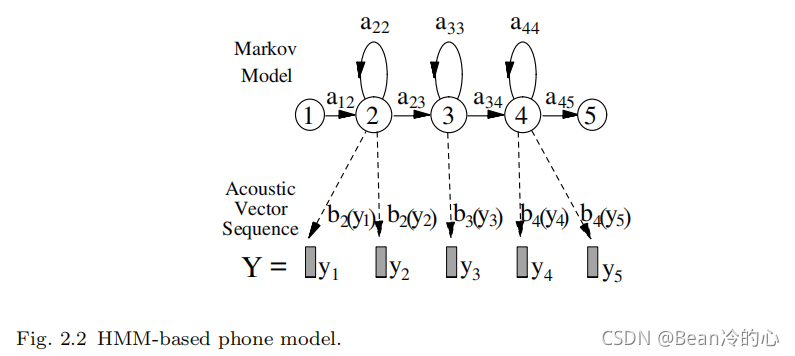
减轻这个问题的一个简单方法是对每一对可能的左右邻居使用一个单音素模型,结果模型被称为三音素,如果有 N N N个基音素,就有 N 3 N^3 N3个潜在音素。为了避免由此产生的数据稀疏性问题,可以通过聚类并将每个聚类中的参数捆绑在一起,将完整的逻辑三音素L映射到一个简化的物理模型集 P P P。映射过程如图 2.3 2.3 2.3,参数捆绑如图 2.4 2.4 2.4,其中 x − q + y x−q + y x−q+y表示在前一个音素 x x x和后一个音素 y y y的上下文中与音素 q q q对应的三音位。

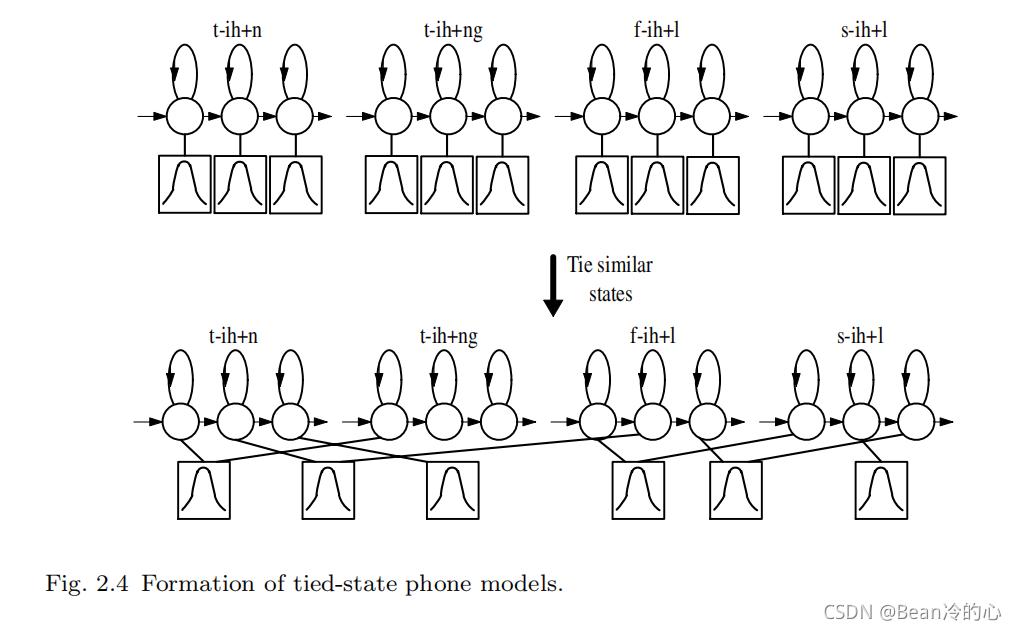
每个基本音素发音 q q q是由简单发音词典查表得到的,然后根据上下文将其映射到逻辑音素。最后将逻辑音素映射到物理模型。请注意,上下文依赖关系跨越单词边界,这对于捕捉许多重要的语音过程至关重要。例如, “ s t o p t h a t ” “stop \ that” “stop that”中的 / p / /p/ /p/的爆破音被后面的辅音抑制了。
逻辑模型到物理模型的聚类通常操作到状态级而不是模型级,因为这样更简单并且允许健壮地估计更大的物理模型。通常采用决策树来选择连接哪些状态。每个音素 q q q的每个状态位置都有一个与之相关的二叉树。树的每个节点都带有一个关于上下文的问题。为了聚集音素 q q q的状态 i i i,将从 q q q派生的所有逻辑模型的所有状态 i i i收集到树的根节点的单个池中。根据每个节点上问题的答案,状态池将依次分割,直到所有状态都向下延伸到叶节点。然后,每个叶节点中的所有状态都被绑定成一个物理模型。每个节点上的问题都是从预先确定的集合中选择的,以最大限度地提高给定最终状态连接集的训练数据的可能性。如果状态输出分布是单分量的,在已知高斯数和状态占用数的情况下,无需参考训练数据,只需根据计数和模型参数简单计算任意节点的高斯数和状态占用数的分割所获得的似然增加。因此,使用贪婪迭代节点分割算法可以非常有效地生长决策树。图 2.5 2.5 2.5演示了这种基于树的集群。在图中,逻辑音素 s − a w + n s-aw+n s−aw+n和 t − a w + n t-aw+n t−aw+n都将被分配给叶节点3,因此它们将共享具有代表性的物理模型的相同中心状态。
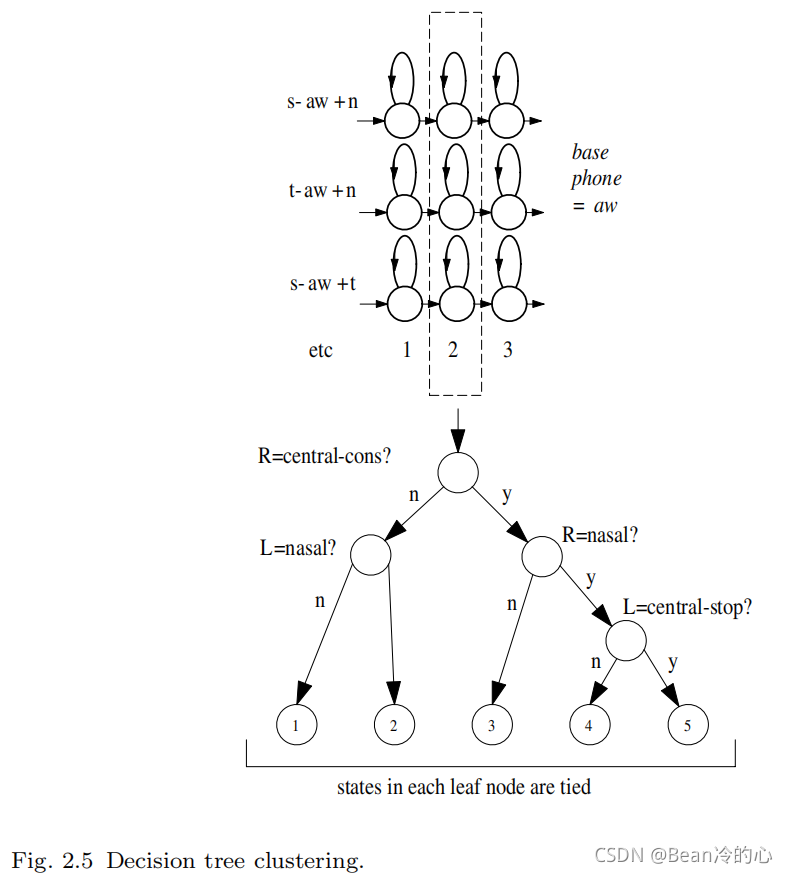
使用语音驱动的决策树进行状态划分有几个优点。特别是,可以很容易地合成训练数据中所需要但根本没有看到的逻辑模型。一个缺点是分区可能相当粗糙。该问题可以通过所谓“软捆绑”的方式来缓和。在这个方案中,一个后处理阶段将每个状态与它的一个或两个最近的邻居分组,并将它们所有的高斯分布集合起来。这样,在保持系统中高斯粒子总数不变的情况下,将单一高斯模型转换为混合高斯模型。
综上所述,现代语音识别器的核心声学模型通常由一组具有高斯输出分布的捆绑三态hmm组成。这个核心通常是通过以下步骤构建的:
- 创建一个平启动单音素集,其中每个基本音素是一个单声机单高斯HMM,其均值和协方差等于训练数据的均值和协方差。
- 使用 3 3 3次或 4 4 4次 E M EM EM迭代重新估计了高斯单音素的参数。
- 每个单独的高斯单音 q q q被克隆一次,对应训练数据中出现的每个不同的三音 x − q + y x - q + y x−q+y。
- 利用 E M EM EM重新估计训练数据三音素集合,并保存最后一次迭代的状态占用计数。
- 为每个基音素中的每个状态创建决策树,将训练数据三音素映射为较小的绑定状态三音子集,并使用 E M EM EM迭代重新估计。
最终的结果是所需的关联状态上下文相关的声学模型集。
2.3 N-gram语言模型
在公式 ( 2.2 ) (2.2) (2.2)中所需的单词序列 w = w 1 , . . . , w k w=w_1,...,w_k w=w1,...,wk的先验概率由公式 2.16 2.16 2.16给出:
P ( w ) = ∏ k = 1 K P ( w k ∣ w k − 1 , . . . , w 1 ) . ( 2.16 ) P(w)=\prod^K_{k=1}P(w_k|w_{k-1},...,w_1).\qquad(2.16) P(w)=k=1∏KP(wk∣wk−1,...,w1).(2.16)
对于大型词汇识别,调解词( conditioning word,不知道翻译的对不对…)的历史 ( 2.16 ) (2.16) (2.16)通常被截断为 N − 1 N−1 N−1个单词,形成 N − g r a m N-gram N−gram语言模型
P ( w ) = ∏ k = 1 K P ( w k ∣ w k − 1 , w k − 2 , . . . , w k − N + 1 ) ( 2.17 ) P(w)=\prod_{k=1}^KP(w_k|w_{k-1},w_{k-2},...,w_{k-N+1})\qquad(2.17) P(w)=k=1∏KP(wk∣wk−1,wk−2,...,wk−N+1)(2.17)
N N N的取值范围通常是 2 − 4 2-4 2−4。语言模型通常根据他的困惑度来评估的,也就是 H H H,其定义为
H = − lim K → ∞ 1 K log 2 ( P ( w 1 , . . . , w k − N + 1 ) ) ≈ − 1 K ∑ k = 1 K log 2 ( P ( w k ∣ w k − 1 , w k − 2 , . . . , w k − N + 1 ) ) , \begin{aligned} H&=-\lim_{K\rightarrow\infin}\frac{1}{K}\log_2(P(w_1,...,w_{k-N+1})) \\ &\approx - \frac{1}{K}\sum^K_{k=1}\log_2(P(w_k|w_{k-1},w_{k-2},...,w_{k-N+1})), \end{aligned} H=−K→∞limK1log2(P(w1,...,wk−N+1))≈−K1k=1∑Klog2(P(wk∣wk−1,wk−2,...,wk−N+1)),
其中近似用于具有有限长度单词序列的N-gram语言模型。 n n n元概率通过统计 n n n元出现次数来估计训练文本的 n n n元概率,形成最大似然 ( M L ) (ML) (ML)参数估计。例如,让 C ( w k − 2 w k − 1 w k ) C(w_{k−2}w_{k−1}w_k) C(wk−2wk−1wk)表示三个单词 w k − 2 w k − 1 w k w_{k−2}w_{k−1}w_k wk−2wk−1wk的出现次数,同样,对于 C ( w k − 2 w k − 1 ) C(w_{k−2}w_{k−1}) C(wk−2wk−1),
P ( w k ∣ w k − 1 , w k − 1 ) ≈ C ( w k − 2 w k − 1 w k ) C ( w k − 2 w k − 1 ) ( 2.18 ) P(w_k|w_{k-1},w_{k-1})\approx \frac{C(w_{k-2}w_{k-1}w_k)}{C(w_{k-2}w_{k-1})} \qquad(2.18) P(wk∣wk−1,wk−1)≈C(wk−2wk−1)C(wk−2wk−1wk)(2.18)
用这种简单的最大似然估计方式最大的问题是稀疏性。可以通过折扣和 b a c k i n g o f f backing\ off backing off方法来缓解这个问题。例如,使用所谓的卡茨平滑法。
P ( w k ∣ w k − 1 , w k − 2 ) = { d C ( w k − 2 w k − 1 w k ) C ( w k − 2 w k − 1 ) i f 0 < C < C ′ C ( w k − 2 w k − 1 w k ) C ( w k − 2 w k − 1 ) i f C > C ′ α ( w k − 1 , w k − 2 ) P ( w k ∣ w k − 1 ) o t h e r w i s e , ( 2.19 ) P(w_k|w_{k-1},w_{k-2})= \left\{ \begin{array}{rcl} d\frac{C(w_{k-2}w_{k-1}w_k)}{C(w_{k-2}w_{k-1})} & & {if 0 < C < C'} \\ \frac{C(w_{k-2}w_{k-1}w_k)}{C(w_{k-2}w_{k-1})} & & {if C>C'} \\ \alpha(w_{k-1,w_{k-2}})P(w_k|w_{k-1}) & & {otherwise}, \end{array} \right.\qquad(2.19) P(wk∣wk−1,wk−2)=⎩⎪⎨⎪⎧dC(wk−2wk−1)C(wk−2wk−1wk)C(wk−2wk−1)C(wk−2wk−1wk)α(wk−1,wk−2)P(wk∣wk−1)if0<C<C′ifC>C′otherwise,(2.19)
其中 C ′ C' C′是计数阈值, C C C是 C ( w k − 2 w k − 1 w k ) C(w_{k-2}w_{k-1}w_k) C(wk−2wk−1wk)的缩写, d d d是一个折扣系数, α \alpha α是标准化常数。因此当 N N N元数超过某个阈值时,使用最大似然估计法。当计数较小时,使用相同的最大似然法估计,但略有折扣。然后,折现的概率质量被分配到看不见的 N − g r a m N-gram N−gram中,这些 N − g r a m N-gram N−gram被相应的二元图的加权版本所近似。这个想法可以递归地应用于根据一组 b a c k − o f f back-off back−off权并且估计任何稀疏 N − g r a m − ( N − 1 ) N-gram-(N−1) N−gram−(N−1)。折扣系数基于图灵-古德估计 d = ( r + 1 ) n r + 1 / r n r d = (r +1)n_{r+1}/rn_r d=(r+1)nr+1/rnr, n r n_r nr是训练数据中恰好出现 r r r次的 N − g r a m N-gram N−gram数。该方法有很多变体,例如,当训练数据非常稀疏时, K n e s e r − N e y Kneser-Ney Kneser−Ney平滑法有奇效。
鲁棒语言模型估计的另一种方法是使用基于类的模型,其中每个单词 w k w_k wk都有一个对应的类 c k c_k ck。那么:
P ( w ) = ∏ k = 1 K P ( w k ∣ c k ) p ( c k ∣ c k − 1 , . . . , c k − N + 1 ) . ( 2.20 ) P(w)=\prod^K_{k=1}P(w_k|c_k)p(c_k|c_{k-1},...,c_{k-N+1}).\qquad(2.20) P(w)=k=1∏KP(wk∣ck)p(ck∣ck−1,...,ck−N+1).(2.20)
至于基于单词的模型,使用 M L ML ML估计类 N − g r a m N-gram N−gram概率,但由于类少得多(通常只有几百个)数据稀疏问题就小得多了。选择类本身是为了优化假定双元模型的训练集的可能性。可以看出,当一个词从一个类移到另一个类时,困惑的变化只取决于相对较少数量的双元模型。因此,可以实现一种迭代算法,反复扫描词汇表,测试每个单词,看看把它移到其他类是否会增加似然。
在实践中,我们发现,对于规模合理的训练集(通常远大于 1 0 7 10^7 107),针对大型词汇应用程序的有效语言模型由一个平滑的基于单词的 3 3 3或 4 g r a m 4gram 4gram语言模型和一个基于类的三元组语言模型组成。
2.4 加码器和Lattice生成
正如在本节的介绍中提到的,最有可能的单词序列 w ^ \hat{w} w^给出了一个特征向量序列 Y 1 : T Y_{1:T} Y1:T是通过搜索最可能产生观测数据 Y 1 : T Y_{1:T} Y1:T的序列中所有可能的单词序列所产生的所有可能的状态序列来得到的。动态规划是解决这一问题的有效方法。让 ϕ t ( j ) = max θ p ( Y 1 : t , θ t = s j ; λ ) \phi_t^{(j)} = \max_\theta{p(Y_{1:t}, \theta_t = s_j;\lambda)} ϕt(j)=maxθp(Y1:t,θt=sj;λ),即,观察的最大概率部分序列 Y 1 : t Y_{1:t} Y1:t然后在状态如果入在时间 t t t给定模型参数 λ \lambda λ。使用Viterbi算法可以有效地计算该概率。
ϕ t ( j ) = max i { ϕ t − 1 ( i ) a i j } b j ( y t ) . ( 2.21 ) \phi_t^{(j)}=\max_i \lbrace \phi_{t-1}^{(i)}a_{ij} \rbrace b_j(y_t).\qquad(2.21) ϕt(j)=imax{ϕt−1(i)aij}bj(yt).(2.21)
初始化的方法是将 ϕ 0 ( j ) \phi_0^{(j)} ϕ0(j)设置为1,表示初始的、非发射的、进入状态,并将所有其他状态设置为0。最可能的单词序列的概率由 max j { ϕ T ( j ) } \max_j\lbrace \phi_T^{(j)} \rbrace maxj{ϕT(j)}给出,如果记录每个最大化决策,回溯将产生所需的最佳匹配状态/单词序列。
在实践中, V i t e r b i Viterbi Viterbi算法的直接实现连续语音会变得难以管理的复杂,因为模型的拓扑结构、语言模型的约束和需要全部被考虑到计算中。 N − g r a m N-gram N−gram语言模型和交叉词三音素上下文尤其有问题,因为它们极大地扩展了搜索空间。为了解决这个问题,已经发展了许多不同的体系结构方法。对于 V i t e r b Viterb Viterb译码,搜索空间可以通过并行维持多个假设来限制,也可以随着搜索的进行而动态扩展。或者,可以采用一种完全不同的方法,即用深度优先搜索取代维特比算法的宽度优先方法。这就产生了一类称为堆栈解码器的识别器。这样非常高效,但是,因为它们必须比较不同长度的假设,它们的运行时搜索特性很难控制。最后,加权有限状态传感器技术的最新进展使所有所需的信息(声学模型、发音、语言模型概率等)能够集成到一个非常大但高度优化的网络中。这种方法既灵活又高效,因此对研究和实际应用都非常有用。
虽然解码器的设计主要是为了找到 ( 2.21 ) (2.21) (2.21)的解,但在实践中,不仅要生成最有可能的假设,而且要生成 N − b e s t N-best N−best的假设集,这是相对简单的。 N N N通常在 100 − 1000 100-1000 100−1000范围内。这是非常有用的,因为它允许多次传递数据,而无需从头开始重复求解 ( 2.21 ) (2.21) (2.21)的计算开销。用于存储这些假设的一个紧凑而有效的结构是 w o r d l a t t i c e word\ lattice word lattice。
w o r d l a t t i c e word\ lattice word lattice由一组表示时间点的节点和一组表示单词假设的跨越弧组成。如图 2.6 2.6 2.6的 p a r t ( a ) part (a) part(a)所示。除了图中所示的单词的 I D ID ID外,每个弧线还可以携带分数信息,如声学和语言模型分数。
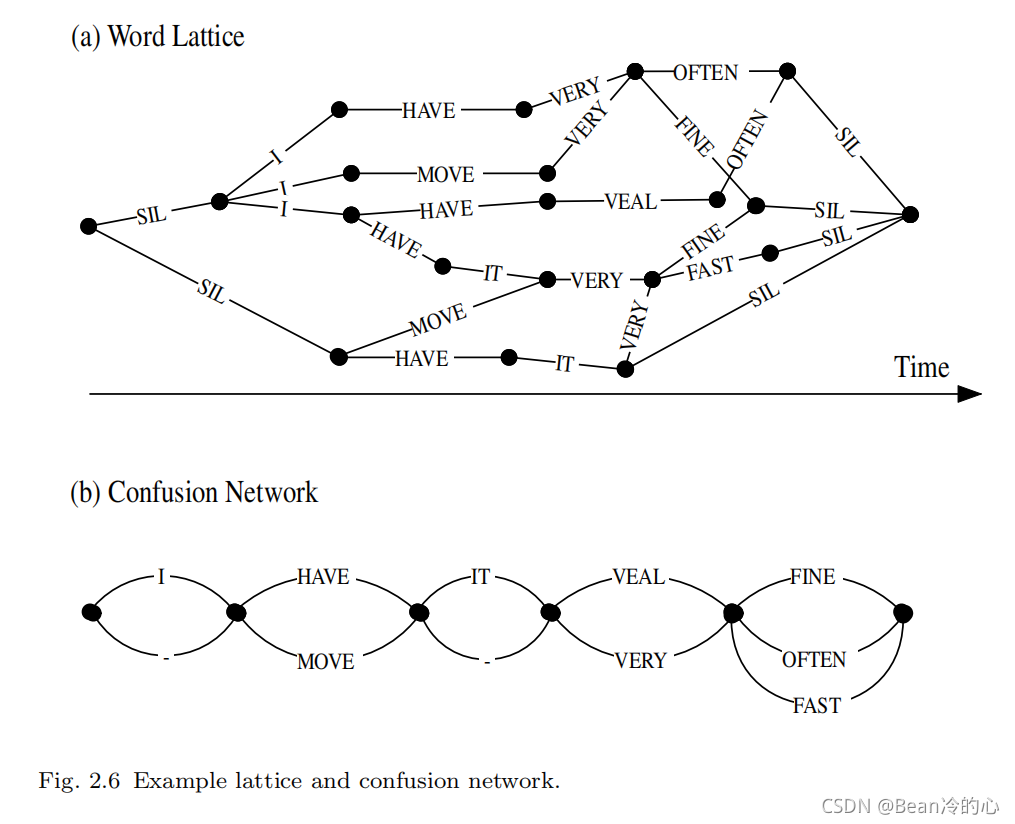
l a t t i c e lattice lattice是非常灵活的。例如,它们可以通过使用它们作为输入识别网络来进行再评分,并且它们可以被扩展以允许通过更高阶的语言模型进行再打分。它们也可以被压缩成一种非常有效的表示,称为混淆网络 ( c o n f u s i o n n e t w o r k ) (confusion\ network) (confusion network)。这在图 2.6 2.6 2.6的 p a r t ( b ) part(b) part(b)中进行了说明, " − " "-" "−"弧标签表示空转换。在混乱网络中,节点不再对应离散的时间点,而是简单地执行单词序列约束。因此,混淆网络中的平行圆弧并不一定对应于同一声段。然而,假设大部分时间重叠足以使平行的弧被认为是相互竞争的假设。混沌网络具有这样的性质:对于通过原始 l a t t i c e lattice lattice的每一条路径,都存在通过混沌网络的相应路径。混淆网络的每个弧携带相应的词的后验概率 w w w。这是通过求在 w w w的连接概率来计算的, l a t t i c e lattice lattice使用 f o r w a r d − b a c k w a r d forward-backward forward−backward过程,对出现的所有 w w w求和然后归一化,在混乱网络中所有竞争的词弧之和为 1 1 1。混淆网络可用于最小化字误译码。
字数太多,后续我准备另分两篇文章写出来。
这篇关于(一)《The Application of Hidden Markov Models in Speech Recognition》论文学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









