本文主要是介绍Python3 爬取携程网[1]: 根据好评优先顺序,获取北京五星级酒店列表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 项目目的
俗话说,“巧妇难为无米之炊”。在数据科学道路上,数据获取是数据利用、分析等后续工作中的重要前提。虽然说,如今有许多开源的数据集,但是,锻炼自己从浩如烟海的网络中获取原始数据的能力,对于培养数据科学的基础技能是十分重要的。
2. 需求分析
本文目的是根据好评优先顺序,爬取携程网上的北京五星级酒店列表。
3. 实验环境
- 语言:Python 3.7
- 操作系统:MacOS
- 编程IDE:Pycharm
- 浏览器:Chrome
4. 具体实现
这一部分是本文的重点,将按照基本爬虫思路进行记录。
4.1 分析页面
对于一个学生而言,拿到一道题,首先要做的工作是熟读题目、进行分析,而不是马上下笔答题。同理,爬虫之前,认真分析要爬取的页面,会使得工作事半功倍。
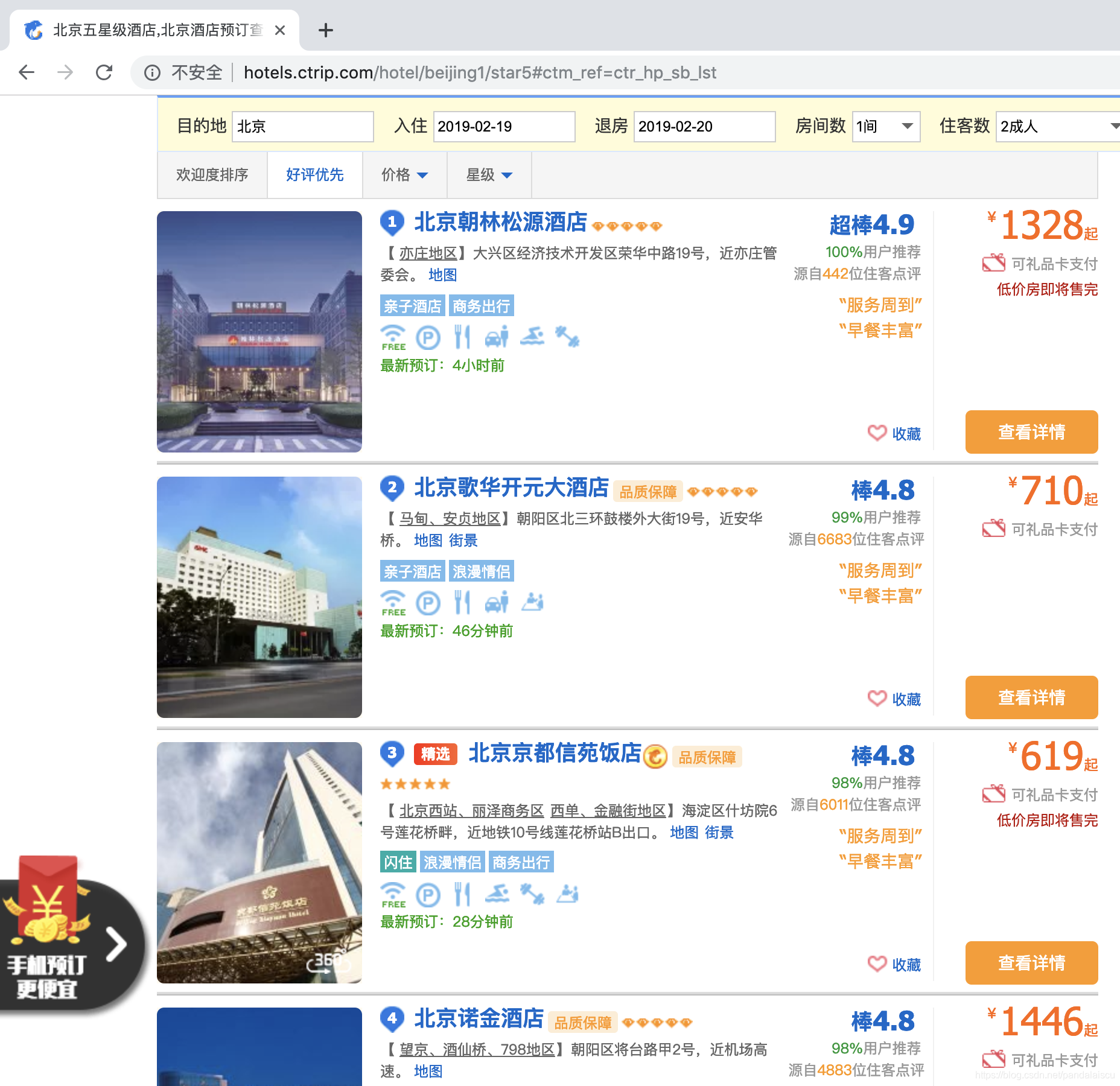
- 打开携程网.
在页面上选择:
- 城市:北京
- 入住日期:2019-02-19
- 退房日期:2019-02-20
- 房间数:1间
- 住客数:2人
- 酒店级别:五星级/豪华
如图1所示:

- 分析北京五星级酒店页面
点击图1中的“搜索”按钮,在酒店列表页面中选择好评优先排序方式。如图2所示。
- 寻找页面接口
因为每一个酒店都是可点击跳转的,即可交互,所以,为动态页面。静态页面可以直接通过页面源码,实现获取信息;动态页面需要找寻接口,然后从其接口的源码中获取信息。
在页面空白处,点击右键,选择“检查”,可以看到页面的源码。找寻接口,必须选中第一行的“Network”选项。
点击页面刷新按钮,即可在Filter中输入“Hotel”,选择“XHR”,即可找到页面接口。
这篇关于Python3 爬取携程网[1]: 根据好评优先顺序,获取北京五星级酒店列表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




