本文主要是介绍MakeSense中文版使用手册【图像标注神器】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
捕获图像以收集数据很容易; 接下来的事情充满挑战。 图像标注或标记是机器学习和计算机视觉任务中数据预处理中最耗时和劳动密集型的步骤之一。
可以使用makesense来标注你的图像,它提供了一个简单直观的界面来标记图像中的对象。 虽然 VIA(VGG 图像注释器)是一种替代方案,但 makesense为图像标注任务提供了更简单、更简化的体验。
1、Makesense快速上手
首先访问网站makesense中文版,然后单击右下角的“开始”。

你将被带到一个新窗口,可以单击屏幕区域以打开文件对话框选择图片集,或者直接从计算机中拖拽图像:

拖动或上传图像后,单击“目标检测”:

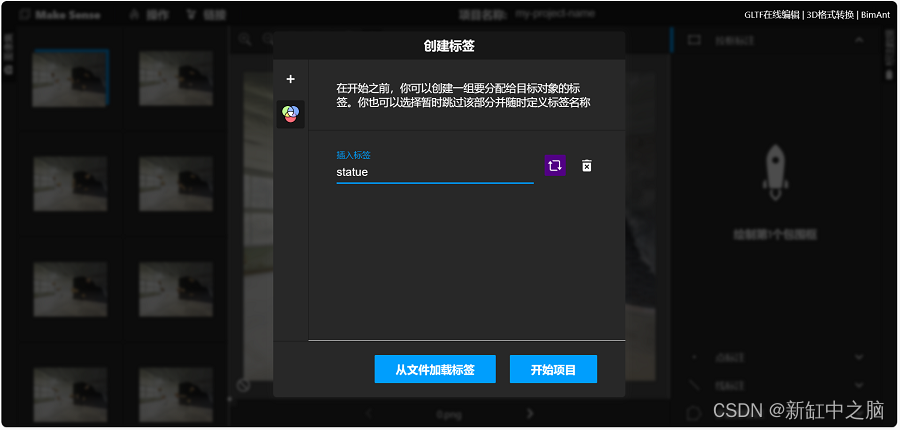
系统会要求你定义标签。 可以添加一个或多个,具体取决于要定义的类的数量。 就我而言,我只是添加一个标签名称,即 statue,如下图所示:
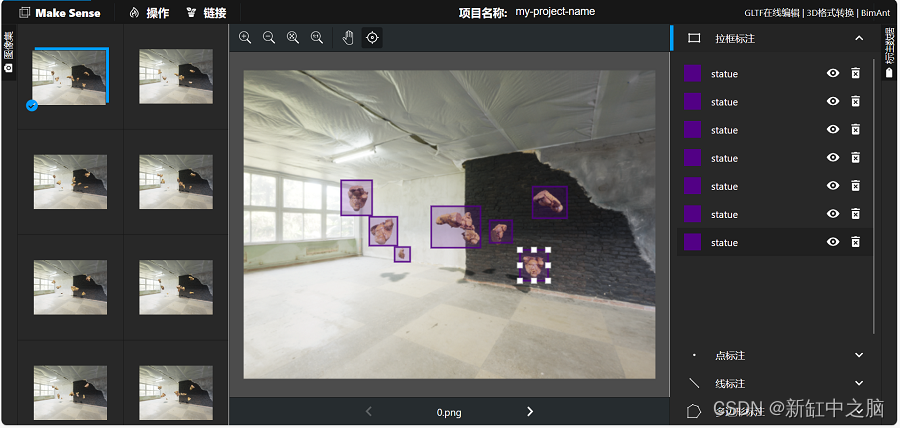
单击左侧要标注的图像。 然后,从矩形、点、线和多边形中选择标注形状。 一般来说,YOLO使用矩形包围框,如下图所示:
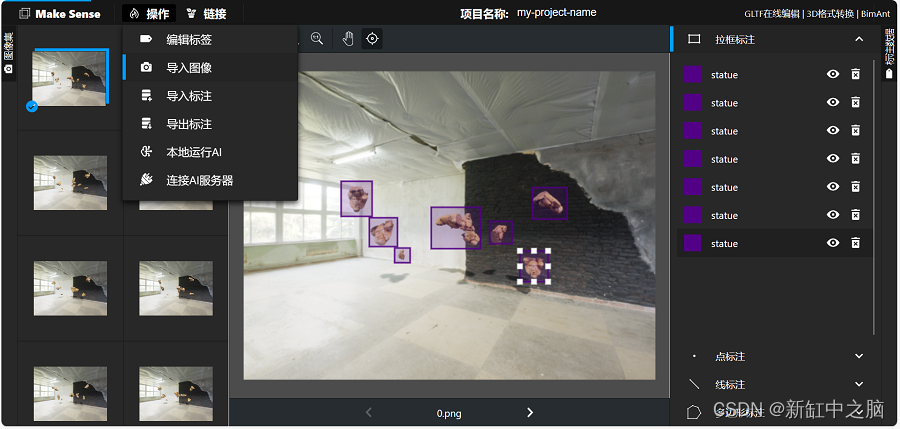
可以单击左上角“操作”菜单下的“导入图像”将更多图片导入到现有项目中:
带有 + 和 - 符号的放大图标用于放大和缩小。 手形图标用于在缩放时拖动图像; 手形图标右边的图标是光标十字线图标,打开该图标后,光标的外观将变为十字线。 启用此模式后,光标的形状会变为十字线,可以在屏幕上移动光标以定位并选择某个元素,例如按钮、链接或图像。

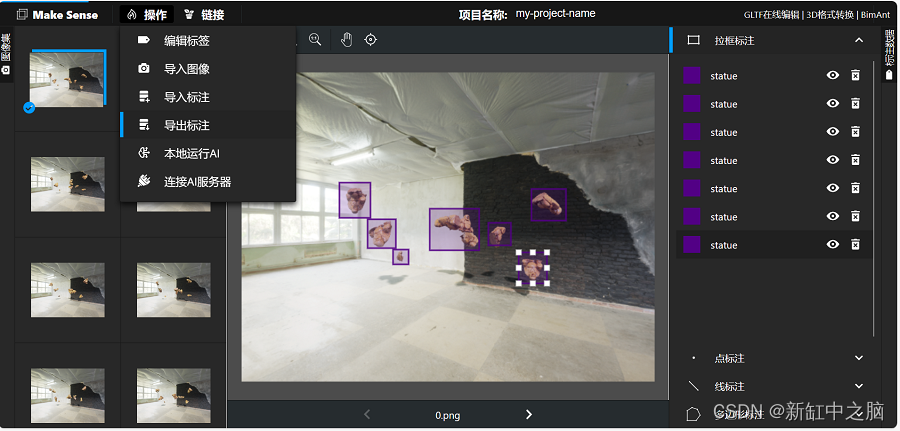
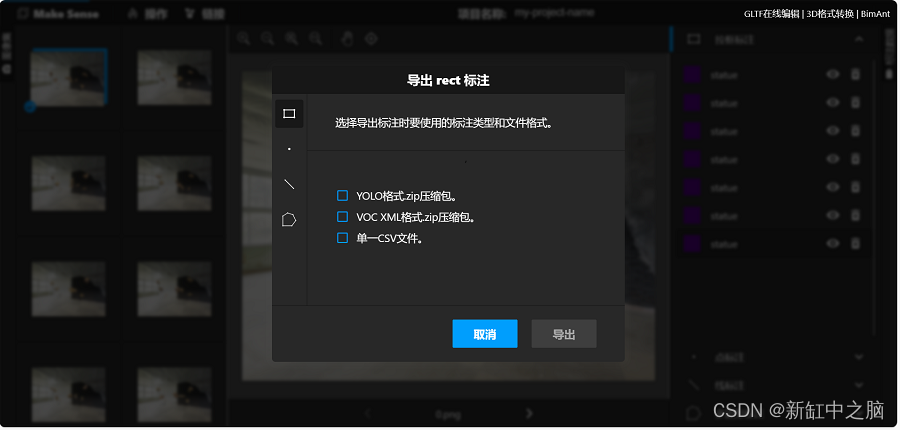
可以在标注完成后通过单击“操作”选项卡下的“导出标注”来导出标注文件:
可以选择不同的格式(VGG、COCO等)来导出标注文件,如下所示:
2、Makesense快捷键
| 功能 | 上下文 | Mac | Windows / Linux |
|---|---|---|---|
| 多边形自动完成 | 编辑器 | Enter | Enter |
| 取消多边形绘制 | 编辑器 | Escape | Escape |
| 删除当前选中标签 | 编辑器 | Backspace | Delete |
| 加载上一个图像 | 编辑器 | ⌥ + Left | Ctrl + Left |
| 加载下一个图像 | Editor | ⌥ + Right | Ctrl + Right |
| 放大图像 | Editor | ⌥ + + | Ctrl + + |
| 缩小图像 | 编辑器 | ⌥ + - | Ctrl + - |
| 移动图像 | 编辑器 | Up / Down / Left / Right | Up / Down / Left / Right |
| 选择标签 | 编辑器 | ⌥ + 0-9 | Ctrl + 0-9 |
| 退出弹出框 | 弹出框 | Escape | Escape |
3、导入格式支持
| CSV | YOLO | VOC | XML | VGG JSON | COCO JSON | PIXEL MASK |
|---|---|---|---|---|---|---|
| 点标注 | ☐ | ✗ | ☐ | ☐ | ☐ | ✗ |
| 线标注 | ☐ | ✗ | ✗ | ✗ | ✗ | ✗ |
| 框标注 | ☐ | ✓ | ☐ | ☐ | ✓ | ✗ |
| 多边形标注 | ☐ | ✗ | ☐ | ☐ | ✓ | ☐ |
| 标签 | ☐ | ✗ | ✗ | ✗ | ✗ | ✗ |
上面表格维makesense支持的导入格式矩阵,其中:
- ✓ - 支持的格式
- ☐ - 尚不支持的格式
- ✗ - 格式对于给定的标签类型没有意义
4、导出格式支持
| CSV | YOLO | VOC XML | VGG JSON | COCO JSON | PIXEL MASK |
|---|---|---|---|---|---|
| 点标注 | ✓ | ✗ | ☐ | ☐ | ☐ |
| 线标注 | ✓ | ✗ | ✗ | ✗ | ✗ |
| 框标注 | ✓ | ✓ | ✓ | ☐ | ☐ |
| 多边形标注 | ☐ | ✗ | ☐ | ✓ | ✓ |
| 标签 | ✓ | ✗ | ✗ | ✗ | ✗ |
上面表格维makesense支持的标签导出格式矩阵,其中:
- ✓ - 支持的格式
- ☐ - 尚不支持的格式
- ✗ - 格式对于给定的标签类型没有意义
原文链接:MakeSense中文版手册 — BimAnt
这篇关于MakeSense中文版使用手册【图像标注神器】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







